
Artificial intelligence (AI) now occupies a central place in the products and services offered by businesses and public services, largely thanks to the rise of generative AI. To support this growth and encourage the adoption of AI, it has been necessary to industrialize the design of AI systems by adapting model development methods and procedures.
This gave rise to MLOps, a contraction of “Machine Learning” (the heart of AI systems) and “Operations”. Like DevOps, MLOps facilitates the success of Machine Learning projects while ensuring the production of high-performance models.
However, it is crucial to guarantee the security of the algorithms so that they remain efficient and reliable over time. To achieve this, it is necessary to evolve from MLOps to MLSecOps, by integrating security into processes in the same way as DevSecOps. Few organisations have adopted and deployed a complete MLSecOps process. In this article, we explore in detail the form that MLSecOps could take.
MLOps, the fundamentals of AI model development
Closer links with DevOps
DevOps is an approach that combines software development (Dev) and IT operations (Ops). Its aim is to shorten the development lifecycle while ensuring continuous high-quality delivery. Key principles include process automation (development, testing and release), continuous delivery (CI/CD) and fast feedback loops.
MLOps is an extension of DevOps principles applied specifically to Machine Learning (ML) projects. Workflows are simplified and automated as far as possible, from the preparation of training data to the management of models in production. MLOps differs from DevOps in several ways:
- Importance of data and models: In Machine Learning, data, and models are crucial. MLOps goes a step further by automating all the stages of Machine Learning, from data preparation to the training phases. What’s more, a larger volume of data is often used in Machine Learning projects.
- Experimental nature of development: Development in Machine Learning is experimental and involves continually testing and adjusting models to find the best algorithms, parameters and relevant data for learning. This poses challenges for adapting DevOps to Machine Learning, as DevOps focuses on process automation and stability.
- Complexity of testing and acceptance: The evolving nature of the models and the complexity of the data make the testing and acceptance phases more delicate in Machine Learning. What’s more, performance monitoring is essential to ensure that the models work properly in production. In Machine Learning, therefore, it is necessary to adapt the Operational Maintenance procedures to maintain the stability and reliability of the systems.
In short, an MLOps chain shares common elements with a DevOps chain although introduces additional steps and places particular importance on the management and use of data. The following graph highlights in yellow all the additional steps that MLOps introduces:
- Data access and use: This stage includes all the data engineering phases (collection, transformation and versioning of the data used for training). The challenge is to ensure the integrity of the data and the reproducibility of the tests.
- Model acceptance: ML acceptance and integration tests are more complex and take place at three different layers: the data pipeline, the ML model pipeline and the application pipeline.
- Production monitoring: This involves guaranteeing the model’s performance over time and avoiding “model drifting” (decline in performance over time). To achieve this, all deviations (instantaneous change, gradual change, recurring change) must be detected, analyzed, and corrected if necessary.
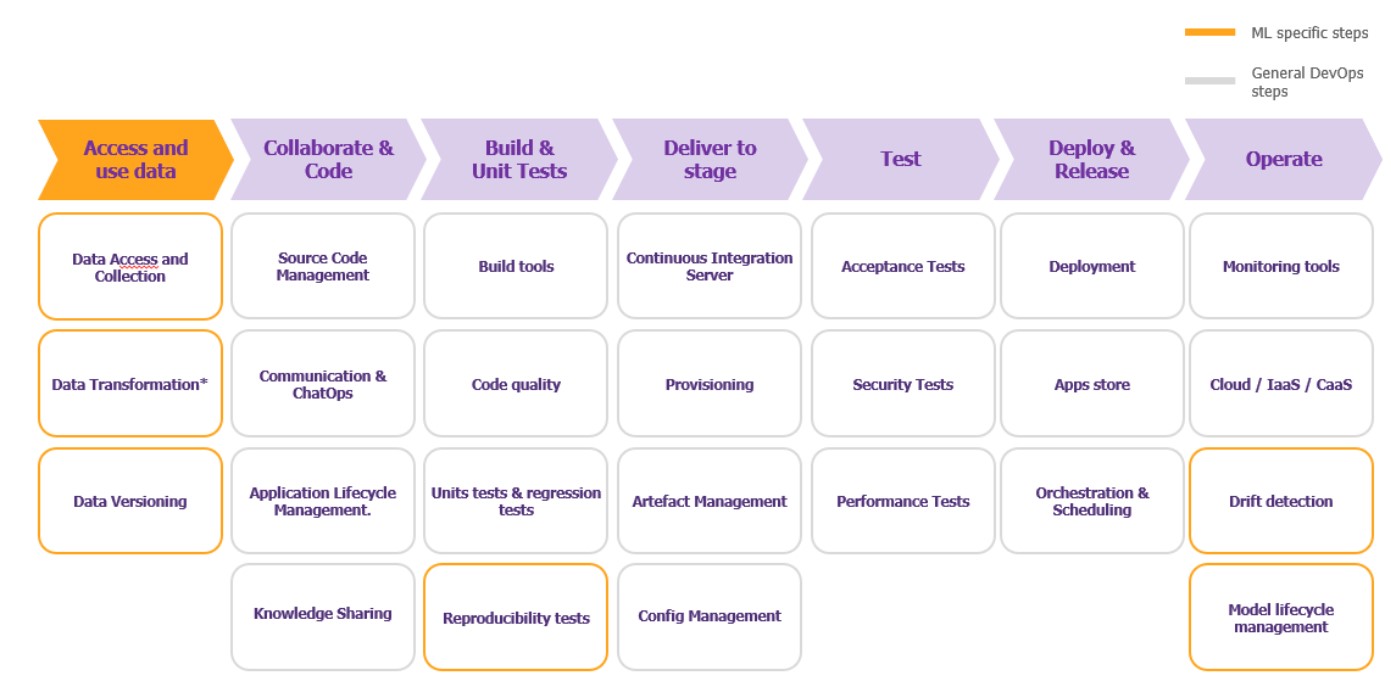
