
Managing access rights to an organisation’s resources is a central issue in IAM. An authorisation model provides a layer of abstraction that guides the allocation of technical permissions to users and makes it easier to monitor them over time.
To this end, there are many existing rights models: MAC, DAC, GBAC, ABAC, etc.
How do you understand these many different rights models in practical terms and apply them to your business?
The models differ in their degree of complexity and in the response they provide to the specific needs and constraints of an organisation or system. The most recent models incorporate issues of security, scalability and compliance in an increasingly complex technological environment.
In this article, we will follow a chronological logic, identifying how authorisation has evolved over the decades to meet the challenges faced by organisations. We will see that, like information systems, rights model approaches have become increasingly complex and now include more and more parameters for deciding whether to grant or deny access.
Models can be grouped into 3 approaches reflecting their progressive sophistication:
– Classic approach: admin-time
– Modern approach: run-time
– Forward-looking approaches: event-time
We will illustrate each of these approaches with emblematic models, highlighting:
1) The response to an initial need
2) The limitations of the model
We conclude with a chronological summary of the approaches and their models.
Classic authorisation approaches: Admin-time
In the 60s and 70s the development of computer systems, marked by the development of the first multi-user systems (Multics, HP-3000), gave rise to the need to rethink user rights.
Innovative security principles, which are still used today, were defined for these systems such as rings of protection, which aim to protect the integrity of the operating system against deliberate and accidental modifications and initiate a rethink of user access policies to resources.
In the first access rights models to emerge, the management of rights remained summary, defined in hard terms by ‘administrators’: this was admin-time, of which the DAC and MAC (60s-70s) and RBAC (90s) models are particularly noteworthy.
Discretionary Access Control (DAC) and Access Control Lists (ACLs)
As its name suggests, the DAC model – for ‘discretionary access control’ – leaves it up to each resource owner to assign permissions to users. This is the basic rights model found on Unix systems, which can be supplemented by the ACL mechanism, or ‘access control lists’. Often associated with DAC, ACLs specify, for a given resource, the users and their rights over the resource, as illustrated below using the Unix example.

Note that the minimal ACL describes the rights set for the basic Unix rights triplet (owner – owner group – other users), but it can be modified to give rights to additional users or groups, as in this case specific rights for the user ‘alice’. This extends and enables more detailed rights management.
Beyond Unix, file-sharing systems such as OneDrive and social networks, where the user can choose who can view or comment on each publication, are other examples of the use of DACs and ACLs.
In fact, the flexibility and granularity of this model are an advantage for local implementations centred on individuals. On the other hand, they become problematic for ensuring a correct level of resource protection on a large scale in more complex systems.
Mandatory Access Control (MAC)
The MAC model, which stands for Mandatory Access Control, is the opposite of DAC. Rather than leaving the assignment of rights to the ‘discretion’ of individual users, resource by resource, limiting system-wide visibility and encouraging errors and vulnerabilities, rules are predefined by administrators according to different security classifications and strictly enforced by a central authority, generally represented by the operating system itself.
It is particularly prevalent in government, military and industrial environments, because it allows tight control over access to sensitive data. It uses labels that characterise the sensitivity of objects and users, according to the rules of the organisation concerned:
– A resource classification level, for example: ‘Unclassified’, ‘Restricted’, ‘Confidential’, etc.
– A level of user authorisation, linked to the existing resource classification levels.
Below we describe Multics and SELinux, two fundamental examples of MAC implementation.
MAC example 1: Multics and protection rings

Already mentioned above as a precursor of multi-user systems (also known as ‘time-sharing’ systems), the Multics project, released in 1969, was the source of many innovative features, particularly in its memory management and security. It prefigured MAC even before the formulation of models such as Bell-LaPadula (1973) and its first formal definition set out in the Department of Defense’s Orange Book (1983), which established US computer security standards.
