
Generative AI systems are fallible: in March 2025, a ChatGPT vulnerability was widely exploited to trap its users; a few months earlier, Microsoft’s health chatbot exposed sensitive data; in December, a simple prompt injection allowed the takeover of a user account on the competing service DeepSeek.
Today, the impacts are limited because the latitude given to AI systems is still relatively low. Tomorrow, with the rise of agentic AI, accelerated adoption of generative AI, and the multiplication of use cases, the impacts will grow. Just as the ransomware WannaCry exploited vulnerabilities on a massive scale in 2017, major cyberattacks are likely to target AI systems and could result in injuries or financial bankruptcies.
These risks can be anticipated. One of the most pragmatic ways to do this is to take on the role of a malicious individual and attempt to manipulate an AI system to study its robustness. This approach highlights system vulnerabilities and how to fix them. Specifically for generative AI, this discipline is called AI RedTeaming. In this article, we offer insight into its contours, focusing particularly on field feedback regarding the main vulnerabilities encountered.
To stay aligned with the market practices, this article exclusively focuses on the RedTeaming of generative AI systems.
Back to basics, how does genAI work ?
GenAI relies on components that are often distributed between cloud and on-premise environments. Generally, the more functionalities a generative AI system offers (searching for information, launching actions, executing code, etc.), the more components it includes. From a cybersecurity perspective, this exposes the system to multiple risks :
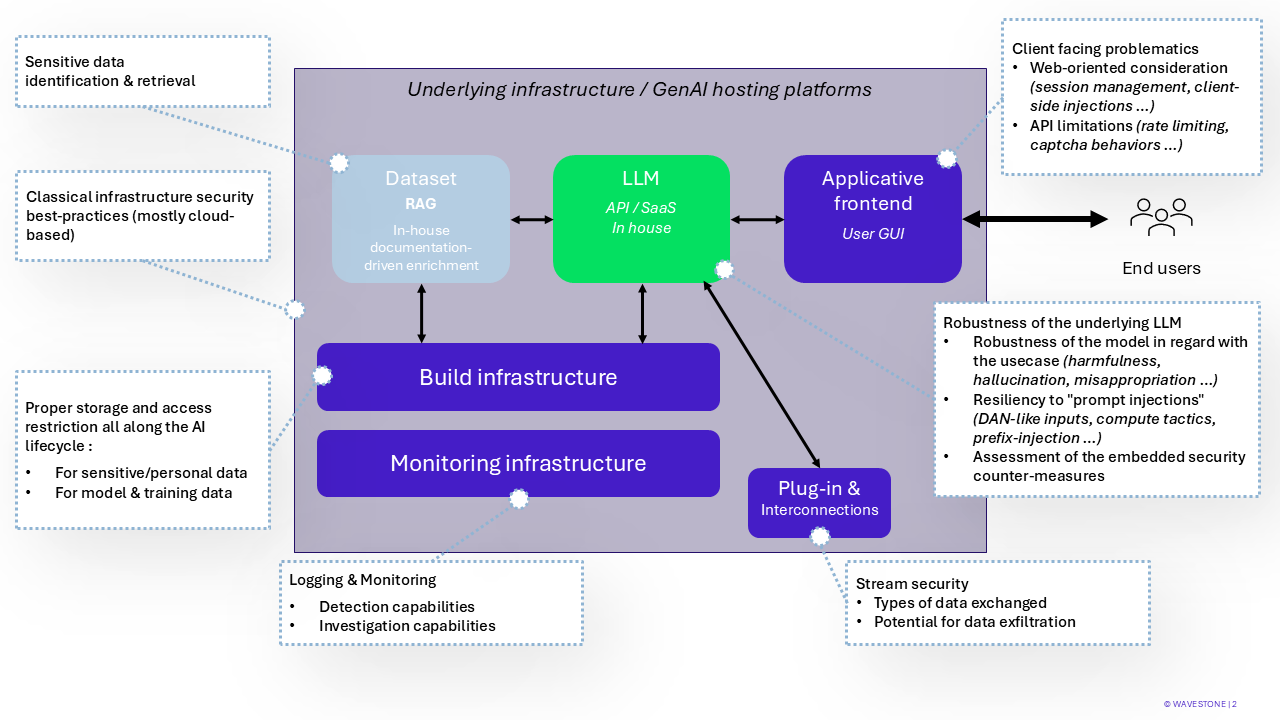
Diagram of a Generative AI System and Issues Raised by Component
In general, an attacker only has access to a web interface through which they can interact (click, enter text into fields, etc.). From there, they can:
- Conduct classic cybersecurity attacks (inserting malicious scripts – XSS, etc.) by exploiting vulnerabilities in the AI system’s components;
- Perform a new type of attack by writing in natural language to exploit the functionalities provided by the generative AI system behind the web interface: data exfiltration, executing malicious actions using the privileges of the generative AI system, etc.