Figure 1 – Adapting the DevOps stages to Machine Learning
Implementing MLOps requires creating a dialogue between data engineers and DevOps operators
Moving to MLOps means creating new organizational steps specifically adapted to data management. This includes the collection and transformation of training data, as well as the processes for tracking the different versions of the data.
In this sense, collaboration between MLOps experts, data scientists and data engineers is essential for success in this constantly evolving field. The main challenge in setting up an MLOps chain therefore lies in integrating the data engineers into the DevOps processes. They are responsible for preparing the data that MLOps engineers need to train and execute models.
And what about safety?
The massive adoption of generative AI in 2024 has provided us with a variety of examples of security term compromises. Indeed, the attack surface is large: a malicious actor can both attack the model itself (model theft, model reconstruction, diversion from initial use) but also attack its data (extracting training data, modifying behaviour by adding false data, etc.). To illustrate the latter, we have simulated two realistic attacks in previous articles: Attacking an AI? A concrete example! or When words become weapons: prompt injection.
At the same time, MLOps introduces automation, which speeds up production. While this may reduce time to market, it also increases the risks (supply chain attacks, massaction). It is therefore crucial to ensure that the risks associated with cybersecurity and AI are properly managed.
As DevSecOps does for DevOps, the MLOps production chain must be secure. Here is an overview of the main risks in the MLOps chain:

Adopt MLSECOPS
Integrating safety into MLOPS teams and strengthening the safety culture
The principles of MLSecOps need to be understood by data scientists and data engineers. To achieve this, it is crucial that the security teams are involved from the outset of the project. This can be done in two ways:
- When a new project is created, a member of the security team is assigned as the security manager. He or she supervises progress and answers questions from the project teams.
- A more agile approach, similar to DevSecOps, involves designating a member of the team as the “Security Champion“. This cybersecurity referent within the project team becomes the main point of contact for the cyber teams. This method enables security to be integrated more realistically into the project but requires appropriate training for the Security Champion.
For this change to be effective, it is also necessary to change the way project teams perceive cybersecurity:
- By providing basic training to teams to help them better understand the challenges of cyber security.
- By integrating cyber security into collaboration and knowledge platforms.
- By organising regular awareness campaigns.
Securing MLOPS chain tools
To guarantee product security, it is essential to secure the production chain. In the context of MLOps, this means ensuring that all the tools are used correctly, with practices that incorporate cybersecurity, whether they be data processing and management tools (such as MongoDB, SQL, etc.), monitoring tools (such as Prometheus), or more or less specific development tools (such as MLFlow or GitHub).
For example, it is crucial that teams remain vigilant on issues such as identification and identity management, business continuity, monitoring and data management. The possibilities offered by the various tools used throughout the lifecycle, and their specific features, must be examined in relation to these issues. Ideally, cybersecurity features should be used as selection criteria when choosing the most suitable tool.
