
Avec l’essor des grands modèles de langage (LLM) et la multiplication des cas d’utilisation de l’IA dans les organisations, il est crucial de savoir comment protéger vos systèmes et applications d’IA. Cela permet non seulement de garantir la sécurité de votre écosystème, mais aussi d’en optimiser l’utilisation au service de l’entreprise.
MITRE, connu pour son cadre ATT&CK, une taxonomie largement adoptée par les centres d’opérations de sécurité (SOC) et les équipes de renseignement sur les menaces, a développé un cadre spécifique appelé MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems). Ce cadre constitue une base de connaissances sur les tactiques et techniques employées par les adversaires ciblant les systèmes d’intelligence artificielle. Il permet de classifier les attaques et menaces tout en offrant un outil structuré pour évaluer ces dernières de manière cohérente.
Cependant, le paysage des menaces liées à l’IA est complexe, et il n’est pas toujours facile de déterminer les actions que les équipes doivent entreprendre pour protéger un système d’IA. Le cadre ATLAS de MITRE identifie 56 techniques susceptibles d’être exploitées par des adversaires, rendant l’atténuation des risques d’autant plus difficile en raison de la nécessité de déployer des contrôles tout au long de la chaîne d’exécution. Les équipes devront mettre en place des contrôles ou des mesures d’atténuation couvrant plusieurs phases, allant de la reconnaissance à l’exfiltration, en passant par l’évaluation de l’impact.
 Fig. 1. Chaîne d’exécution de MITRE ATLAS.
Fig. 1. Chaîne d’exécution de MITRE ATLAS.
Cette complexité a amené bon nombre de nos clients à se poser des questions telles que : « Je suis responsable de la gestion des identités et des accès. Que dois-je savoir et, surtout, que dois-je faire au-delà de ce que je fais actuellement ?
Pour répondre à ces préoccupations, nous avons analysé en détail le cadre MITRE ATLAS afin d’identifier les types de contrôles que les différentes équipes doivent envisager pour atténuer les effets de chaque technique répertoriée. Cette analyse nous permet d’évaluer si les contrôles en place sont suffisants ou si de nouveaux contrôles doivent être développés et mis en œuvre pour sécuriser les systèmes et applications d’IA. Nous estimons que les contrôles d’atténuation des menaces pesant sur les systèmes d’IA se répartissent comme suit : 70 % reposent sur des contrôles existants, qui peuvent être adaptés à l’IA, tandis que 30 % nécessitent le développement de nouveaux contrôles, spécifiquement conçus pour répondre aux menaces uniques liées à l’IA.
Pour simplifier l’articulation des besoins en matière de contrôle, nous avons défini trois catégories :
- Domaines verts : les contrôles existants suffisent pour couvrir certaines menaces posées par l’IA. Bien qu’il puisse y avoir des ajustements mineurs, le principe de base reste inchangé, sans besoin d’évolution majeure.
- Domaines jaunes : les contrôles en place doivent être adaptés ou ajustés pour couvrir efficacement les menaces spécifiques à l’IA.
- Domaines rouges : de nouveaux contrôles doivent être entièrement conçus et mis en œuvre pour répondre aux menaces inédites introduites par l’IA.
Ce cadre permet aux organisations de prioriser leurs efforts et de s’assurer que leurs systèmes d’IA sont protégés de manière proactive et complète.
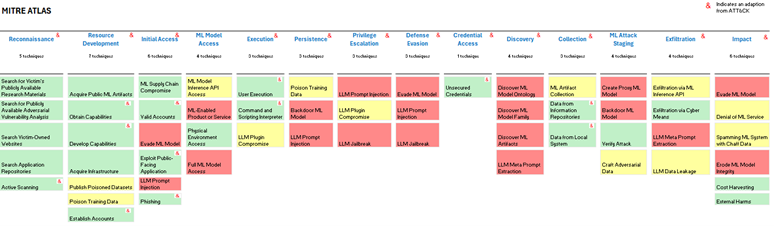
Fig. 2. Analyse RAG des contrôles d’atténuation pour les techniques MITRE ATLAS.
Domaines verts
Les domaines verts correspondent aux risques déjà couverts par les contrôles existants. Trois domaines principaux appartiennent à cette catégorie : la gestion des identités et des accès (IAM), la sécurité des réseaux et la sécurité physique.
Dans le cadre de la gestion des identités et des accès (IAM), le principe fondamental reste de garantir que seules les personnes autorisées ont accès aux ressources appropriées. Toutefois, lorsqu’il s’agit d’une application d’IA, des nuances supplémentaires doivent être prises en compte. Il est essentiel de gérer non seulement l’accès à l’application elle-même, en précisant qui peut l’utiliser, accéder au code source et à l’environnement, mais aussi l’accès aux données utilisées pour entraîner le modèle et aux données d’entrée nécessaires à la génération des résultats.