Technically, each component is protected by implementing security measures defined by Security Integration Processes within Projects. It is then useful to practically assess the effective level of security through an AI RedTeam audit.
RedTeaming IA, Art of findings AI vulnerabilities
AI RedTeam audits are similar to traditional security audits. However, to address the new challenges of GenAI, they rely on specific methodologies, frameworks, and tools. Indeed, during an AI RedTeam audit, the goal is to bypass the generative AI system by either attacking its components or crafting malicious instructions in natural language. This second type of attack is called prompt injection, the art of formulating malicious queries to an AI system to divert its functionalities.
During an AI RedTeam audit, two types of tests in natural language attacks (specific to AI) are conducted simultaneously:
- Manual tests. These allow a reconnaissance phase using libraries of malicious questions consolidated beforehand.
- Automated tests. These usually involve a generative AI attacking the target generative AI system by generating a series of malicious prompts and automatically analyzing the coherence of the chatbot’s responses. They help assess the system’s robustness across a wide range of scenarios.
These tests typically identify several vulnerabilities and highlight cybersecurity risks that are often underestimated.
What are the main vulnerabilities we found ?
We have covered three main deployment categories with our clients:
- Simple chatbot : these solutions are primarily used for redirecting and sorting user requests;
- RAG (Retrieval-Augmented Generation) chatbot : these more sophisticated systems consult internal document databases to enrich their responses;
- Agentic chatbot : these advanced solutions can interact with other systems and execute actions.
The consolidation of vulnerabilities identified during our interventions, as well as their relative criticality, allows us to define the following ranking:
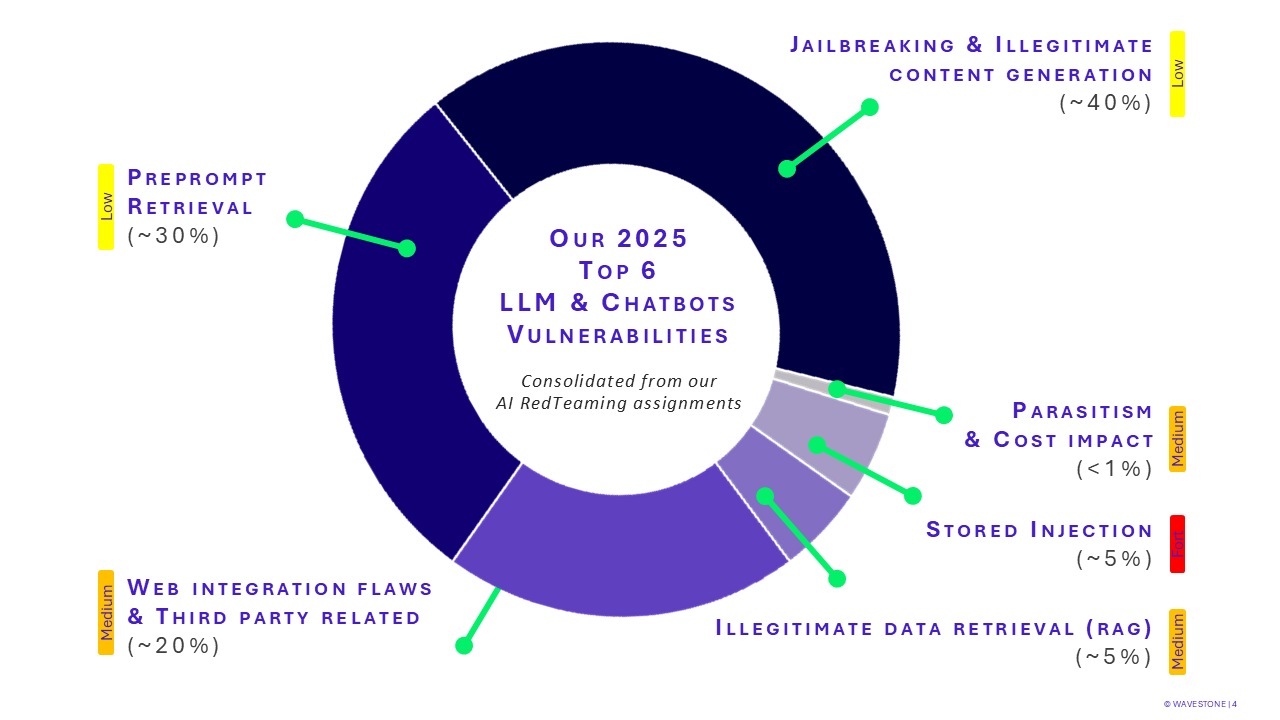
Diversion of the model and generation of illegitimate content
This concerns the circumvention of the technical safeguards put in place during the development of the chatbot in order to generate offensive, malicious, or inappropriate content. Thus, the credibility and reputation of the company are at risk of being impacted since it is responsible for the content produced by its chatbot.
It is worth noting that the circumvention of the model’s security mechanisms can lead to a complete unlocking. This is referred to as a jailbreak of the model, which shifts it into an unrestricted mode. In this state, it can produce content outside the framework desired by the company.
