
Microsoft has announced that in Q2 2024 “more than half of Fortune 500 companies will be using Azure OpenAI”. [1] At the same time, AWS is offering Bedrock [2], a direct competitor to Azure OpenAI.
This type of platform can be used to create applications based on generative AI models such as LLMs (GTP-3.5, Mistral, etc.).
Nevertheless, the adoption of this technology is not without risk: from virtual assistants criticizing their companies [3] to data leaks [4]; there is no shortage of examples.
To support the many deployments currently underway, you need to think quickly about your security, particularly when sensitive data is being used. In this article, we take a look at the risks and mitigations associated with using these platforms.
Which model is right for you?
Three types of generative AI can be used to create an application. The difference lies in the precision of the answers provided:
- Simple: generic AI model (GPT-4, Mistral, etc.) plugged in as such, with a user interface. It is an internal GPT.
- Boosted: generic AI model that leverages the company’s data, for example via RAG (Retrieval Augmented Generation). These are specialized companions for a particular use, HR GPT, Operations GPT, CISO GPT…).
- Specialized: the AI model retrained for a particular use. For example, India has retrained Llama 3 for its 22 official languages to make it a specialized translator.
All three deployment methods entail risks. We will begin by describing the different modes. We will then look at the risks, and the associated mitigations.
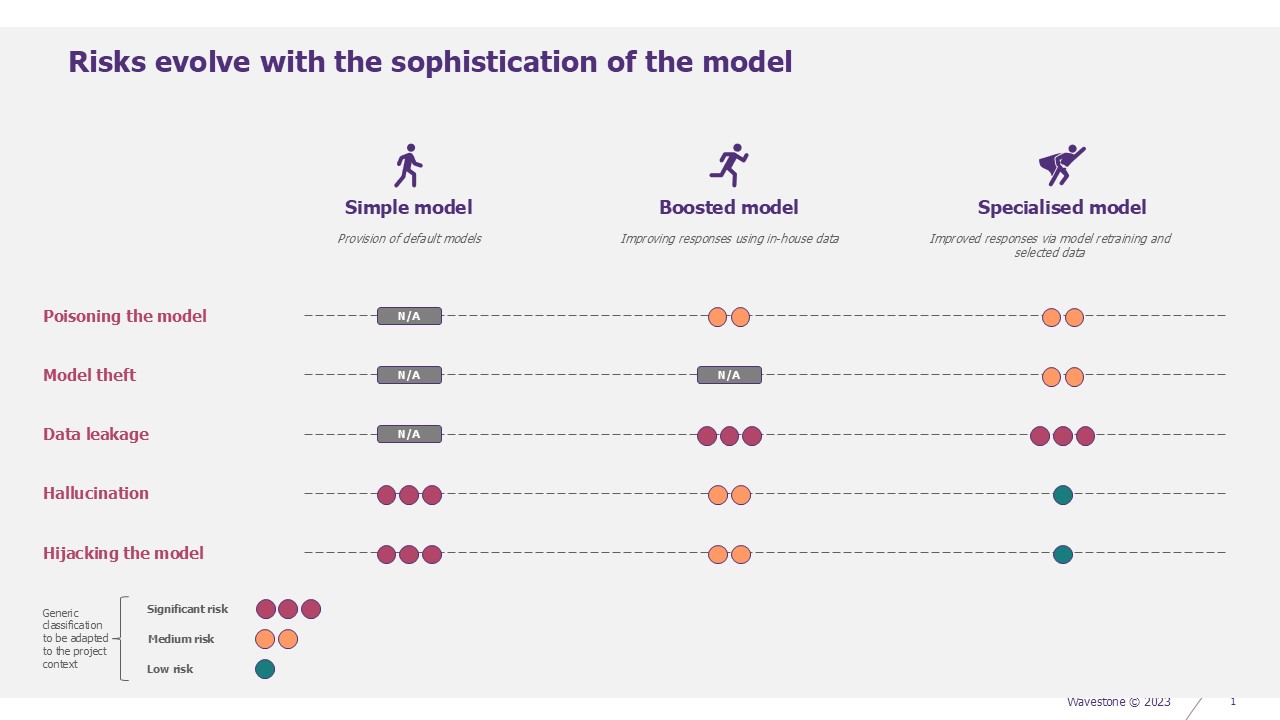
Risks and models
Simple model
This model is the simplest to deploy. It allows users to interact with the AI models proposed by the platforms. It simplifies the integration of sending prompts and receiving responses in an application. It is an internal ChatGPT, with the advantage of limiting the leakage of sensitive data inserted into a prompt, unlike the web version. Also, in this case, exchanges with users are not used to re-train and improve the model. Your data is protected. The Cloud platforms offered by Azure, AWS or GCP enable these solutions to be deployed rapidly.
