
Ever since the launch of ChatGPT in November 2022, many companies began developing and releasing their own Large Language Models (LLMs). So much so that we are currently in a phase that many experts describe as an “AI Race”. Not just between companies – but countries and international organizations as well. This AI race describes the global frenzy to build better models alongside the guidelines and regulations to handle them. But what exactly is a better model?
To answer this question, researchers and engineers from around the world came up with a standardized system to test LLMs in various settings, knowledge domains and to quantify it in an objective manner. These tests are commonly known as “Benchmarks”, and different benchmarks reflect very different use cases.
However, for the average user, these benchmarks alone don’t mean much. There is a clear lack of awareness for the end-user: a 97.3% result in the “MMLU” benchmark is hard to read and to transpose into their daily tasks.
To avoid such confusions, the article introduces factors that limit down a user’s LLM choice, the most popular and widely used LLM benchmarks, their use cases and how they can help users choose the most optimal LLM for themselves.
Factors that Impact LLM Choice
Various factors impact to quality of the model: the cut-off date and internet access, multi-modality, data privacy, context window, and speed and parameter size. These factors must be solidified first before moving on to benchmark assessments and model comparison since they limit which models you can use in the first place.
Cut-off Date and Internet Access
Almost all models on the market have a knowledge cut-off date. This is the date where data collection for model training ends. For example, if the cut-off date is September 2021, then the model has no way of knowing any information after that date. Cut-off dates are usually 1-2 years before the model has been released.
However, to overcome this issue, some models such as Copilot (GPT4) and Gemini have been given access to the internet, allowing them to browse the web. This has allowed models with cut-off dates to still have access to the most recent news and articles. This also allows the LLMs to provide the user with references which reduces the risk of hallucination and makes the answer more trustworthy.
Nevertheless, internet access is a product of the model’s packaging rather than the model itself, thus it is limited to models on the internet, primarily closed-source cloud-hosted ones. For this reason, it is important to consider what your needs are and if having up-to-date information is really all that important in achieving your goals.
Multi-Modality
Different applications require different uses for LLMs. While most of us use them for their text generation abilities, many LLMs are in fact able to analyze images, and voices and reply with images as well.
However, not all LLMs have this ability. The ability to analyze different forms of input (text, image, voice) is “multi-modality”. This is an important factor to consider since if your task requires the analysis of voice messages or corporate diagrams then it is important to look for models that are multi-modal such as Claude 3 and ChatGPT.
Data Privacy
A risk of using most models in the market right now is data privacy and leakage. More specifically, data privacy and safety in LLMs can be separated into two parts:
- Data privacy in pre-training and fine-tuning, this is whether the model has been trained on data that contains PIIs and if it could leak those PIIs during chats with users. This is a product of the model’s training dataset and fine-tuning process.
- Data privacy in re-training and memory, this is whether the model would use chats with users to re-train, potentially leaking information from one chat to another. However, this risk is only limited to some online models. This is a product of the packaging of the model and the software layer(s) between the model and the user.
Context Window
Context Window refers to the number of input tokens that a model can accept. Thus, a larger context window means that the model can accept a larger input text. For example, the latest Google model, the Gemini 1.5 pro, has a 1 million token context window which gives it the ability to read entire textbooks and then answer you based on the information in the textbooks.
For context, a 1 million token window allows the model to analyze ~60 full books purely from user input before answering the user prompt.
Thus, it is apparent that models with larger context windows can often be customized to answer questions based on specific corporate documents without using RAG (Retrieval-augmented generation) which is the most common solution for this problem in the market.
However, LLMs often bill users based on the number of input tokens used and thus expect to be billed more when using the larger context window. Additionally, it isn’t common for models to take upwards of 10 minutes before answering when using a larger context window.
Speed and Parameter Size
LLMs have technical variations that can impact the speed of processing the user prompt and the speed of generating a response. The most important technical variation that affects LLM speed is parameter size, which refers to the number of variables the model has internally. This number, usually in billons, reflects how sophisticated a model is but also indicates that the model might require more time to generate a response.
However, the internal architecture of the model also matters. For instance, some of the latest 70B+ parameter models in the market can reply in real-time while some 8B parameter models need minutes to generate a response.
Overall, it is important to consider the trade-off between speed on one hand and parameter size (sophistication and complexity) on the other, although this is also highly dependent on the internal model architecture and the environment it is used in (API, Cloud service, or self-deployed etc.)