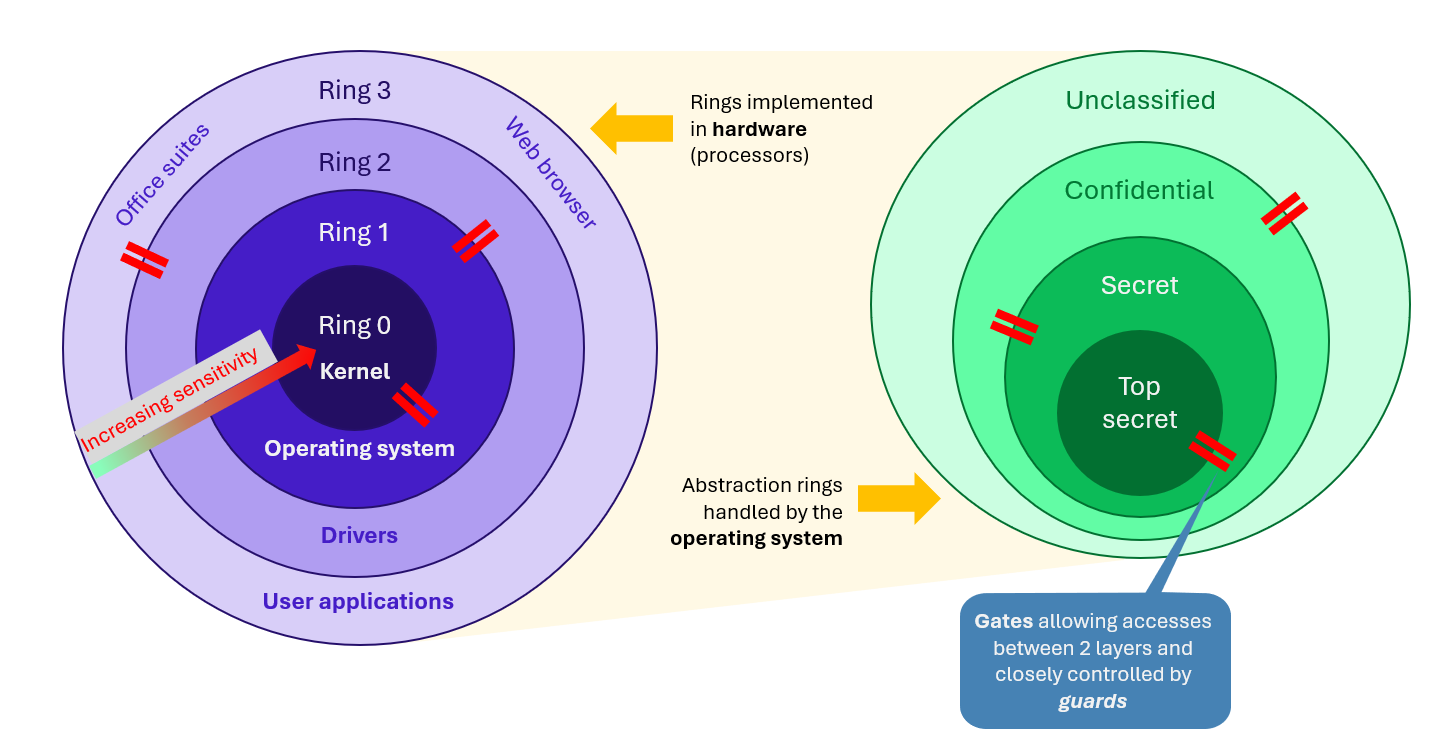
It is based on the concept of rings of protection, which Multics created, as shown by its logo (image above), and which form the basis of MLS – Multi-Level Security – systems, widely used in highly confidential contexts. It consists of a set of concentric rings representing levels of sensitivity that increase the closer you get to the centre (ring 0) – and therefore the privileges required for access. Mechanisms known as guards or gatekeepers, located at the interface between two rings, closely control the legitimacy of access in both directions, which they grant or deny.
In reality, these rings are of two types:
– Kernel protection rings are physical rings built into processors and used by the operating system to guarantee its integrity against faults (which cause the machine to crash) or modifications, whether intentional or not.
– User space rings are logical rings implemented by the operating system. This is where MAC comes in. By means of labels, each user and each resource is attached to a ring level. From there, rules define the actions that can or cannot be taken, following the example of the Bell-LaPadula model, which emphasises data confidentiality: ‘No read up’ (a user cannot read access to layers higher than his own), ‘No write down’ (he cannot write to layers lower than his own, to avoid leaks).
The image below summarises the principle of protection rings.
MAC example 2: SELinux, the Linux kernel security module

Initially developed by the NSA in 2001, SELinux was proposed and added to the Linux kernel security modules (LSM, Linux Security Modules) in 2003, and is natively integrated into RedHat distributions such as Fedora.
This is another well-known example of MAC implementation: it allows administrators to assign a security context label to each resource in order to classify them and define the security policies to be applied by the operating system. Even with privileged rights, an application will see its rights restricted to the domain it needs to function (for example, the folders specified), with SELinux detecting and preventing any non-compliant action.
SELinux therefore provides an additional layer of protection in the event that a user or process manages to bypass traditional access controls.
In practice, MAC policies are rarely sufficient on their own, but are superimposed on existing DAC rules, whose flexibility they compensate for.
Two models based above all on the identity of the user or process, on the basis of which they authorise or deny access: this is known as Identity-Based Access Control (IBAC). These models are still limited to local contexts and have little resistance to scaling up.
Role-based Access Control (RBAC)
Formulated in 1992 by David FERRAIOLO and Richard KUHN, two engineers from the American NIST, the RBAC model – role-based access model – was designed to simplify the management of permissions throughout an organisation while reflecting its structure as closely as possible (hierarchy, responsibilities, departments, etc.).