Examples of use: text summary, development assistant.
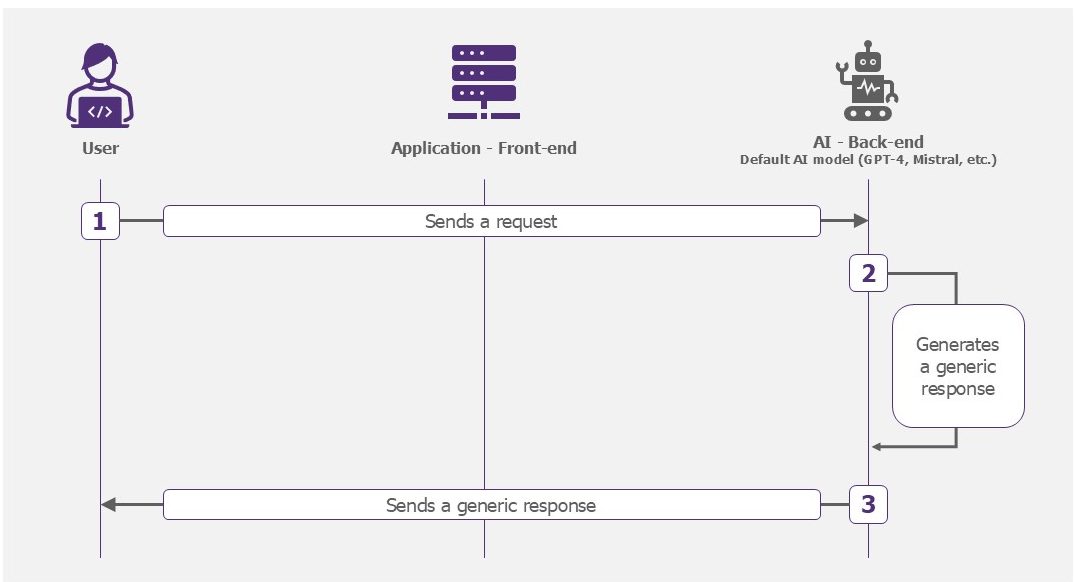
How the simple model works
Boosted model
This model remains generic, but will have access to selected company data. The AI could, for example, consult the group’s PSSI to provide the password policy.
Examples of use: enterprise chatbot, data analysis.
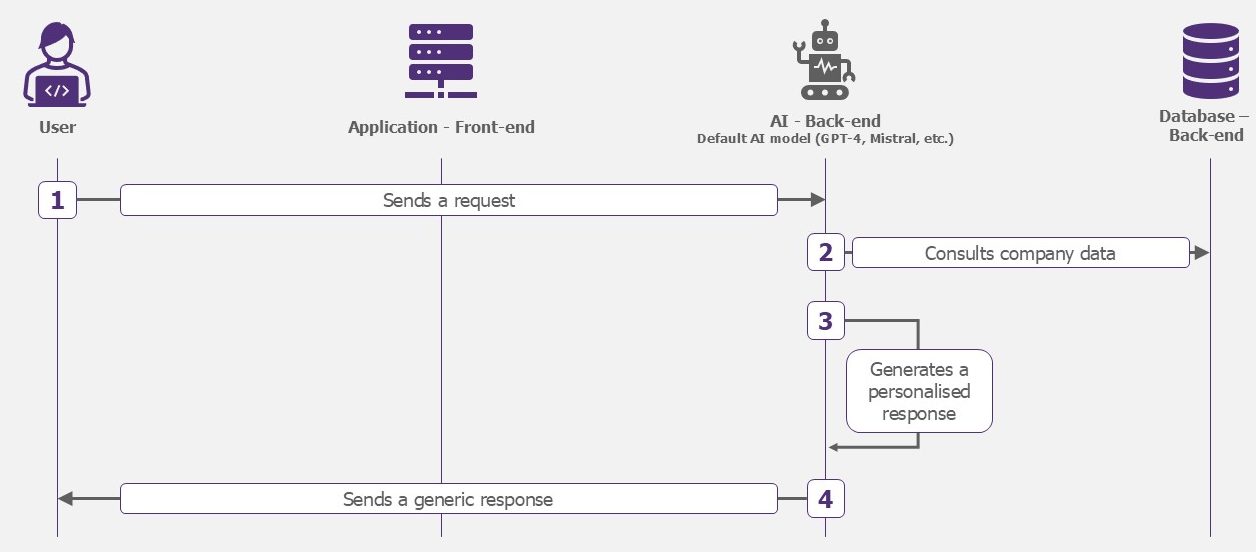
How the boosted model works
Specialized model
The application is no longer based on a generic model (GPT-4, Mistral, etc.). Before using it, you will need to train your own model on your company’s data. It will always be able to consult the company’s data and will have a better understanding of it to generate its response.