Nevertheless, speed specifically is a key distinguisher that borders the line between factor and benchmark since it is measured and used to compare the different STOA models. However, speed isn’t a standardized pragmatic form of assessment and for this reason isn’t considered a benchmark.
Next Steps
After having reviewed the factors, users can now limit their LLM choice and use the benchmarks covered in the next section to help them choose the most optimal model. This helps the user maximize their efficiency and only benchmark the models that are relevant to them (from a cut-off date, speed, data privacy, etc. perspective).
How Benchmarks are Conducted
Benchmarks are tools used to assess LLM performance in a specific area. Benchmarks can be conducted in different ways – the key distinguisher being the number of example question-answer pairs the LLM is given before it is asked to solve a real question.
Benchmarks assess the LLM’s ability to do a certain task. Most benchmarks will ask an LLM a question and compare the LLM’s answer with a reference correct answer. If it matches, then the LLM’s score increases. In the end, the benchmarks output an Acc/Accuracy score which is a percentage of the number of questions an LLM answered correctly.
However, depending on the method of assessment, the LLM might get some context on the benchmark, type of questions or more. This is done through multi-shot or multi-example testing.
Multi-shot Testing
Benchmarks are conducted in three distinct ways.
- Zero-Shot
- One-Shot
- Multi-shot (often multiples of 2 or 5)
Where shots refer to the number of times a sample question was given to the LLM prior to its assessment.
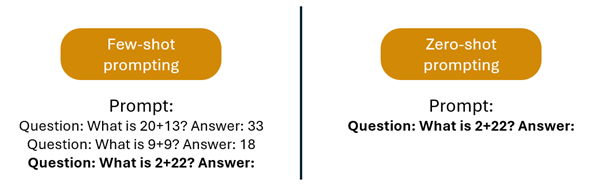
Figure 1: illustration of 3-shot vs. 0-shot prompting
The reason we have different-shot testing is because certain LLMs outperform others in short-term memory and context usage. For example, LLM1 could have been trained on more data and thus outperforms LLM2 in zero-shot prompting. However, LLM2’s underlying technology allows it to have a superior reasoning, and contextualizing ability that would only be measured through one-shot or multi-shot assessment.
For this reason, each time an LLM is assessed, multiple shot settings are used to ensure that we get a complete understanding of the model and its capabilities.
For instance, if you are interested in finding a model that contextualizes well and is able logically reason through new and diverse problems, consider looking at how the model’s performance increases as the number of shots increases. If a model has significant improvement, it means that it has a strong ability to reason and learn from previous examples.
Key Benchmarks and Their Differentiators
Many benchmarks often evaluate the same thing. Thus, it is important when looking at benchmarks to understand what they are assessing, how they are assessing it and what its implications are.
Massive Multitask Language Understanding (MMLU)

Figure 2: example of an MMLU question
MMLU is one of the most widely used benchmarks. It is a large multiple-choice question format dataset that covers 57 unique subjects at an undergraduate level. These subjects include Humanities, Social Sciences, STEM and more. For this reason, MMLU is considered as the most comprehensive benchmark for testing an LLM’s general knowledge across all domains. Additionally, it is also used to find gaps in the LLMs pre-training data since it isn’t rare for an LLM to be exceptionally good at one topic and underperforming in another.
Nevertheless, MMLU only contains English-language questions. So, a great result in MMLU doesn’t necessarily translate to a great result when asking general knowledge questions in French, or Spanish. Additionally, MMLU is purely multiple choice which means that the LLM is tested only on its ability to pick the correct answer. This doesn’t necessarily mean the LLM is good at generating coherent, well-structured, and non-hallucinatory answers when prompted with open-ended questions.
An MMLU result can be interpreted as the percentage of questions that the LLM was able to answer correctly. Thus, for MMLU, a higher percentage is a better score.
Generally, a high average MMLU score across all 57 fields indicates that the model was trained on a large amount of data containing information from many different topics. Thus, a model performing well in MMLU is a model that can effectively be used (perhaps with some prompt engineering) to answer FAQs, examination questions and other common everyday questions.
HellaSwag (HS)

Figure 3: example of a HellaSwag question
HellaSwag is an acronym for “Harder Endings, Longer contexts, and Low-shot Activities for Situations with Adversarial Generations”. It is another English-focused multiple choice massive (10K+ questions) benchmark. However, unlike MMLU, HS does not assess factual or domain knowledge. Instead, HS focuses on coherency and LLM reasoning.
