
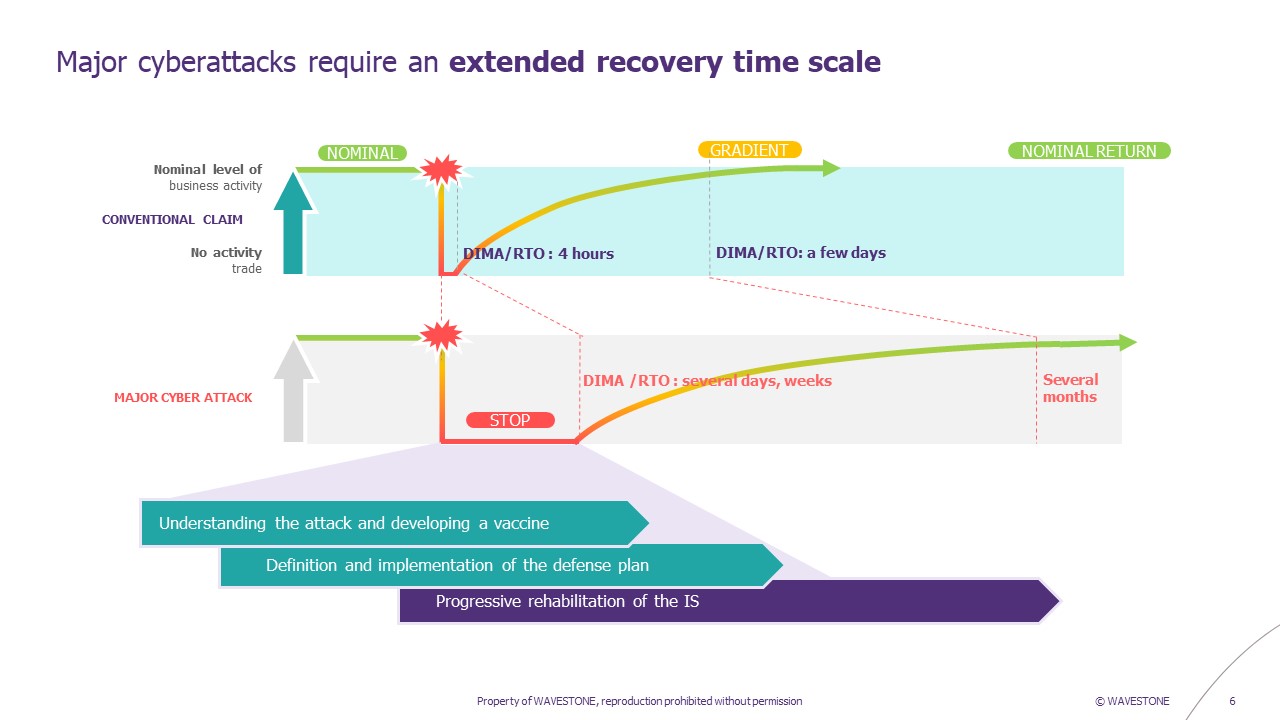
At the end of June 2017, an image shocked the minds of the cyber security and business continuity world. An open space, filled with workstations, all displaying the same screen: the NotPetya ransomware message. Even today, 90% of the crises managed by Wavestone CERT are caused by ransomware [1]. How, then, is it possible to begin investigations, reconstruction or enable the business to continue working if all workstations stop functioning? What strategy should be developed to integrate the workstation component into continuity plans, which until now have mainly addressed it from the point of view of disasters affecting buildings?
Define the needs
To begin with, it’s important to define the cyber scenario you want to protect yourself against. Is it a “total blackout” scenario, where the entire IS is unavailable? Or a basic Windows ransomware scenario where some Windows servers and workstations are compromised, but network equipment and Linux bricks are still functioning?
Next, and based on the scenarios selected, it is necessary to segment the populations according to their needs: it is not possible to provide for an infinite number of workstations in a given period, and you need to know where to allocate the first workstations that will be made available. For example, we can distinguish between business-critical teams, whose activity cannot be interrupted for more than 4 hours, and less critical business activities, for which activity can be interrupted for 3 days with acceptable impacts for the company in crisis mode. Similarly, the IT and Cyber teams to be mobilized in the very first hours of a crisis to conduct investigations and begin reconstruction.
Another point to consider is the minimum business functionality required for the rebuilt workstations to be useful. Some business populations use thick clients on their workstations, which can be complex to install and maintain. Likewise, certain professions need to interact with third parties for their vital activities, via dedicated VPNs or an IP whitelist. It is therefore essential to clearly define how many people have these needs, and in what timeframe, to define the technical solutions that can be implemented.