Defining AI security practices
In addition to the security of the tools used to build AI systems, security measures must be incorporated to prevent vulnerabilities specific to AI systems. These measures must be incorporated right from the design stage and throughout the application’s lifecycle, following an MLSecOps approach. From data collection to system monitoring, there are numerous security measures to incorporate:
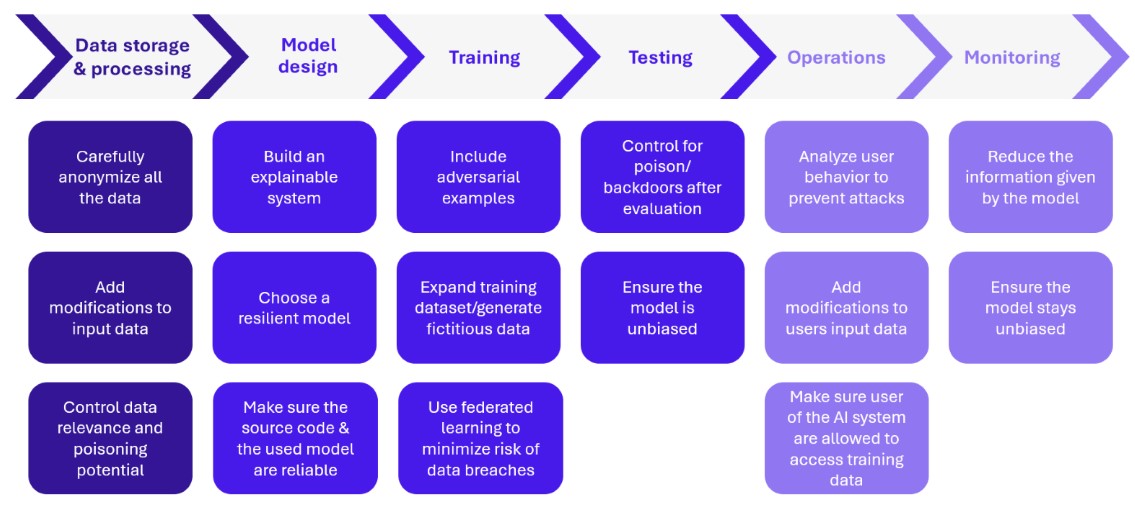
Figure 2 – Securing the MLOps lifecycle
Three security measures to implement in your MLSecOps processes
Depending on the security strategy adopted, various security measures can be integrated throughout the MLOps lifecycle. We have detailed the main defence mechanisms for securing AI in the following article: Securing AI: The New Cybersecurity Challenges.
In this section, we will focus on 3 specific measures that can be implemented to enhance the security of MLOps:
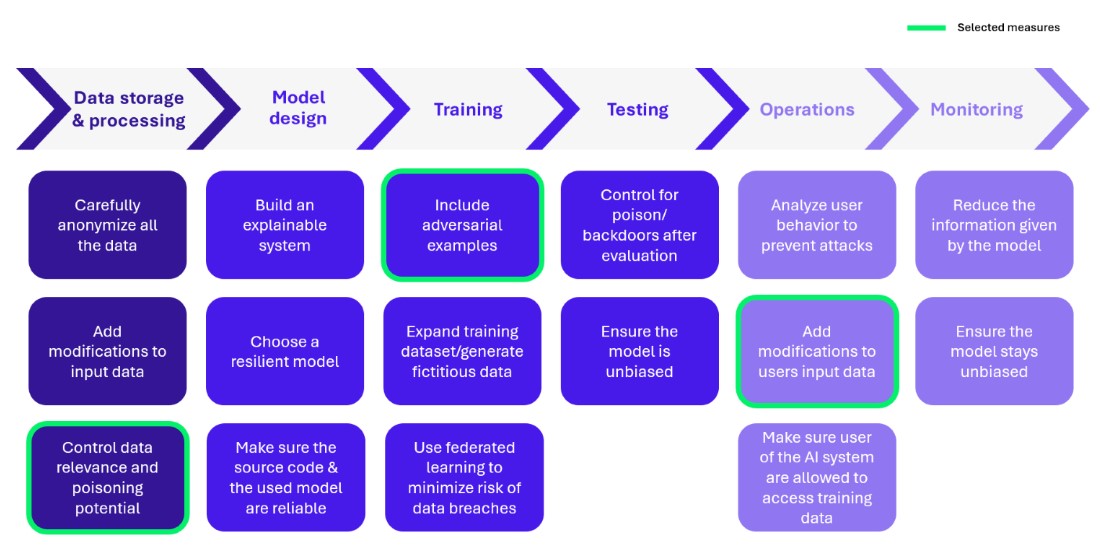
Figure 3 – Selected security measures
Checking the relevance of data and the risks of poisoning
In the context of Machine Learning, data security is essential to prevent the risk of poisoning and to guarantee the integrity of the data processed.