Examples of applications: fault detection on a production line, medical diagnostics.
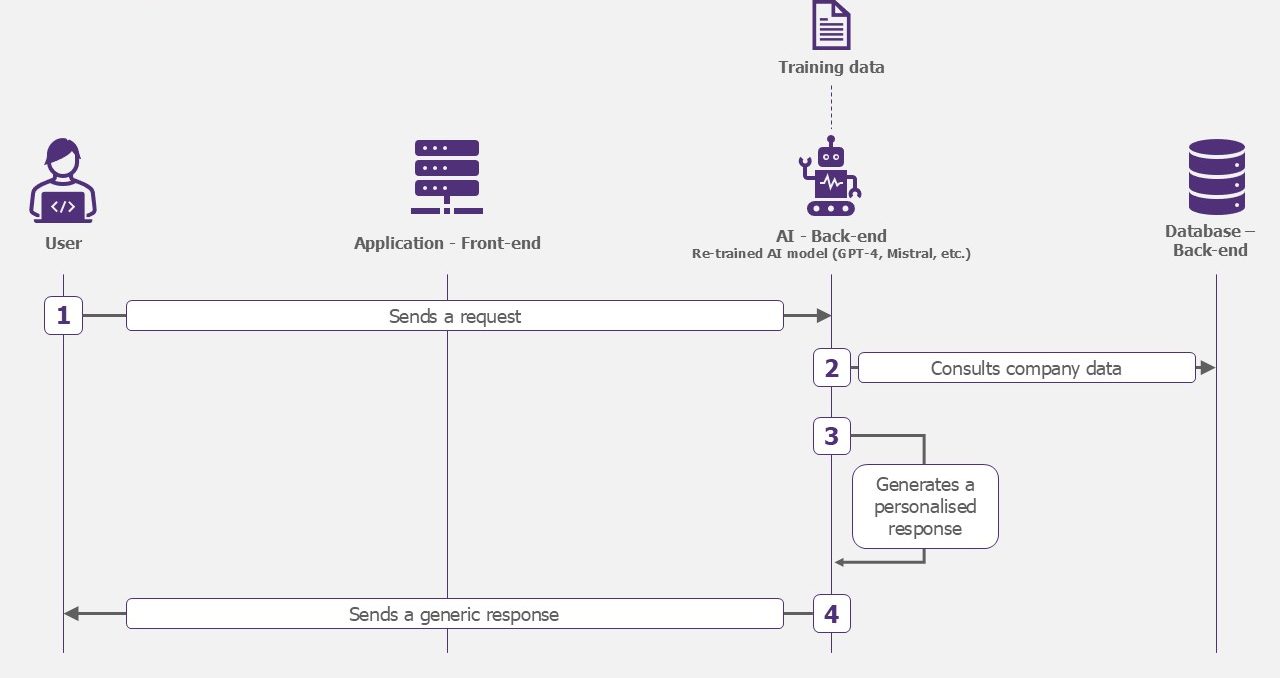
How the specialized model works
What risks are you exposed to?
Regardless of the model selected, there are a number of transversal or specific risks. It is important to take these into account to ensure that the solution is securely integrated.
Hijacking the model
AI models are exposed to the risk of misuse. Imagine a scenario where someone uses this technology to generate harmful content. This could lead to real consequences such as the propagation of toxic content. One known attack for this purpose is Prompt Injection [5].
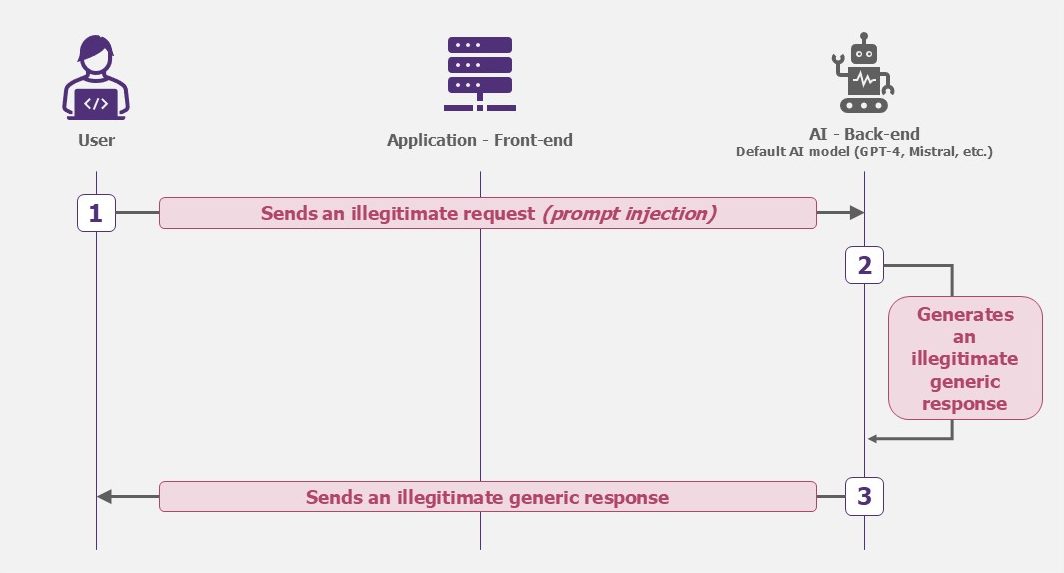
Example – Model hijacking (Prompt Injection)
Hallucination
When AI asserts information that is false, it hallucinates. Think of it as “daydreaming”: if it doesn’t have the answer, it will “invent” things to fill the void. This can be particularly problematic in situations where accuracy is crucial: generating reports, making decisions, etc. Users could unknowingly spread this false information, or make bad decisions.