Questions like the one above challenge the LLM by asking it to choose the continuation of the sentence that makes the most human sense. Grammatically, these are all valid sentences but only one follows common sense.
The reason this benchmark was chosen is because it works in tandem with MMLU. While MMLU assesses factual knowledge, HS assesses whether the LLM would be able to use that factual knowledge to provide you with coherent and sensical responses.
A great way to visualize how MMLU and HS are used is by imagining the world we live in today. We have engineers and developers that possess great understanding and technical knowledge but have no way to communicate it properly due to language and social barriers. Because of this, we have consultants and managers that may not possess the same depth of knowledge, but instead have the ability organize, and communicate the engineers’ knowledge coherently and concisely.
In this case, MMLU is the engineer and HS is the consultant. One assesses the knowledge while the other assesses the communication.
HumanEval (HE)

While MMLU and HS test the LLM’s ability to reason and answer accurately, HumanEval is the most popular benchmark to purely assess the LLM’s ability to generate useable code for 164 different scenarios. Unlike the previous two, HumanEval is not multiple choice based and instead allows the LLM to generate its own response. However, not all responses are accepted by the benchmark. Whenever an LLM is asked to code a solution to a scenario, HumanEval tests the LLM’s code with a variety of test and edge cases. If any of these test cases fail, then the LLM fails.
Additionally, HumanEval also expects that the code generated by the LLM is algorithm optimized for time and space. Thus, if an LLM outputs a certain algorithm while there is a more optimal algorithm available then it loses points. Because of this reason, HumanEval also tests the LLM’s ability to accurately understand the question and respond in a precise manner.
HumanEval is an important benchmark, even for non-technical use cases since it accurately reflects LLM’s general sophistication and quality in an indirect way. For most models, the target audience is developers and tech enthusiasts. For this reason, this is a strong positive correlation between greater HumanEval scores and greater scores in many other benchmarks signifying that the model is of higher quality. However, it is important to keep in mind that this is merely a correlation, not a causation, and so things might differ in the future as models start targeting new users.
Chatbot Arena

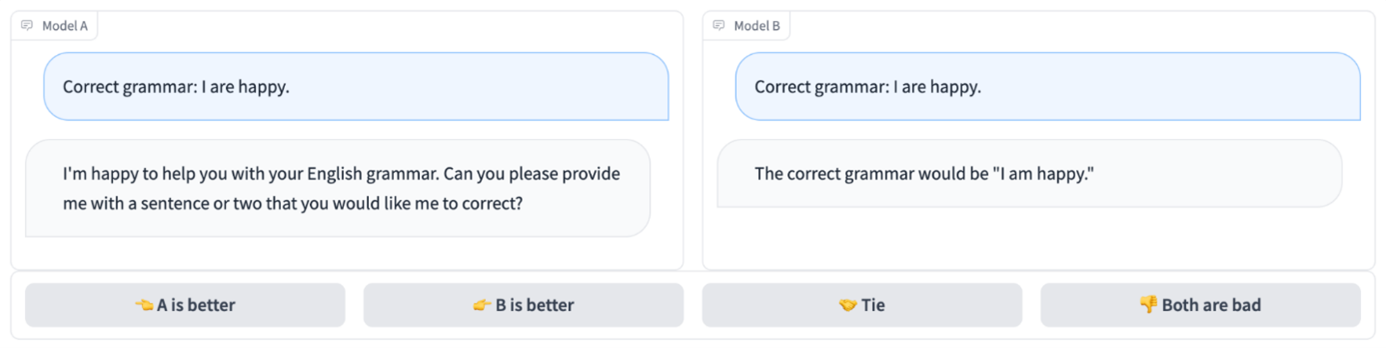
Figure 4: example of Chatbot Arena interface
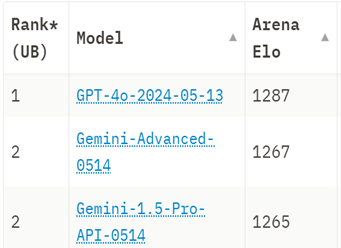
Figure 5: Chatbot Arena July 2024 rankings
Unlike the past three benchmarks, Chatbot arena is not an objective benchmark, but a subjective ranking of all the available LLMs in the market. Chatbot Arena collects users’ votes and determines which LLM provides the best overall user experience including the ability to maintain complex dialogues, understand user inquiries and other customer satisfaction factors. Chatbot Arena’s subjective nature makes it the best benchmark assessing the end-user experience. However, this subjectivity also makes it non-reproducible and difficult to really quantify.
