
Since the boom of Large Language Models (LLMs) and surge of AI use cases in organisations, understanding how to protect your AI systems and applications is key to maintaining the security of your ecosystem and optimising the use for the business. MITRE, the organisation famous for the ATT&CK framework, a taxonomy for adversarial actions widely used by the Security Operations Centre (SOC) and threat intelligence teams, has released a framework called MITRE ATLAS. The MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems) is a knowledge base of adversary tactics and techniques against AI-enabled systems. It can be used as a tool to categorise attacks or threats and provides a system to consistently assess threats.
However, the AI threat landscape is complex, and it’s not always clear what specific teams need to do to protect an AI system. The MITRE ATLAS framework has 56 techniques available to adversaries, with mitigation being made more complex due to need to apply controls across the kill chain. Teams will require controls or mitigating measures to implement against multiple phases from reconnaissance to exfiltration and impact assessment.

Fig 1. MITRE ATLAS Kill Chain.
This complexity has led many of our clients to ask, ‘I’m the head of Identity and Access Management what do I need to know, and more importantly what do I need to do above and beyond what I’m currently doing?’.
We’ve broken down MITRE ATLAS to understand what types of controls different teams need to consider mitigating against each technique. This allows us to assess whether existing controls are sufficient and whether new controls need to be developed and implemented to secure AI systems or applications. We estimate that to assess the threat’s posed against AI systems, mitigating controls consist of 70% existing controls, and 30% new controls.
To help articulate, we’ve broken it down into three categories:
- Green domains: existing controls will cover some threats posed by AI. There may be some nuance, but the principle of the control is the same and no material adjustments need to be made.
- Yellow domains: controls will require some adaptation to confidently cover the threat posed by AI.
- Red domains: completely new controls need to be developed and implemented.
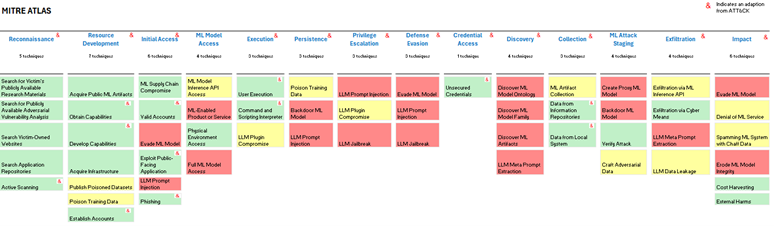
Fig 2. RAG analysis of mitigating controls for MITRE ATLAS techniques.
Green domains
Green domains are those for which existing controls will cover the risk. Three domains fall into this category: Identity & Access Management, Network Security, and Physical Security.
For IAM teams, the core principle remains ensuring the right people have access to the right things. For an AI application there is a slight nuance, as we need to consider the application itself (i.e., who can use it, who can access the source code and environment), the data used to train the model, and the input data that is used to create the output.
Network Detection and Response flags unusual activity on the network, for example the location of the request or exfiltration of large amounts of data. The network security team needs to remain vigilant and raise alerts for the same type of activity for an AI application, although it may indicate a different type of attack. Many requests to a traditional application may be indicative of a brute force attack, whereas for an AI application, it could be cost harvesting, a technique where attackers send useless queries to increase the cost of running the application, it can be mitigated through limiting the number of model queries. It is important to note that detection on the application level, and for forensics on an AI system it more complicated than a traditional application, however at the network level, the process remains the same. As with traditional applications, APIs that are integrated with the model need to be secured to ensure network interactions with public applications are secure.
Physical Security controls remain the same; secure who has physical access to key infrastructure.
Yellow domains
Controls and mitigating measures that fall into the yellow domains will follow the same principles as for traditional software but will need to be adapted to secure against the threat posed by AI. The teams that fall into this category are Education & Awareness, Resilience, and Security Operations Centre & Threat Intelligence.
For awareness teams, the techniques will remain the same, awareness campaigns, phishing tests, etc. However, they need to ensure they are updated to sufficiently reflect the new threat. For example, including deepfakes in phishing tests and ensuring new threats are covered in specific training for development teams.
While there are limited changes for the resilience team to consider, there will be some adjustments to existing processes. If an IBS is hosted or reliant on an application that utilises AI, then any testing scenarios need to include AI-specific threats.
Impacts from an attack on AI need to be added to any crisis/ incident management documentation and communication guidelines updated to reflect the possible outcomes of an AI attack, for example unexpected or offensive outputs from a customer facing Chatbot.
For a Security Operations Centre or threat intelligence team, the principle behind the controls is the same: gathering intelligence about threats and vulnerabilities and monitoring the systems for unexpected traffic or behaviour, with the addition of AI-specific threats. For AI applications, additional layers and categories of monitoring are needed to monitor for information about the model online and what other information attackers may be able to utilise to leverage access to the model. This is especially pertinent if the model is based on open-source software, for instance ChatGPT.
Red domains
Controls and techniques that fall into the red domains are totally new controls that need to be introduced to face the new threats of AI. Many sit within the data and application security team’s remit. It’s important to note that we are not referencing the data protection teams, who are largely dealing with the same issues of GDPR etc., but rather the team responsible for the security of the data, which may be the same team. The application security team have many controls within this domain, indicating the importance of building AI-enabled applications according to secure-by-design principles. There are also some AI specific controls that do not fit within existing teams. The team responsible for them is to be determined by the individual organisation, but at our more mature clients we see these owned by an AI Centre of Excellence.