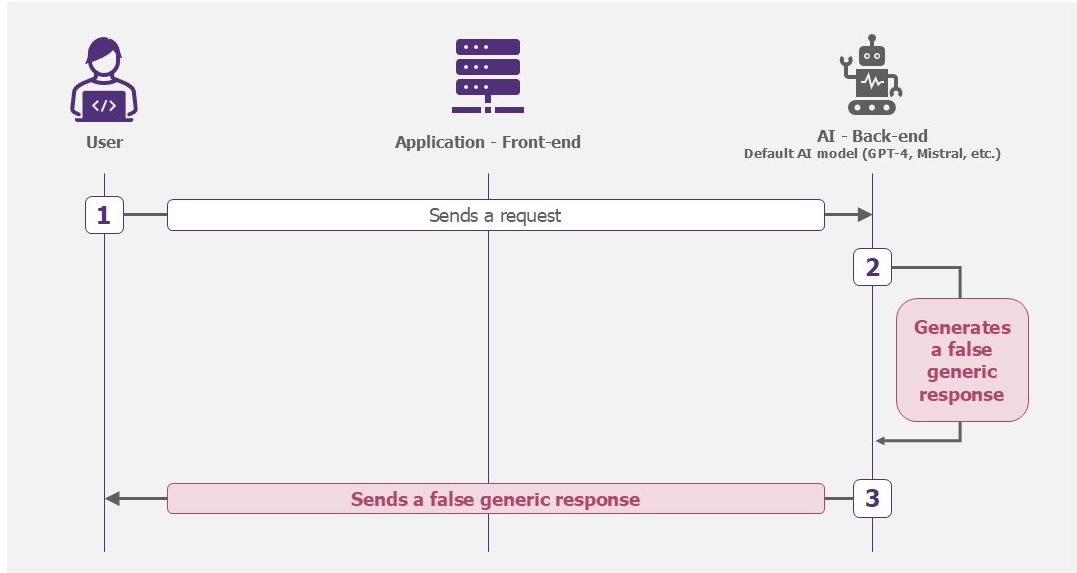
Example – Model hallucination
Data leakage
There are several ways in which data can be leaked. An attacker can inject a malicious prompt to retrieve it, or an employee can be given more rights than necessary and access sensitive information (e.g. strategic minutes of an executive committee meeting). The security of the underlying database must therefore be proportional to the amount of data stored.
The model has access to certain company data. If, for example, its rights are too extensive, it will be able to consult confidential data. These responses will therefore include sensitive information that should not be disclosed.