The current user rankings put OpenAI’s GPT-4o at the top of the list with a sizable margin between it and second place. This ranking has great merit since it is collected from the opinion of 1.3M user votes. However, these voters are primarily from a tech background and thus the ranking might be biased towards models with greater coding abilities.
The rankings are built on top of the ELO system, which is a zero-sum system where models gain ELO by producing better replies than their opposing model and the opposing model loses ELO.
Overall benchmarking
Benchmarks can have internal biases and limitations. Benchmarks can be used together to better represent the model’s capabilities. Newer models are more advantaged because of their architecture, training data size, and leakage of benchmark questions.
The three + one (chatbot arena) benchmarks mentioned are the most popular and widely used in research to compare LLMs. The combination mentioned (MMLU, HellaSwag, HumanEval and Chatbot Arena) assess many sides of the LLM, from its factual understanding and coherence to coding and user experience. For this reason, these four benchmarks alone are widely used in many rankings online since they are able to reflect the true nature of the LLM.
However, one thing to consider is that the newest LLM models are heavily advantaged because of two primary reasons.
- They are built on a more robust architecture, have better underlying technologies and have more data to train on due to later cut-off dates and larger hardware capacity.
- Many questions from the benchmarks have leaked into the model’s training data.
Nevertheless, there are many more benchmarks available on the net that assess different parts of the LLM and are often used in tandem to paint a complete picture of the model’s performance.
Factors, Benchmarks and How to Choose Your LLM
By using the aforementioned factors and benchmarks, you can effectively compare LLMs in a quantifiable and objective way – helping you make an informed decision and choose the most optimal model for your business need and task.
Additionally, each of the above benchmarks has strengths and weaknesses that make them unique and great in different aspects. However, at Wavestone we recognize the importance of diversification to minimize risk. For this reason, we developed a checklist that allows users to make a more informed decision when it comes to choosing a set of benchmarks to follow and using them to compare the latest models. The checklist covers a wide variety of domains, benchmarks and factors that give the end-user more granular control over their benchmark choice.
The tool, also a priority tracker, allows users to set different weights for the benchmarks to accurately reflect their business needs and task natures. For example, a consultant might prioritize multi-modality for diagram and chart analysis over mathematical skills and thus give multi-modality a higher weighting.
Finishing thoughts
In the rapidly evolving landscape of LLMs, understanding the nuances of different models and their capabilities is crucial. Before considering any LLM, several factors must be taken into consideration, including cut-off date, data privacy, speed, parameter size, context window, and multi-modality. After considering these factors, users can consult different benchmarks to make a more informed decision. The ones covered in this article, MMLU, HellaSwag, HumanEval, and Chatbot Arena, provide a robust system to quantitatively evaluate these models in various domains.
In conclusion, the AI Race is not just about developing better models but also about leveraging and using these models effectively. The journey of choosing the most optimal LLM is not a sprint but a marathon, requiring continuous learning, adaptation, and strategic decision-making through benchmarking and testing. As we continue to explore the potential of LLMs, let us remember that the true measure of success lies not in the sophistication of the technology but in its ability to add value to our work and lives.
Acknowledgements
We would like to thank Awwab Kamel Hamam for his contribution to this article.
Further Reading and Reference
[1] D. Hendrycks et al., “Measuring Massive Multitask Language Understanding.” arXiv, 2020. doi: 10.48550/ARXIV.2009.03300. Available: https://arxiv.org/abs/2009.03300
[2] D. Hendrycks et al., “Aligning AI With Shared Human Values.” arXiv, 2020. doi: 10.48550/ARXIV.2008.02275. Available: https://arxiv.org/abs/2008.02275
[3] M. Chen et al., “Evaluating Large Language Models Trained on Code.” arXiv, 2021. doi: 10.48550/ARXIV.2107.03374. Available: https://arxiv.org/abs/2107.03374
[4] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi, “HellaSwag: Can a Machine Really Finish Your Sentence?” arXiv, 2019. doi: 10.48550/ARXIV.1905.07830. Available: https://arxiv.org/abs/1905.07830
[5] W.-L. Chiang et al., “Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference.” arXiv, 2024. doi: 10.48550/ARXIV.2403.04132. Available: https://arxiv.org/abs/2403.04132