Instead of granting rights directly to an identity, as with IBAC, a method that can quickly become difficult to maintain, we design business roles and the associated privileges. Users then inherit the rights associated with their role within the company, enabling them to access the various applications and enterprise sharing systems considered necessary for their internal activities.
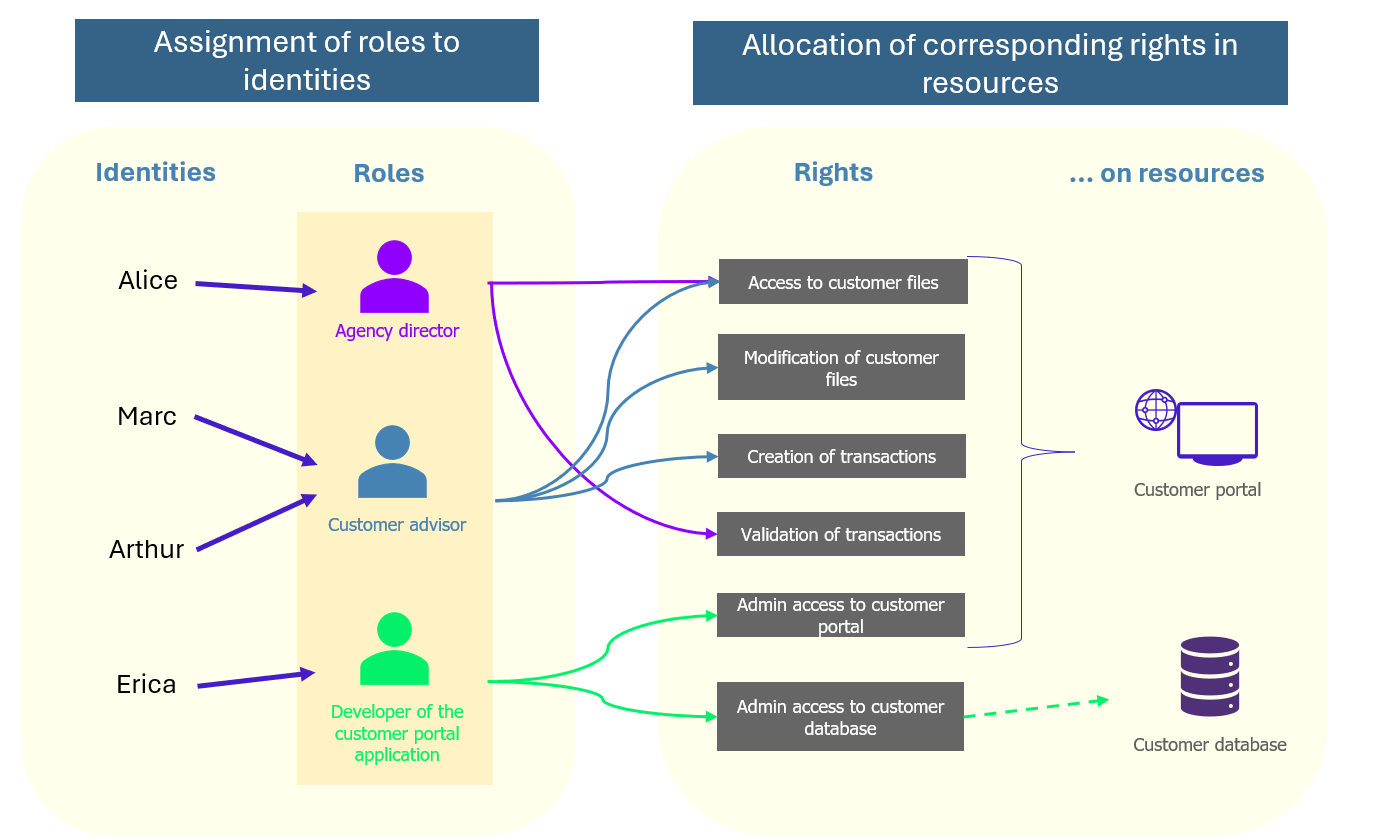
This initial conceptual framework was completed and standardised in 2004 with the ANSI INCITS 359-2004 standard, which takes into account practical business cases and scenarios. For example, it addresses the need to separate responsibilities (SoD, Segregation of Duty), which is fundamental in financial and banking institutions, as well as the principle of least privilege and the inheritance of permissions.
Progressive and increasingly centralised adoption of RBAC
From the 80s and 90s onwards, databases, which were widely adopted by large companies and likely to contain sensitive information to which access was naturally controlled, were pioneers in the implementation of the RBAC model. They illustrate its implementation at the level of isolated applications, with no repercussions for external applications or systems.