En matière de sécurité des réseaux, les mécanismes de détection et de réponse continuent de jouer un rôle clé, en signalant toute activité inhabituelle, telle que des requêtes provenant d’emplacements suspects ou l’exfiltration de grandes quantités de données. Bien que les principes restent les mêmes, les types d’attaques peuvent différer dans le contexte de l’IA. Par exemple, un volume important de requêtes dans une application traditionnelle pourrait indiquer une attaque par force brute, alors que pour une application d’IA, cela pourrait refléter une tentative de « récolte de coûts ». Cette dernière consiste à envoyer des requêtes inutiles pour augmenter les coûts d’exécution de l’application, une menace qui peut être atténuée en limitant le nombre de requêtes autorisées. Bien que la détection au niveau de l’application et l’analyse forensic des systèmes d’IA soient plus complexes que pour des applications traditionnelles, les processus de détection au niveau réseau restent similaires. Par ailleurs, les API intégrées au modèle doivent être sécurisées afin de garantir la sécurité des interactions réseau, en particulier lorsqu’elles concernent des applications accessibles publiquement.
Les contrôles de sécurité physique restent les mêmes ; il s’agit de sécuriser les personnes qui ont un accès physique à l’infrastructure clé.
Domaines jaunes
Les contrôles et les mesures d’atténuation qui relèvent des domaines jaunes suivront les mêmes principes que pour les logiciels traditionnels, mais devront être adaptés pour assurer la sécurité contre la menace posée par l’IA. Les équipes qui entrent dans cette catégorie sont l’éducation et la sensibilisation, la résilience, le centre d’opérations de sécurité et le renseignement sur les menaces.
Pour les équipes responsables de la sensibilisation et de l’éducation, les techniques utilisées resteront les mêmes, comme les campagnes de sensibilisation ou les tests d’hameçonnage. Toutefois, il sera essentiel de mettre à jour ces initiatives pour refléter les nouvelles menaces. Par exemple, intégrer des « deepfakes » dans les simulations de tests d’hameçonnage ou inclure des formations spécifiques pour les équipes de développement sur les menaces émergentes liées à l’IA. Ces ajustements garantiront que les équipes sont préparées à détecter et à gérer les risques associés à l’utilisation de l’IA.
Pour les équipes chargées de la résilience, bien que les changements soient limités, des ajustements devront être apportés aux processus existants. Par exemple, si un système critique repose sur une application utilisant l’IA, les scénarios de test devront inclure des menaces spécifiques à l’IA. De plus, les conséquences potentielles d’une attaque contre un système basé sur l’IA, comme les résultats inattendus ou inappropriés d’un chatbot interactif avec des clients, devront être intégrées à la documentation relative à la gestion des crises et incidents. Les lignes directrices en matière de communication devront également être mises à jour pour anticiper et gérer ces nouveaux risques de manière proactive.
Dans le cas des centres d’opérations de sécurité (SOC) et des équipes de renseignement sur les menaces, les principes des contrôles restent centrés sur la collecte de renseignements sur les vulnérabilités et la surveillance des systèmes pour détecter des comportements ou des trafics inhabituels. Cependant, des ajouts spécifiques liés à l’IA seront nécessaires, comme la surveillance des informations concernant les modèles déployés en ligne ou d’autres données exploitables par les attaquants pour accéder au modèle. Cette surveillance est particulièrement critique lorsque le modèle repose sur des solutions open source, telles que ChatGPT, car cela augmente l’exposition potentielle aux menaces.
Domaines rouges
Les domaines rouges regroupent les contrôles et techniques entièrement nouveaux qui doivent être introduits pour répondre aux nouvelles menaces liées à l’IA. Ces contrôles relèvent principalement de la compétence de l’équipe chargée de la sécurité des données et des applications. Il est important de préciser qu’il ne s’agit pas des équipes dédiées à la protection des données, qui se concentrent principalement sur des problématiques telles que le GDPR.
L’équipe chargée de la sécurité des applications dispose de nombreux contrôles dans ce domaine, ce qui souligne l’importance de concevoir les applications basées sur l’IA en appliquant les principes de la sécurité dès la conception. Cependant, certains contrôles spécifiques à l’IA ne relèvent pas des équipes existantes. L’équipe responsable de ces contrôles doit être définie par chaque organisation, mais dans les entreprises les plus avancées, ces contrôles sont souvent pris en charge par un centre d’excellence en matière d’IA.