We won’t necessarily propose the same solution to IT investigation and reconstruction teams – who need access to the internal network – as to business teams, who may have degraded modes of operation outside the company’s information system (IS) for the first few days of a crisis.
When all is said and done, we tend to distinguish two clearly differentiated phases in the strategy for providing workstations in the event of a ransomware crisis:
- A first phase during the very first days of the crisis, for a limited population, which will generally rely on solutions with the least possible adherence to the nominal Information System, in order to ensure critical business activities;
- A second phase when investigations have progressed, with a massive workstation rebuild using the company’s master workstation, which will have been hardened beforehand by drawing lessons from past investigations.
Adapting the solution to your context
Several parameters need to be taken into account when planning your workstation rebuild strategy. One solution may work for one company but be unsuitable for another.
For example, numerous security and access control measures have been put in place in recent years concerning access to the internal workstation network. NAC (Network Access Control) is increasingly widespread, and in recent buildings, Ethernet sockets accessible to each desk are tending to disappear. Office 365 access is restricted via conditional access, and VPN (Virtual Private Network) gateway authentication is based on a certificate on the workstation. When all these constraints exist, a BYOD (Bring Your Own Device) strategy for the first few days of a crisis cannot be the answer – at least not on its own.
Also, the way in which workstations are managed is a determining factor and does not necessarily mean that the same technical solutions can be implemented for reconstruction. Generally speaking, there are two main approaches:
- One, a so-called “historical” approach, with fleet management solutions based on classic architecture such as Microsoft System Center Configuration Manager (SCCM), which is the most widespread solution today.
- Alternatively, a more “modern” approach (i.e. Modern Management) with Cloud-based fleet management solutions such as Microsoft Intune, which has been gaining ground in recent years.
Reconstruction methodology also needs to be anticipated. There are two possible methods: restoration and reinstallation. Restoration represents a return to a previous state of the environment (OS and/or applications and/or data) thanks to a backup. Reinstallation, as the name implies, means rebuilding the workstation from scratch, losing local documents.
In the case of workstations, the number of documents stored locally is generally fewer and is therefore a less critical issue. Most documents are now stored on file servers (NAS or Sharepoint) for shared work, or in the user’s personal OneDrive. As a result, users will be more inclined to reinstall workstations from scratch, rather than take the risk of restoring the system to a previous state, where the ransomware may already have been present but not yet activated. Especially as recent ransomware attacks local restore points [2].
Choosing the reconstruction methods best suited to your strategy
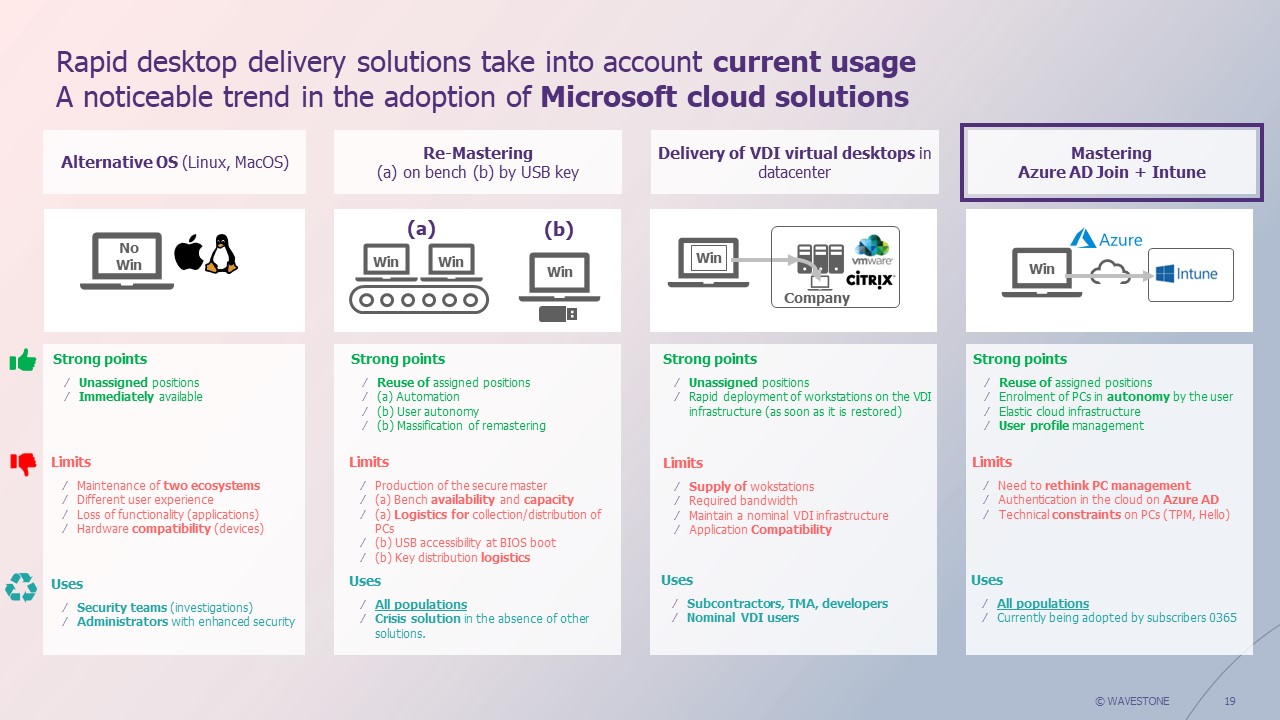
There are several different ways of providing workstations, depending on the situation and the formalization of needs discussed above. Here is a list of the main solutions we have encountered in the field, and our opinion on the advantages and disadvantages of each solution.