The 2000s saw the launch of Microsoft’s Active Directory, starting with Windows 2000 Server. This centralised directory is designed to manage all the organisation’s resources (people, physical resources, applications). Although it is not strictly speaking an RBAC tool, a comparison can be made. The allocation of access rights is based on security groups – which can be perceived as roles – with permission inheritance mechanisms and the concepts of domains, trees and forests designed to represent the logical structures of the company.
Modern IAM solutions, such as Okta, SailPoint IIQ and Microsoft AzureAD, now support RBAC for heterogeneous environments, including cloud services. They illustrate the gradual centralisation of access rights management, which was initially managed locally within applications, and is now increasingly delegated to IAM solutions covering the widest possible spectrum.
RBAC assigns rights based on a business role, whereas IBAC is linked to an identity. The layer of abstraction created between the subject’s identity and an individual’s role means that it can be extracted from restricted contexts (file systems for DAC, operating systems for MAC) and adapted (at last!) to the access control needs of organisations. However, they all share the characteristic of a rigid definition of rights, based on an identity or a role.
In entities where exchanges are increasingly dynamic and fluctuating, this abstraction through roles alone may prove insufficient. New models have emerged to represent more complex organisations, taking into account additional, evolving attributes to assess access rights to a higher accuracy at a given time: we are moving from admin-time to run-time.
New approaches to authorisation: Run-time
The increasing complexity of information systems, and therefore of access, has led to the run-time approach. This approach meets organisations’ needs for dynamic flexibility and security. Unlike the ‘admin-time’ era, characterised by static permissions, the ‘run-time’ era offers real-time management at the time of the access request, based on various contextual elements. This transition to more flexible and precise authorisation models enables organisations for adapting to change and better protect their resources against today’s threats.
Graph-Based Access Control (GBAC)
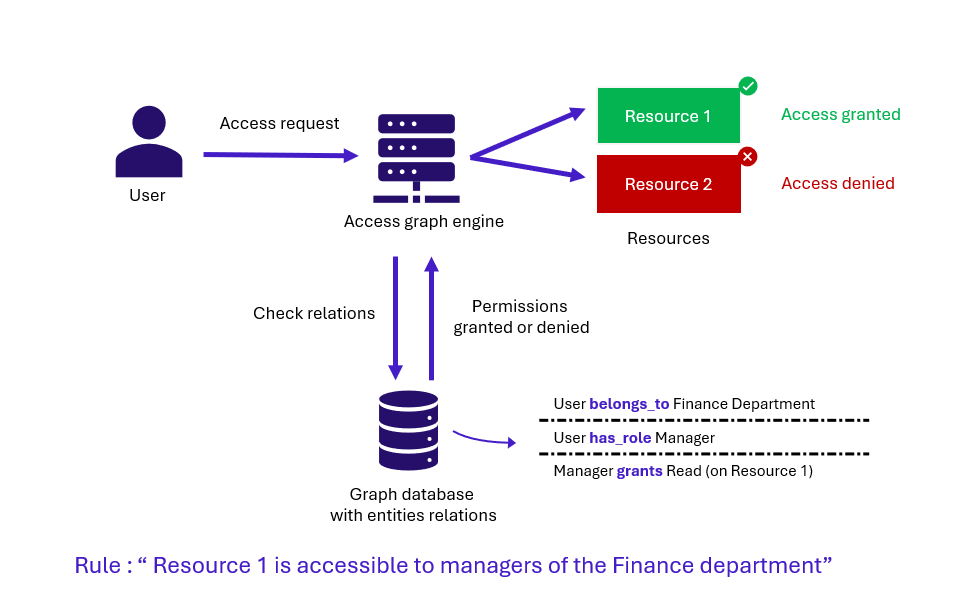
The GBAC (Graph-Based Access Control) or GraphBAC model is based on the use of graphs to represent the relationships between users, roles and resources within an organisation. These 3 types of entities (users, roles, resources) and the relationships between them form the core of this model: entities can be represented by the nodes of the graph, and the relationships between them by the edges.
Access authorisations to a resource are determined in real time by queries to this graph database, enabling access decisions to be made based on the connections between entities at the time of the request. Users can thus obtain access to a resource according to their role and their relationships with other users or resources in the organisation.
The GBAC model is suited to the dynamic environments of large organisations, where relationships between entities are constantly evolving. On the other hand, it can be complex to implement, and the projects involved are relatively long, with significant costs. In addition, the gradual addition of new relationships can make the graph increasingly difficult to manage, complicating internal audit or recertification activities, for example.
Attribute-Based Access Control (ABAC)
In the ABAC (Attribute-Based Access Control) access model, the management of access to a resource is based on the dynamic combination of attributes. These attributes relate to the user requesting access (role, group), the resource requested (type of resource) and the context in which the request is made (time of day, type of network). This approach makes it possible to authorise or deny access flexibly and in real time.