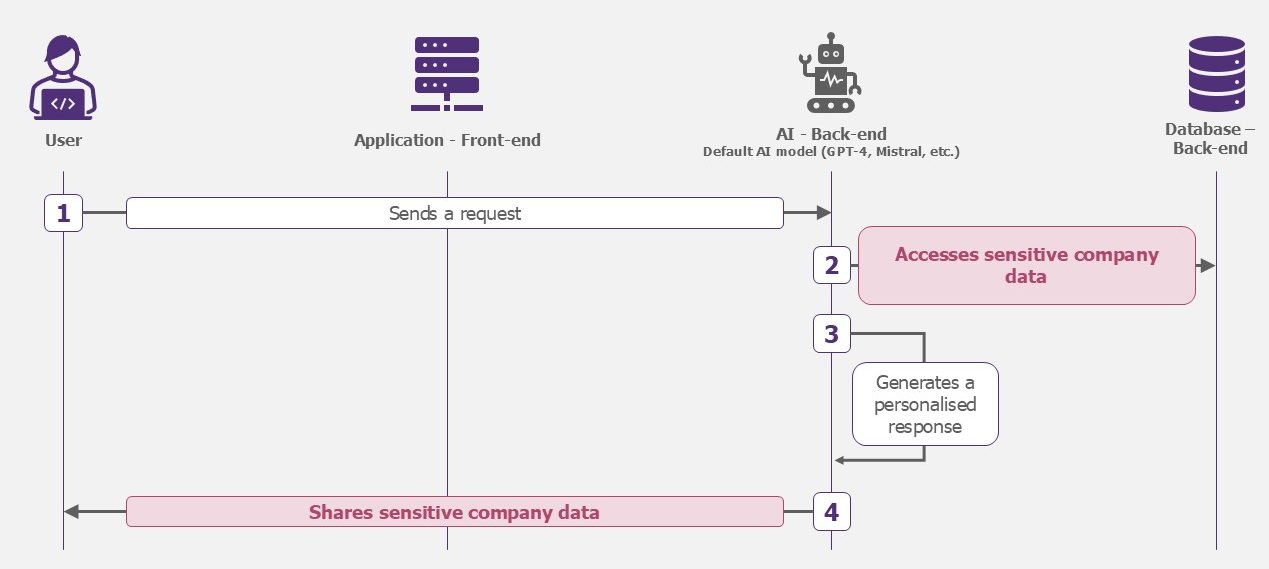
Example – Data leak
Model theft
If the model is specialized, it is now your company’s intellectual property. As such, it could be a target for attackers. Confidential training data, for example, could be targeted. The question of trust in the Cloud host may also arise: wouldn’t it be better to host it locally?
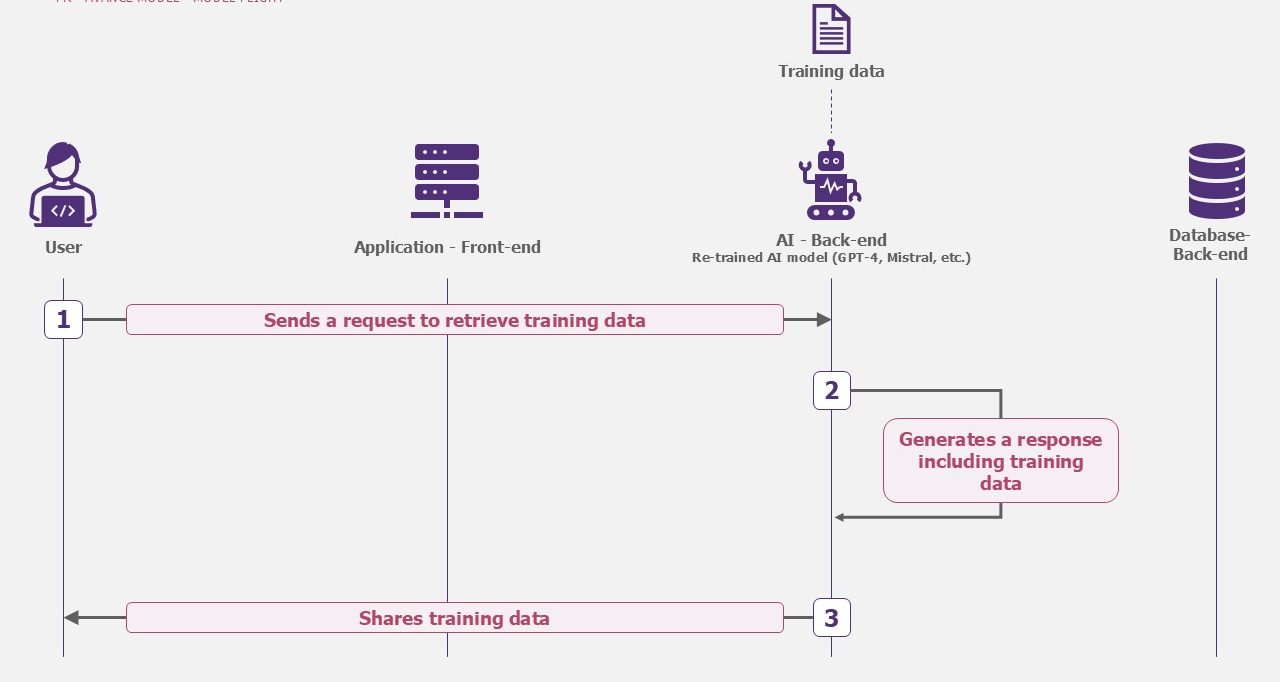
Example – Model theft
Poisoning the model
Without claiming to steal the model, the attacker’s aim could be to make it unreliable. The responses generated could then no longer be used by the teams.
Poisoning can occur in two ways:
- Boosted model: the attacker accesses the RAG and modifies the information. The model then relies on poisoned data to provide its answers.
- Specialized model: the attacker poisons the model’s training data. Either directly on the database that he makes available on a public platform (Hugging face type), or by accessing the training database hosted in your information system.