- Building up a stock of emergency PCs
A method often applied in conventional emergency plans (for building/site loss scenarios), crisis PCs are placed in Ergotron-type containers, ready for use in the event of a disaster. They are connected to the local network via the Ergotron, and automatically receive updates. Another strategy may be to rely on IT departments’ rolling stock of workstations, or to keep decommissioned workstations as backup stock.
Our opinion: While this approach is well-suited to resilience scenarios such as the loss of a building/site, it presents a risk in the face of ransomware, as these PCs would be compromised in the same way as others, since they would be accessible and visible on the local network. These PCs would then have to be managed “off-line”, requiring a higher level of MCO (maintenance in operational condition), since the PCs would have to be manually switched on and updated regularly. What’s more, having unused, dormant equipment raises the question of optimizing resources and carbon footprint. This solution should be considered for a restricted population with a very low acceptable downtime. In addition, for populations using thick clients, it is possible to save time by pre-installing them on these dormant workstations.
- The use of unmanaged PCs, via BYOD (Bring Your Own Device) or the use of “consumer PCs” purchased in the event of a crisis
This strategy is generally associated with a “Total IT Blackout” scenario, in which the entire information system is considered compromised, and work must be carried out without any link to it. In this case, unmanaged workstations are used, either personal or mobilized in the event of a crisis via a contract with a supplier.
Our opinion: the functionalities of this solution are limited, as the workstation has no access to the company VPN, and if NAC is deployed, when visiting the site, the PC will not have access to internal resources that are still functional. It can, however, be considered in conjunction with crisis measures that have been planned in advance and will enable the PC’s functionality to be improved (emergency NAC shutdown; temporary modification of O365 Conditional Access with Internet access; storage of business-critical data in a crisis Vault outside the IS, so that work can continue). In most cases, this solution will be reserved mainly for the business community, and possibly for the IT staff in charge of rebuilding – by coupling it with a return-to-site strategy and a lifting of the NAC, enabling physical access to the internal network. This remains a solution that can be highly effective when well anticipated and combined with the crisis measures mentioned above.
- Nominal existence of workstations under another OS
In the event of an attack specifically targeting Windows environments (most encountered in the field), the affected computers can be replaced by the solution running on another OS.
Our opinion: this solution implies an MCO (Maintaining Operational Conditions) of at least two technologies and does not guarantee that users who normally work under Windows will be able to work under Linux or MacOS (non-compatible thick clients, etc.). It is, however, an entirely feasible solution for very specific populations, such as investigation teams. These teams generally prefer to use specific distributions such as Kali Linux, and these are the people who need to have access to the IS in the first hours of a crisis.
- Remastering workstations on benches
In the event of a crisis, the teams go to the various sites with mastering benches with their compromised PCs to be remastered. Even in the largest companies, run remastering benches have limited rebuild capacity (a maximum of a few hundred workstations/day per site). To increase this capacity, additional crisis remastering benches can also be provided as part of a contract with an external supplier.
Our opinion: the remastering method in nominal mode on a bench requires careful preparation to be effective in the event of a crisis, given the volume of substations to be rebuilt. A plan must be drawn up to organize the return of many people to the site at the same time (distribution by site, communication to users on time slots, etc.), based on the remastering capacity of the benches per physical site.
- Remastering workstations via USB keys
In the event of a crisis, USB sticks prepared in advance (or to be generated during the crisis using a predefined procedure) with a Windows OS image are used to reinstall a new OS on the machine. This can be a blank Windows OS, or a company-specific image.