The model was formalised in 2014 in the publication by NIST (SP 800-162) which provides detailed information for its implementation.
4 components are essential to the operation of this model: Policy Enforcement Points (PEPs), Policy Decision Points (PDPs), Policy Administration Points (PAPs) and Policy Information Points (PIPs).
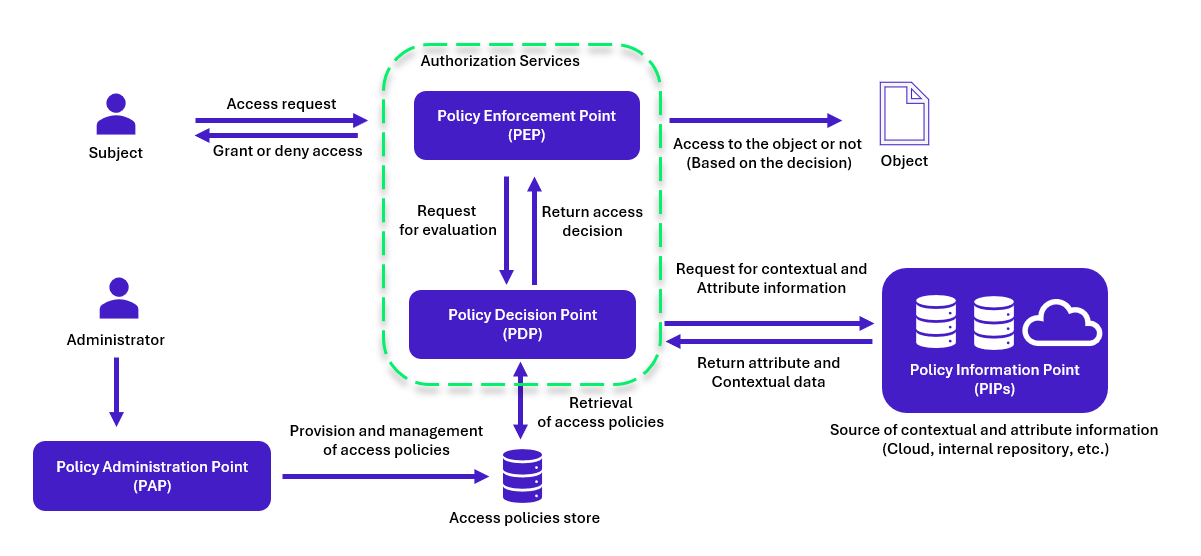
After interception by the PEP, the access request is transmitted to the PDP, which is responsible for making decisions by analysing the access policies managed by the PAP and often accessible from an access policy database. The PIP provides the PDP with additional information on the user or resource from different sources, enabling it to make decisions in line with access rules. For contextual information, the information system can be connected to other tools or sources (IDS, logs, sensors) that enable this information to be collected at the time of an access request.
ABAC is a particularly interesting model in environments where access needs are varied and evolving, as it enables fine, granular management of authorisations, particularly in the context of PAM (Privileged Access Management), concerning access and critical resources.
However, this level of detail and flexibility comes with challenges such as the ongoing review of attributes and the maintenance of policies, which require constant attention to ensure they meet the needs of the business. Over time, the increasing number of attributes and conditions can make it difficult to maintain a clear and functional ABAC architecture, especially in environments undergoing constant transformation.
In current ABAC architectures, PEPs are generally designed to work only with PDPs from the same vendor, using proprietary protocols, with no support for compatibility between different vendors.
Standardizing the way these different PEPs and PDPs interact, in order to improve system interoperability and reduce dependence on a single supplier, is the aim of the OpenID AuthZEN working group.
OpenID AuthZEN: towards improved interoperability
AuthZen is a working group initiative launched in 2023 by the OpenID Foundation to standardize the interactions between PEPs and PDPs, in order to improve interoperability between systems from different suppliers.
This initiative responds to current problems where authorization services (PEPs and PDPs) are often designed to work only with solutions from the same vendor, limiting their interoperability.
AuthZen was launched to develop a standardised protocol that would facilitate integration and communication between PEPs and PDPs, reducing dependency on single vendor solutions and improving overall authorisation security.