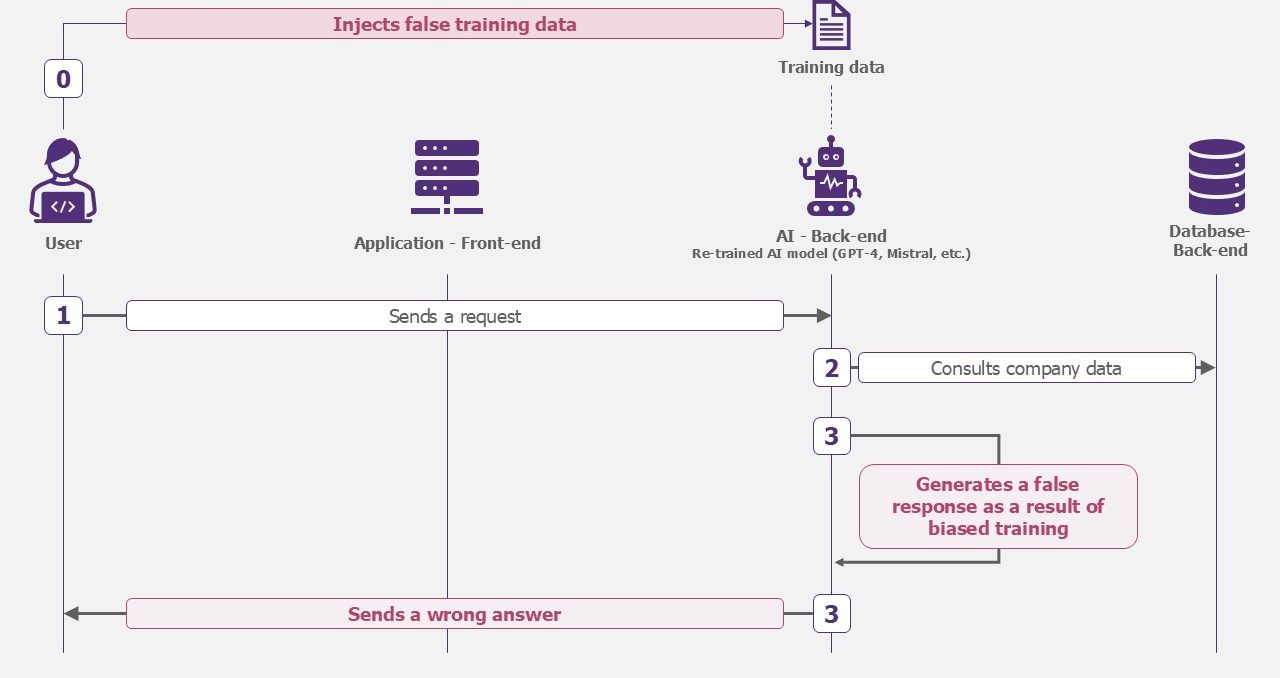
Example – Poisoning the model
Main risks: what mitigations?
Of the 5 risks presented, 3 dominate in the risk analyses carried out by our teams. We suggest you study the associated mitigations.
The novelty of the technology provides an opportunity to build a solid security foundation. Several iterations will be necessary to achieve an effective and secure solution.
Risk #1: Hijacking the model
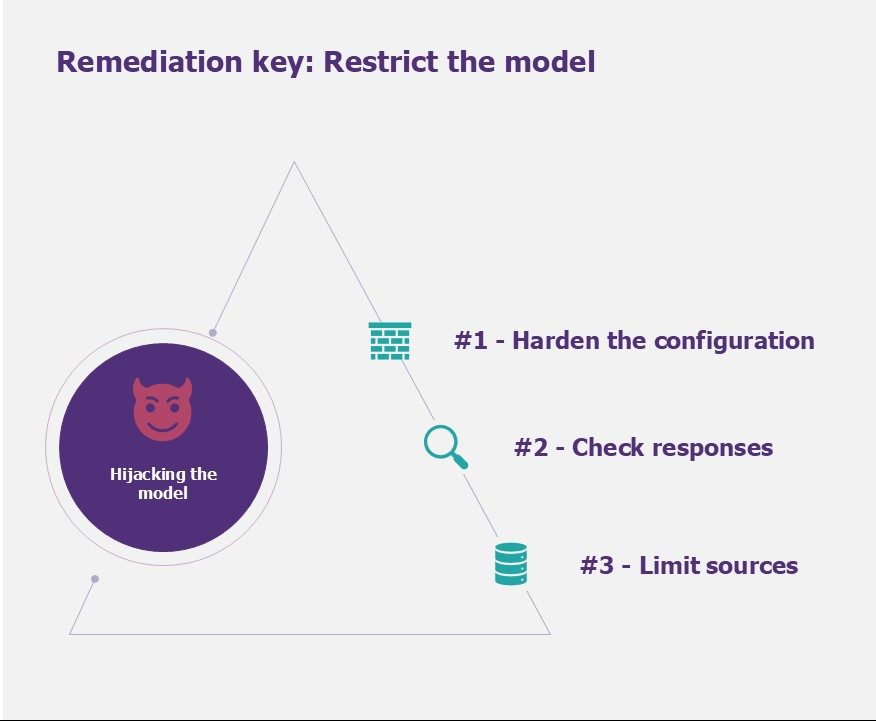
Hijacking the model and the key to remediation
We recommend the following measures to prevent the model from being hijacked:
#1 – Toughen the configuration in two ways. Firstly, management of the master prompt (discussion window with the model). Certain keywords, for example, can be banned to prevent abuse. Secondly, the number of tokens and therefore the size of responses. A less verbose model will have less chance of being hijacked. Other parameters can be taken into account: temperature, language used, etc.