Our opinion: this is a tried-and-tested method for crisis situations, which can save a lot of time if it is anticipated. You need enough USB sticks, with a recent Windows OS image, and a method for quickly cloning the sticks. You also need to define a way of distributing these keys to users (either before the crisis – but this makes updating the keys more complex, and there is a risk of losing them – or during the crisis, by going to an IT kiosk, as with the benches). It is also necessary to be able to boot on external media. If this functionality is blocked in the BIOS, this method cannot work, or at least not without a procedure to lift this restriction. This method can be combined with the use of benches to maximize the number of workstations to be remastered in parallel on site (some of the PCs run on the benches, while others launch the process via USB key). Similarly, if the workstation bootstrap has been compromised, a USB key with a blank Windows can be combined with Intune remastering at a later stage.

- The use of crisis VDI (Virtual Desktop Infrastructure)
Users connect to a remote virtual desktop via a browser. This solution must necessarily be combined with another (BYOD, consumer PC purchased for the occasion, or other) as a PC is required to connect to the remote VDI. VDIs can offer more or less advanced functionalities, depending on their link with the company’s IS (access to the internal network, pre-installation of thick clients, etc.).
Our opinion: This system enables rapidly operational work environments, while limiting the risk of data leakage, since it is possible to prohibit copy/paste from the VDI to the host workstation. What’s more, by relying on VDIs in the cloud, you can achieve a high level of scale-up potential (from 1 VDI to 200 active VDIs very quickly in the event of a crisis). The main risk remains that the more the VDI infrastructure is correlated with the company’s IS, the greater the likelihood that it too will be compromised by the attack. In this case, relying solely on this solution is a risky gamble. Conversely, a VDI that is completely uncorrelated with the IS will function, but will offer limited functionality without any access to uncompromised parts of the company’s IS.
- Re-mastering from the cloud via Intune
The master deployed on workstations is externalized to Intune, a SaaS service hosted in the Microsoft cloud. At start-up or after a factory reset, the workstation asks the user to enter his or her Microsoft email address, thus identifying the user as a member of the company. This triggers the automatic download and installation of the master, with no further intervention required. There is one important prerequisite, however: the fleet must be natively managed via Intune to be able to use these methods.
Our opinion: This is one of the most effective methods, particularly as it is possible to modify the image (in the event of compromise via a vulnerable protocol/patching flaw), then remotely launch a massive remastering of the compromised workstations from within Intune. It is also possible to carry out this self-service remastering on the user’s side, but a prerequisite will then exist: possession of the workstation’s BitLocker recovery key (or other encryption technology if applicable), if the workstation’s hard disk is encrypted as part of the workstation protection measures deployed by the company. For reasons of practicality on the day of the crisis, mass remastering launched from the Intune console is therefore preferable, as it avoids the BitLocker constraint. To do this, however, administrators must be guaranteed access to Intune – and Intune itself must not be compromised. Last but not least, if the ransomware destroys the workstation’s bootstrap, it won’t be possible to remaster it with Intune alone, and you’ll need to add the installation of a blank Windows on the workstation as a prerequisite (via a USB key, for example).
It should be noted that there are also a few exceptional crisis situations in which, due to limited response and management resources, some organizations may choose to allow employees to work in degraded mode on compromised machines for a set period, if they are still operational. This may be the case, for example, when only office files have been encrypted, when the malware is passive and does not communicate with a Command and Control system, and by removing Internet access from workstations to prevent any remote takeover.
To sum up, what are the success factors for an office environment resilience strategy?
There’s no such thing as a “magic” solution for every situation, and every solution meets the need to get a workstation up and running again, but the choice of the best solution depends on several parameters specific to each organization. To ensure an effective strategy, it is important to :
- Segment the company’s different populations to prioritize the provision of workstations, and propose solutions adapted to the specific needs of each one.
- Diversify and adapt solutions. Focusing on a single solution can prove dangerous if it fails. The aim is to have a toolbox of technical solutions, which the crisis unit can choose to activate or not, depending on the exact nature of the crisis encountered.
- Test solutions: whatever solutions and strategies are implemented to rebuild workstations, they must always be accompanied by planned tests. A solution that is not used regularly is a solution that may not work in the event of a crisis. Whenever possible, therefore, the backup solution should be used on a day-to-day basis to remaster PCs, or if VDIs are involved, they should be used on a regular basis. If this is not possible, the solution should be integrated into a business and/or IT continuity test plan, so that it can be tested in real-life conditions at least once a year.
The solutions most frequently used in the field include mass remastering on the bench, building up a stock of crisis workstations, using Cloud solutions such as Intune and virtual desktops such as VDI coupled with BYOD. But these solutions, taken one by one, may not be enough, because as mentioned in the principle of diversification, putting all your eggs in one basket can cause problems. We could, for example, imagine a crisis where access to the Intune console is impossible and/or the Intune image itself has been altered by the attack. In this case, having a fallback solution such as external VDI or remastering via USB key is essential.
[1] https://fr.wavestone.com/fr/insight/cyberattaques-en-france-le-ransomware-menace-numero-1/