Before processing the data collected, it is essential to continually check the origin of the data in order to guarantee its quality and relevance. This is all the more complex when using external data streams, the provenance and veracity of which can sometimes be uncertain. The major risk lies in the integration of user data during continuous learning. This can lead to unpredictable results, as illustrated by the example of Microsoft’s TAY ChatBot in 2016. This was designed to learn through user interaction. However, without proper moderation, it quickly adopted inappropriate behaviour, reflecting the negative feedback it received. This incident highlights the importance of constant monitoring and moderation of input data, particularly when it comes from real-time human interactions.
Various analysis techniques can be used to clean up a dataset. The aim is to check the integrity of the data and remove any data that could have a negative impact on the model’s performance. Two main methods are possible:
- On the one hand, we can individually check the integrity of each data item by checking for outliers, validating the format or characteristic metrics, etc.
- On the other hand, with a global analysis, approaches such as cross-validation and statistical clustering are effective in identifying and eliminating inappropriate elements from the dataset.
Introduce contradictory examples
Contradictory examples are corrupted inputs, modified to mislead the predictions of a Machine Learning algorithm. These modifications are designed to be undetectable to the human eye but sufficient to fool the algorithm. This type of attack exploits vulnerabilities or flaws in the model training to cause prediction errors. To reduce these errors, the model can be taught to identify and ignore this type of input.
To do this, we can deliberately add contradictory examples to the training data. The aim is to present the model with slightly altered data, in order to prepare it to correctly identify and manage potential errors. Creating this type of degraded data is complex. The generation of these contradictory examples must be adapted to the problem and the threats identified. It is crucial to carefully monitor the training phase to ensure that the model effectively recognises these incorrect inputs and knows how to react correctly.
Modify user entries
Input security is essential to minimise the risks associated with malicious manipulation. A major weakness of LLMs (Large Language Models) is their lack of in-depth contextual understanding and their sensitivity to the precise formulation of prompts. One of the best-known techniques for exploiting this vulnerability is the prompt injection attack. It is therefore necessary to introduce an intermediate step of transforming user data before it is processed by the model.
It is possible to modify the input slightly in order to counter this type of attack, while preserving the accuracy of the model. This transformation can be carried out using various techniques (e.g. coding, adding noise, reformulation, feature compression, etc.). The aim is to retain only what is essential for the response. In this way, any superfluous, potentially malicious information is discarded. In addition, this method deprives the attacker of the possibility of accessing the real input to the system. This prevents any in-depth analysis of the relationships between inputs and outputs, and thus complicates the design of future attacks. However, it remains essential to test the various measures implemented, to ensure that they do not degrade the performance of the model, thus guaranteeing enhanced security without compromising efficiency.
Due to industrial production of applications based on Machine Learning and AI, large-scale security is becoming a crucial organisational issue for the market. It is imperative to make the transition to MLSecOps. This transformation is based on three main pillars:
- Strengthening the security culture of Data Scientists: It is essential that Data Scientists understand and integrate security principles into their day-to-day work. This creates a shared security culture and strengthens collaboration between the various players.
- Securing the tools that produce Machine Learning algorithms: It is essential to select secure MLOPS tools and apply best practices within the tools (rights management, etc.) to secure the Machine Learning algorithm “factory” and thus reduce the surface area for compromise.
- Integrating AI-specific security measures: Adapting security measures to the specific features of AI systems is crucial to preventing potential attacks and ensuring the reliability of models over time. These security measures should therefore be integrated into the MLOps chain using MLSecOps.
Make the transition to MLSecOps today. Train your teams, secure your tools, and integrate AI-specific security measures. Making this shift, you will be able to benefit from AI systems that are industrially produced and secure by design.
Thanks to Louis FAY and Hortense SOULIER who contributed to the writing of this article as well.