#2 – Filter responses by applying, for example, a simple response filtering algorithm. To go further, it is possible to deploy specialised LLM firewalls. This would make it possible, for example, to prevent potential abuse (this is known as abuse monitoring).
#3 – Limit the sources to which the model has access to generate its responses. If the model is given access to company data, it can be limited to this data only. In this way, it will not be able to search for other information on the Internet, for example.
Risk #2: Hallucination
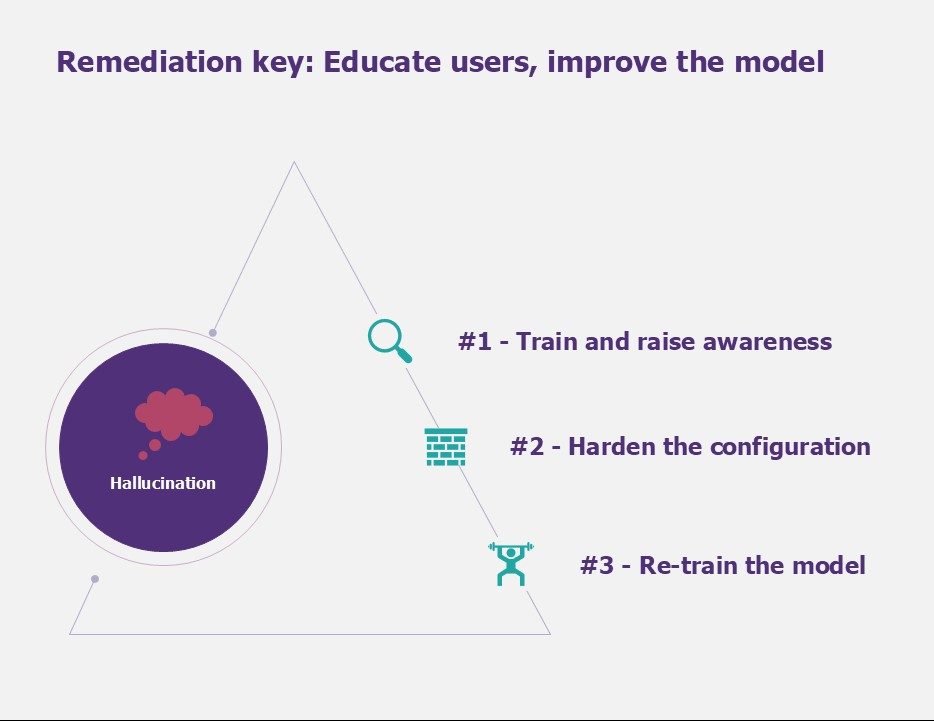
Hallucination and the key to remediation
To deal with hallucinations, we recommend the following measures:
#1 – Train and educate users on how models work, their limitations and best practices. This enables users to use Large Language Models responsibly and to recognise misuse or potential security threats.
#2 – Toughen the configuration in two ways. Firstly, adjusting the parameters, including setting the model temperature (how creative the model is) and limiting the number of tokens (number of words per question/answer). Secondly, the use of a more recent model (GPT-4 rather than GPT 3.5 for example).
#3 – Optional – Re-training the model gives it a context. This will have a positive impact on the reliability of responses. Using a wide range of training data can help to cover more scenarios and reduce bias, which helps AI to better understand and generate appropriate responses. Similarly, eliminating errors and inconsistencies in training data can reduce the likelihood of the AI learning and repeating these same errors.