Les équipes chargées de la sécurité des données jouent un rôle crucial pour garantir que les ensembles de données utilisés pour l’entraînement et les entrées des modèles d’IA ne sont ni empoisonnés ni biaisés, et qu’ils restent fiables et dignes de confiance. Bien que ces contrôles puissent s’inspirer des techniques existantes, ils nécessitent des adaptations spécifiques. Par exemple, les contrôles contre l’empoisonnement des données sont étroitement liés aux mécanismes classiques de gestion de la qualité des données, mais doivent aller au-delà des pratiques standards d’assainissement ou de filtrage.
La qualité des données est un pilier fondamental de la sécurité des applications d’IA. Pour atteindre un niveau de sécurité élevé, il est possible d’intégrer une couche supplémentaire d’IA capable d’analyser les données d’entraînement et d’entrée afin de détecter d’éventuelles manipulations malveillantes. De plus, la tokenisation des données peut offrir un double avantage : elle réduit le risque d’exposition de données privées pendant l’apprentissage ou l’inférence d’un modèle, et elle complique la tâche des attaquants souhaitant introduire des données empoisonnées, en raison de la nature brute des données tokenisées (souvent des caractères ASCII ou Unicode). Par exemple, des algorithmes de tokenisation comme **Byte Pair Encoding (BPE)**, utilisés par OpenAI lors de l’entraînement des modèles GPT, permettent de tokeniser efficacement de grands ensembles de données.
Il est important de garder à l’esprit que l’objectif ne se limite pas à sécuriser les données en tant qu’artefact, mais inclut également l’évaluation de leur contenu et la prévention de leur utilisation malveillante dans la création de résultats biaisés ou ciblés.
Au-delà de la sécurisation des données en entrée, les mesures de sécurité des données doivent être intégrées tout au long du cycle de vie de l’application, notamment lors de la conception et de la construction de l’application, ainsi que lors du traitement des données en entrée et en sortie du modèle.
Dans le cas des applications utilisant un modèle d’apprentissage continu, les contrôles de sécurité des données doivent être maintenus en permanence pendant le fonctionnement de l’application pour garantir la robustesse du modèle. Bien que la sécurisation des données d’entraînement et d’entrée constitue une base essentielle, une couche supplémentaire de sécurité peut être ajoutée en instaurant une équipe d’experts en IA dédiée. Cette équipe testerait régulièrement le modèle en production avec des données adverses, afin d’évaluer et de renforcer sa résilience face à des tentatives de manipulation malveillante.
De plus, des garde-fous paramétriques peuvent être instaurés pour limiter le type de résultats que le modèle est autorisé à produire. Ces mesures renforcent non seulement la sécurité de l’application, mais également la confiance dans les résultats générés par le modèle.
Outre les tests continus pour identifier les vulnérabilités des modèles, les équipes chargées de la sécurité des applications doivent veiller à ce que le système soit conçu selon les principes de **sécurité dès la conception**, tout en intégrant des mesures spécifiques à l’IA. Lors de la création d’une application en interne, il est essentiel que les exigences de sécurité soient appliquées à tous les composants, qu’il s’agisse de composants logiciels traditionnels, comme l’infrastructure hôte, ou de composants spécifiques à l’IA, tels que la configuration des modèles et les données d’entraînement. Si des modèles open-source sont utilisés, il est également indispensable de tester la fiabilité du code afin d’identifier d’éventuelles faiblesses de sécurité, des défauts de conception ou des écarts par rapport aux normes de codage sécurisé.
Les équipes doivent également veiller à ce qu’aucune porte dérobée ne puisse être intégrée au modèle. Par exemple, un système pourrait être manipulé pour produire un résultat prédéterminé à l’aide d’un déclencheur spécifique. Ces scénarios doivent être anticipés et prévenus dès la phase de conception.
Certains contrôles de sécurité des applications resteront inchangées, mais devront être adaptées au contexte de l’IA. Par exemple, la surveillance des vulnérabilités publiques devra inclure non seulement les logiciels traditionnels, mais également les modèles d’IA, en particulier s’ils reposent sur des solutions open-source.
La formation des développeurs doit se poursuivre avec quelques ajustements. Les principes fondamentaux restent les mêmes : tout comme il est déconseillé de publier la version exacte d’un logiciel utilisé, les développeurs ne devraient pas divulguer les détails du modèle ou les paramètres d’entrée utilisés. Ils doivent également suivre les directives de sécurité existantes et mises à jour, comprendre les nouvelles menaces propres à l’IA, et intégrer ces connaissances dans leurs processus de développement. Ces efforts garantiront que les applications d’IA sont construites sur des bases solides et sécurisées.
Les applications d’IA présentent des risques inhérents qui nécessitent la mise en place de contrôles spécifiques tout au long de leur cycle de vie afin de garantir leur sécurité. Ces contrôles, souvent nouveaux, ne relèvent pas des responsabilités habituelles d’une équipe existante. Dans les organisations les plus matures, ils sont généralement gérés par un centre d’excellence en matière d’IA. Cependant, dans certaines structures, ils sont pris en charge par l’équipe de sécurité mais exécutés par des scientifiques des données.