Data security teams are crucial in ensuring that the training and input datasets have not been poisoned and that the data is free from bias, is trustworthy, and is reliable. These controls may be similar to existing techniques but there are nuances to consider, for instance, poisoning checks will be very similar to data quality checks. Quality data is the foundational component of a secure AI application, so it is key for teams to go beyond standard sanitization or filtering. There are many ways to do this, for example utilising an additional layer of AI to analyse the training or input data for malicious inputs. Alternatively, data tokenisation can have dual benefits: it can reduce the risk of exposing potentially private data during model training or inference and as tokenised data is in its raw form (often ACSII or Unicode characters) it becomes more difficult for attackers to introduce poisoned data into the system. Tokenisation algorithms such as Byte Pair Encoding (BPE) was used by OpenAI when pretraining the GPT model to tokenise large datasets. It is key to remember that we are not just securing the data as an artifact but assessing its content and how it could be utilised with malicious intent to create specific outputs.
Beyond securing the data as an input, data security measures should be implemented throughout the application lifecycle; when designing and building an application, while processing the inputs, and the output of the model.
Where the application is using a continuously learning model, controls around data security need to be implemented continuously while the application is running to ensure the model remains robust. Securing the training and input data provides a secure foundation, but to add an additional layer of security, continuous AI red teaming should be rolled out. This consists of continuously testing a model against adversarial inputs while it’s running. A further layer of security can be implemented by putting parameter guardrails on the type of output the model can produce.
As well as continuously testing to identify vulnerabilities in the model, application security teams must ensure the system is built according to secure-by-design principles with specific AI measures put in place. For example, when building an application internally, ensuring security requirements are applied to all components. This includes traditional software components such as the host infrastructure and AI-specific components including model configuration, training data, or, if utilising open-source models, testing the reliability of the code to identify potential security weaknesses, design flaws and alignment with secure coding standards. Application security teams need to ensure no backdoors can be built into the model. For instance, systems can be modified to enable attackers to get a predetermined output from a model using a specific trigger.
There are some application security controls that will remain the same but with an AI twist; monitoring for public vulnerabilities on software as usual, and on the model, if it’s open source.
Training for developers must continue, and the message will remain the same with some adjustments – as with traditional software, where you do not publish the version of the software that you are running, you shouldn’t publish the model or input parameters you’re using. Developers should follow the existing and updated security guidelines, understand the new threats, and build accordingly.
AI applications bring their own inherent risks that need specific controls. These need to be implemented across the lifecycle of the application to ensure it remains secure throughout. These are new controls that do not sit within an existing team. At our more mature clients, we see them managed by an AI Centre of Excellence, however for some they are the responsibility of the security team but executed by data scientists.
Specific controls need to be used in the build of the model, to ensure the model design is appropriate, the source code is secure, the learning techniques used are secure and free from bias, and there are parameters around the input and output of the model. For example, techniques such as bagging can be used to improve the resiliency of the model. This involves splitting the model into several independent sub-models during the learning phase, with the main model choosing the most frequent predictions from the sub-models. If a sub-model is poisoned, the other sub-models will compensate. Utilising techniques such as Trigger Reconstruction during the build phase can also help protect against data poisoning attacks. Trigger Reconstruction identifies events in a data stream, like looking for a needle in a haystack. For predictive models, it detects backdoors by analysing the results of a model, its architecture, and its training data. The most advanced triggers detect, understand, and mitigate backdoors by identifying a potential pain point in a deep neural network, analysing the data path to detect unusual prediction triggers (systematically erroneous results, overly rapid decision times, etc), assess back door activation by studying the behaviour of suspect data, and respond to the backdoor (filtering of problematic neurons, etc), effectively ‘closing’ it.
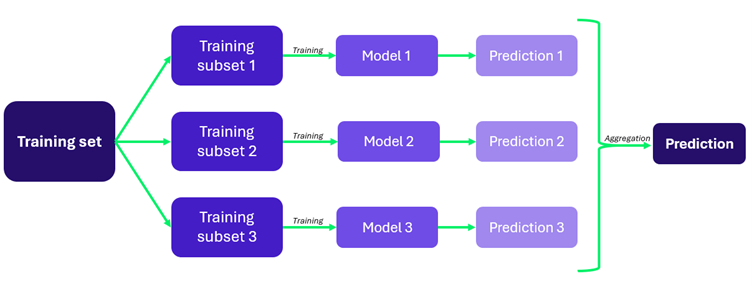
Fig 3. Bagging, a build technique for improving the reliability and accuracy of a model.
While running, it is key to ensure that the data being fed into the model is secure and not poisoned. This can be achieved through adding an additional layer of AI that has been trained to detect malicious data to filter and supervise of all the data inputs and detect if there is an adversarial attack.
Teams need oversight about how the model fits into the wider AI security ecosystem during the build, run, and test phases. Understanding the availability of information about the model, any new vulnerabilities, and new specific AI threats will allow them to sufficiently patch the model and conduct the appropriate tests. Especially if the model is a continuous learning model, and designed to adapt to new inputs, it needs to be tested regularly. This can be achieved in many ways, including a meta-vulnerability scan of the model, where the model’s behaviour can be modelled by formal specifications and analysed on the bases of previously identified compromise scenarios. Further adversarial learning techniques (or equivalent) should be used to ensure the continued reliability of the models.
Conclusion
We have demonstrated that despite the new threats that AI poses, existing security measures continue to provide the foundation of a secure ecosystem. Across the whole CISO function, we see a balance between existing controls that will protect AI applications in the same way they protect traditional software and the domains that need to adapt or add to what they are currently doing to protect against new threats.
From our analysis, we can conclude that to fully secure your wider ecosystem, including AI applications, your controls will be 70% existing ones, and 30% new.