Risk #3: Data leakage
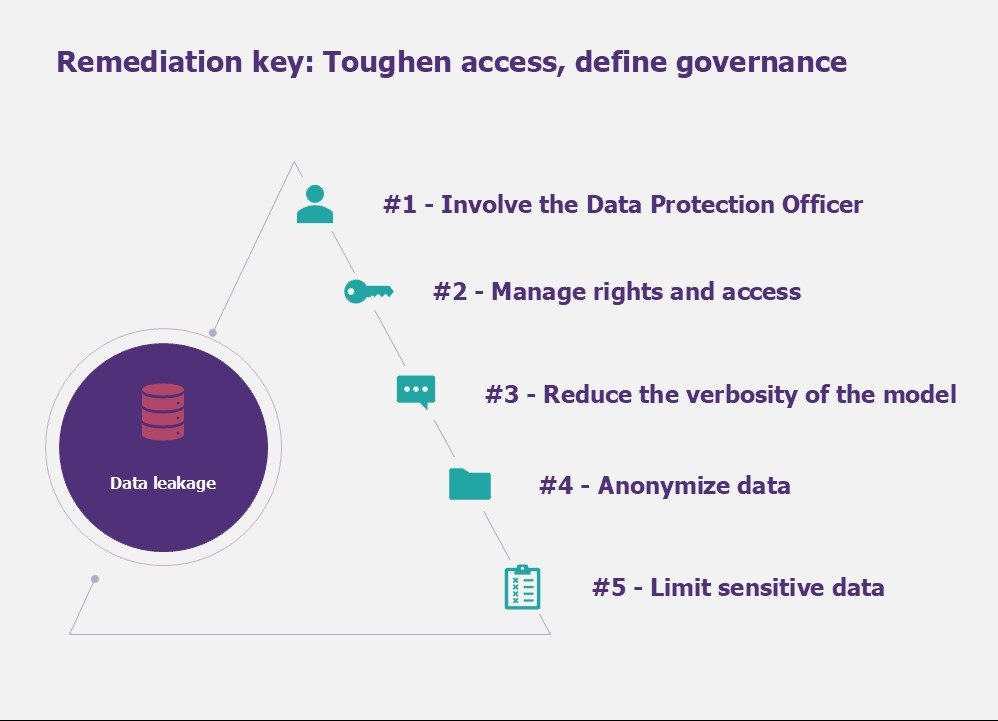 Data leakage and the key to remediation
Data leakage and the key to remediation
To deal with leaks of sensitive data, we recommend the following measures:
#1 – Ensuring compliance with data protection laws and protocols by involving the Data Protection Officer (DPO) in projects accessing Large Language Model platforms is important to protect personal and sensitive data. By adhering to these standards, organizations not only protect individual privacy but also strengthen their defense against data breaches and misuse.
#2 – Manage rights and access to all components interacting with the model. Understanding which data can be accessed by the model is not trivial. Auditing and recertifying this data over time helps to limit potential discrepancies.
#3 – Reduce the verbosity of the model by limiting the number of output tokens. The less verbose a model is, the lower the probability that it will inadvertently share confidential data.
#4 – Anonymize the data, or make it generic, if the use case allows. For example, AI will be able to work on population trends without an explicit name being cited. As well as greatly reducing the risk of data leakage, this will reduce the standards to be complied with (e.g. RGPD).
#5 – Limit the amount of sensitive data used. Here we need to think about what data is necessary and sufficient for the model to work. The data can be processed beforehand to remove or modify sensitive data and thus reduce exposure (e.g. data anonymization).
Cross-disciplinary mitigations
Certain measures apply to all the risks listed above. Two of them are fundamental.
#1 – Integrate security into projects via, for example, contextualized security analysis. This enables organizations to preventively identify and mitigate potential vulnerabilities, ensuring that only secure and verified projects access generative AI applications.
#2 – Document each application to establish an operational framework that not only facilitates easier supervision and management, but also reduces the risk of unauthorized or malicious use.
The development of AI applications is accelerated by the platforms available. However, the sophistication it brings is not without risk.
Recognizing these challenges, the priority is to establish robust governance for the platform. This involves delineating roles and responsibilities, ensuring a structured approach to managing and mitigating risks.
Governance extends beyond the platform itself. Securing the myriads of AI application use cases is just as important. It’s about ensuring that the application of this AI technology is both responsible and aligned with ethical standards, guarding against misuse and unintended consequences.
This calls for a model of shared responsibility, where all stakeholders – developers, users and governance bodies – work together to maintain the integrity and security of AI applications.
References
- https://synthedia.substack.com/p/microsoft-azure-ai-users-base-rose
- https://www.usine-digitale.fr/article/amazon-fait-son-entree-sur-le-marche-de-l-ia-generative-avec-bedrock.N2121081
- https://www.theguardian.com/technology/2024/jan/20/dpd-ai-chatbot-swears-calls-itself-useless-and-criticises-firm
- https://openai.com/blog/march-20-chatgpt-outage
- https://www.riskinsight-wavestone.com/2023/10/quand-les-mots-deviennent-des-armes-prompt-injection-et-intelligence-artificielle/