Access to the preprompt
The term preprompt refers to the set of instructions that feed the model and shape it for the desired use. All models are instructed not to disclose this preprompt in any form.
An attacker gaining access to this preprompt has their attack facilitated, as it allows them to map the capabilities of the chatbot model. This mapping is particularly useful for complex systems interfaced with APIs or other external systems. Furthermore, access to this preprompt by an attacker enables them to visualize how the filters and limitations of the chatbot have been implemented, which allows them to bypass them more easily.
Web integration and third-party integration
GenAI solutions are often presented to users through a web interface. AI RedTeaming activities regularly highlight classic issues of web applications, particularly the isolation of user sessions or attacks aimed at trapping them. In the case of agentic systems, these vulnerabilities can also affect third-party components interconnected with the GenAI system.
Sensitive data leaks
If the data feeding the internal knowledge base of a RAG chatbot is insufficiently consolidated (selection, management, anonymization, …), the models may inadvertently reveal sensitive or confidential information.
This issue is related to aspects of rights management, data classification, and hardening the data preparation and transit pipelines (MLOps).
Stored injection
In the case of stored injection, the attacker is able to feed the knowledge base of a model by including malicious instructions (via a compromised document). This knowledge base is used for the chatbot’s responses, so any user interacting with the model and requesting the said document will have their session compromised (leak of users’ conversation history data, malicious redirections, participation in a social engineering attack, etc.).
Compromised documents may be particularly difficult to identify, especially in the case of large or poorly managed knowledge bases. This attack is thus persistent and stealthy.
Mention honorable: parasitism and cost explosion
We talk about parasitism when a user is able to unlock the chatbot to fully utilize the model’s capabilities and do so for free. Coupled with a lack of volumetric restrictions, a user can make a prohibitive number of requests, unrelated to the initial use case, and still be charged for them.
In general, some of the mentioned vulnerabilities concern relatively minor risks, whose business impact on information systems (IS) is limited. Nevertheless, with advances in AI technologies, these vulnerabilities take on a different dimension, particularly in the following cases:
- Agentic solutions with access to sensitive systems
- RAG applications involving confidential data
- Systems for which users have control over the knowledge base documents, opening the door to stored injections
The tested GenAI systems are largely unlockable, although the exercise becomes more complex over time. This persistent inability of the models to implement effective restrictions encourages the AI ecosystem to turn to external security components.
What are the new attack surfaces ?
The increasing integration of AI into sensitive sectors (healthcare, finance, defense, …) expands the attack surfaces of critical systems, which reinforces the need for filtering and anonymization of sensitive data. Where AI applications were previously very compartmentalized, agentic AI puts an end to this compartmentalization as it deploys a capacity for interconnection, opening the door to potential threat propagation within information systems.
The decrease in the technical level required to create an AI system, particularly through the use of SaaS platforms and Low/no code services, facilitates its use for both legitimate users and attackers.
Finally, the widespread adoption of “co-pilots” directly on employees’ workstations results in an increasing use of increasingly autonomous components that act in place of and with the privileges of a human, accelerating the emergence of uncontrolled AI perimeters or Shadow IT AI.
Towards increasingly difficult-to-control systems
Although appearing to imitate human intelligence, GenAI models (LLMs, or Large Language Models) have the sole function of mimicking language and often act as highly efficient text auto-completion systems. These systems are not natively trained to reason, and their use encounters a “black box” operation. It is indeed complex to reliably explain their reasoning, which regularly results in hallucinations in their outputs or logical fallacies. In practice, it is also impossible to prove the absence of “backdoors” in these models, further limiting our trust in these systems.
The emergence of agentic AI complicates the situation. By interconnecting systems with opaque functioning, it renders the entire reasoning process generally unverifiable and inexplicable. Cases of models training, auditing, or attacking other models are becoming widespread, leading to a major trust issue when they are integrated into corporate information systems.
What are the perspectives for the future ?
The RedTeaming AI audits conducted on generative AI systems reveal a contrasting reality. On one hand, innovation is rapid, driven by increasingly powerful and integrated use cases. On the other hand, the identified vulnerabilities demonstrate that these systems, often perceived as intelligent, remain largely manipulable, unstable, and poorly explainable.
This observation is part of a broader context of the democratization of AI tools coupled with their increasing autonomy. Agentic AI, in particular, reveals chains of action that are difficult to trace, acting with human privileges. In such a landscape, the risk is no longer solely technical: it also becomes organizational and strategic, involving continuous governance and oversight of its uses.
In the face of these challenges, RedTeaming AI emerges as an essential lever to anticipate possible deviations, adopting the attacker’s perspective to better prevent drifts. It involves testing the limits of a system to design robust, sustainable protection mechanisms that align with new uses. Only by doing so can generative AI continue to evolve within a framework of trust, serving both users and organizations.