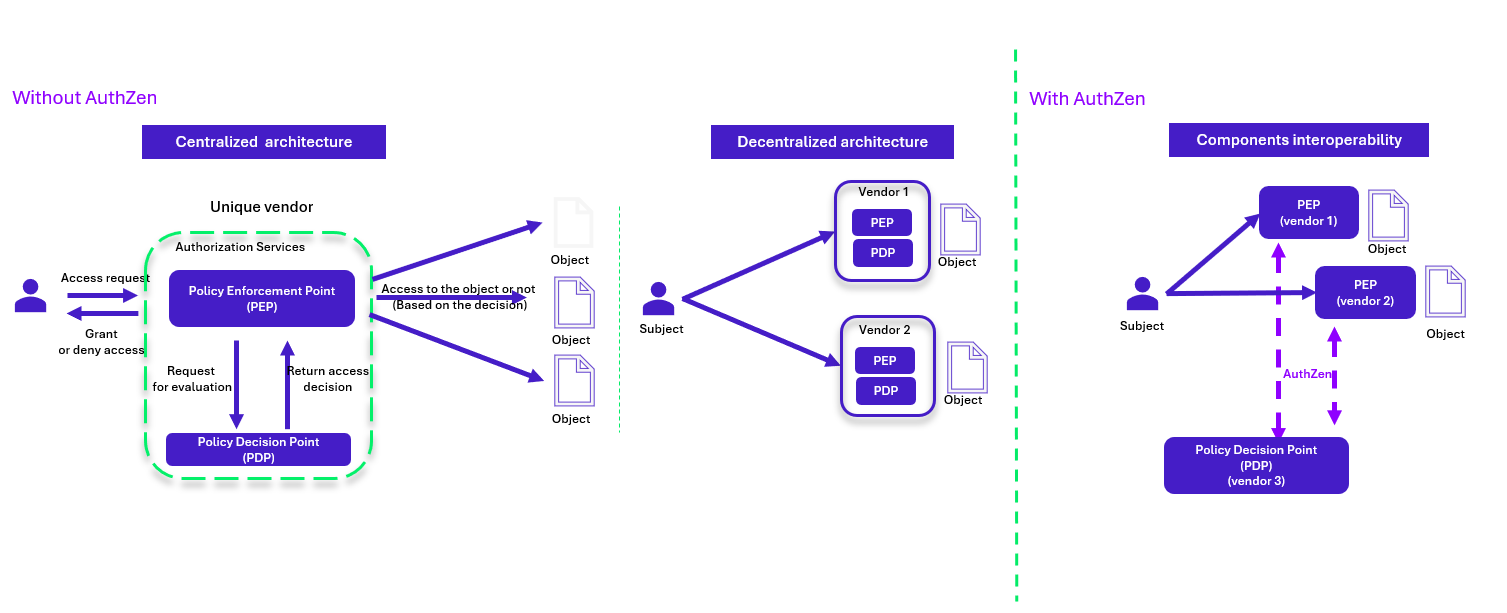
To make these interactions more flexible and universal, AuthZen relies on existing architectures and technologies (OPA/Rego, XACML, etc.) to improve deployment, scalability and interoperability. The first two stages of this standardisation with Open ID AuthZen are the implementation of a simple ‘Request/Response’ and ‘Permit/Deny’ type protocols and a multiple decision approach in order to group several authorisation requests into a single request and receive several decisions in return.
The AuthZen think tank includes security players such as 3Edges, Axiomatic and others. It is also open to players who want to develop authorisation systems and make architectures more secure and interoperable.
Prospects for the evolution of authorisation: Event-time
A new approach to the evolution of access systems is event-time. It is defined as an implementation of dynamic authorisation where access rights are adjusted in real time in response to immediate events or changes that occur. Unlike static or attribute-based approaches, event-time is characterised by a continuous evaluation of access rights, to ensure that all access remains compliant with the policies in place within the organisation.
For example, when a user’s status changes (promotion, departure, mobility, etc.), the system automatically adjusts or revokes their access rights. This proactive, event-based adjustment approach is common in information systems monitoring and security incident management.
Event-time is based on the following key concepts:
– Listeners: system components that monitor events in time and analyse important changes (mobility, promotions, departures, etc.) from various sources, in particular HR systems.
– Triggers: actions in response to an event identified by a listener, such as the revocation of access rights on the actual day a user leaves.
– Shared Signals: enabling different systems to share information about events in real time.
– Continuous evaluation: constant checking of access rights to ensure that each action or access remains in compliance with policies.
Frameworks and standards play a key role in implementing event-time by providing a structure for implementing the concepts in systems:
The Shared Signals Framework (SSF) is directly linked to the concept of shared signals, which enables systems via an API to share information about events in real time to ensure consistent access management. The continuous evaluation of this information is supported by CAEP (Continuous Access Evaluation Protocol), a protocol for standardising the writing of status changes. RISC (Risk and Incident Sharing and Coordination) is a generic protocol for standardising the transmission and reception of security incidents between these different systems, thereby enhancing the overall responsiveness of an information system.
Event-time is not based on a specific model such as RBAC or ABAC, but can function as a complementary access management layer to these traditional access systems, making them more dynamic and aligned with real-time situations.