Lors de la phase de construction du modèle, des contrôles spécifiques doivent être mis en place pour garantir une conception appropriée du modèle, la sécurité du code source, l’absence de biais dans les techniques d’apprentissage utilisées, ainsi que la mise en place de paramètres clairs concernant les entrées et sorties du modèle. Par exemple, des techniques comme le bagging peuvent être utilisées pour renforcer la résilience du modèle. Cette méthode consiste à diviser le modèle en plusieurs sous-modèles indépendants pendant la phase d’apprentissage, le modèle principal s’appuyant ensuite sur les prédictions les plus fréquentes des sous-modèles. Si l’un des sous-modèles est compromis, les autres peuvent compenser ses failles. D’autres techniques, comme la reconstruction des déclencheurs, peuvent également être appliquées pendant la phase de construction pour protéger contre les attaques par empoisonnement des données. La reconstruction des déclencheurs consiste à identifier des événements dans un flux de données, comme chercher une aiguille dans une botte de foin. Pour les modèles prédictifs, cette technique aide à détecter et à neutraliser les portes dérobées en analysant les résultats du modèle, son architecture et ses données d’entraînement. Les déclencheurs avancés détectent, analysent et atténuent les portes dérobées en identifiant les points sensibles potentiels dans un réseau neuronal profond. Cela inclut l’analyse des chemins de données pour repérer des prédictions inhabituelles (comme des résultats systématiquement erronés ou des temps de décision anormalement rapides), l’évaluation des activations suspectes en étudiant le comportement des données concernées, et la réaction à ces anomalies en filtrant les neurones problématiques ou en neutralisant efficacement la porte dérobée identifiée.
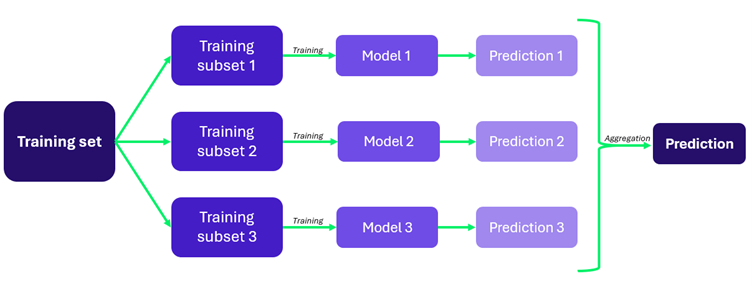
Fig 3. Bagging, une technique de construction pour améliorer la fiabilité et la précision d’un modèle.
En cours d’exécution, il est essentiel de s’assurer que les données introduites dans le modèle sont sûres et ne sont pas empoisonnées. Pour ce faire, on peut ajouter une couche supplémentaire d’IA qui a été formée à la détection des données malveillantes afin de filtrer et de superviser toutes les entrées de données et de détecter les attaques adverses.
Les équipes doivent comprendre comment le modèle s’intègre dans l’écosystème global de la sécurité de l’IA à chaque étape de son cycle de vie : construction, exécution et test. Cette compréhension inclut la connaissance de la disponibilité des informations sur le modèle, l’identification des nouvelles vulnérabilités et des menaces spécifiques à l’IA. Ces éléments permettent aux équipes d’appliquer les correctifs nécessaires et d’effectuer les tests appropriés pour maintenir la sécurité du modèle. Pour les modèles d’apprentissage continu, qui sont conçus pour s’adapter à de nouvelles données, des tests réguliers sont indispensables. Ces tests peuvent inclure une analyse de méta-vulnérabilité, une méthode permettant de modéliser le comportement du modèle à l’aide de spécifications formelles et de l’évaluer en fonction de scénarios de compromission identifiés précédemment. Des techniques d’apprentissage contradictoire, ou des approches similaires, doivent être mises en œuvre pour garantir la fiabilité et la résilience continues des modèles face à des menaces évolutives.
Conclusion
Nous avons démontré que malgré les nouvelles menaces que pose l’IA, les mesures de sécurité existantes continuent de fournir les bases d’un écosystème sécurisé. Dans l’ensemble de la fonction RSSI, nous constatons un équilibre entre les contrôles existants qui protégeront les applications d’IA de la même manière qu’ils protègent les logiciels traditionnels et les domaines qui doivent s’adapter ou ajouter à ce qu’ils font actuellement pour se protéger contre les nouvelles menaces.
Notre analyse nous permet de conclure que pour sécuriser pleinement votre écosystème au sens large, y compris les applications d’IA, vos contrôles seront constitués à 70 % de contrôles existants et à 30 % de nouveaux contrôles.