The evolution of authorisation models, from traditional approaches to modern, dynamic methods, reflects the ongoing adaptation of IAM and access systems to the growing and changing needs of organisations.
Admin-time approaches laid the foundations for resource security with models such as DAC and MAC. RBAC introduced structured rights management, which is widely adopted in organisations today due to its relatively simple application.
With the advent of the runtime, access decisions became more refined, based on attributes specific to users, resources and context, as with the ABAC and GBAC models. However, these increasingly sophisticated models have led to the emergence of numerous proprietary solutions, limiting the interoperability of authorisation components and creating a dependency on specific technologies. This has led to the emergence of initiatives such as the AuthZen working group, which is working to develop standards.
The event-time approach provides real-time responsiveness, enabling systems to automatically adjust access in response to specific events. CAEP and the Shared Signals Framework facilitate this dynamic by standardising the exchange of information between systems, thereby strengthening security and compliance.
An overview of these different approaches and their associated models is presented in the timeline below, together with a summary table of the different models discussed.
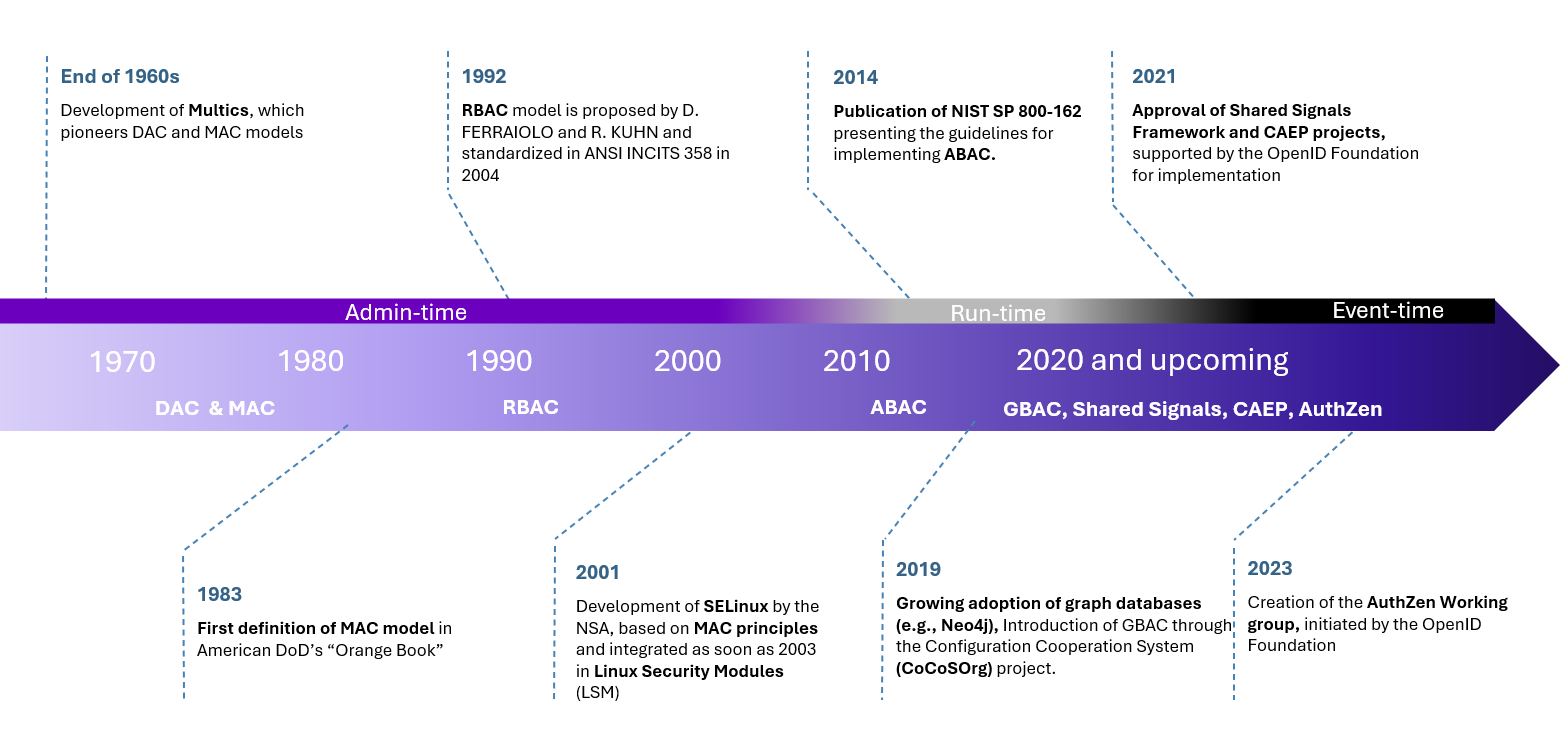
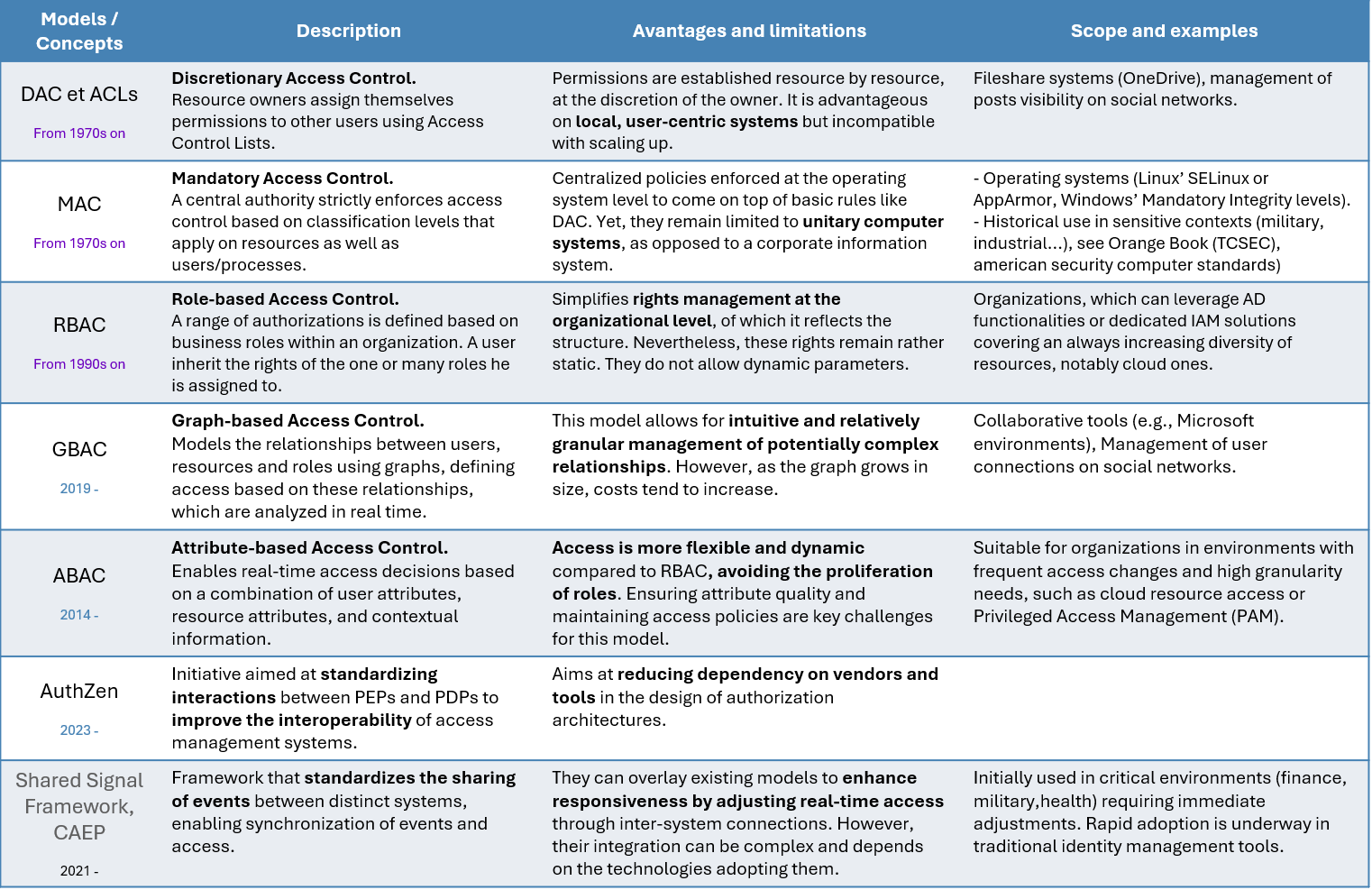
By combining these different approaches, you can implement more secure, flexible and proactive access management, capable of responding to current and future identity-related challenges. These developments also highlight the importance of adopting adaptive and interoperable authorisation solutions to ensure effective protection of resources while meeting the operational requirements of teams.
These developments raise an essential question about the ability of organisations to anticipate these changes and integrate these new access management dynamics.
Whether you are still using admin-time models, exploring runtime options, or considering moving to event-time management, it is crucial to choose a model that meets your specific needs. It is also very important to anticipate the consequences for the management of this model over time (review of rights, measurement of data quality, review of policies, definition of expected reactions, etc.).
What type of model do you use?
Don’t hesitate to contact us to find out more and understand how to apply these authorisation models to your organisation’s context!


{kind=link}
{kind=link}