
Microsoft a annoncé qu’en Q2 2024 « plus de la moitié des entreprises du classement Fortune 500 utilisent Azure OpenAI ». [1] En parallèle, AWS propose Bedrock [2], concurrent direct d’Azure OpenAI.
Ce type de plateforme permet de créer des applications basées sur les modèles d’IA générative comme des LLM (GTP-3.5, Mistral, etc.).
Néanmoins, l’adoption de cette technologie n’est pas sans risque : de l’assistant virtuel qui critique son entreprise [3] à la fuite de donnée [4], les exemples ne manquent pas.
Pour soutenir les nombreux déploiements en cours, il faut donc rapidement réfléchir à sa sécurité, notamment quand des données sensibles sont utilisées. Nous vous proposons de revenir, au travers de cet article, sur les risques et remédiations liés à l’utilisation de ces plateformes.
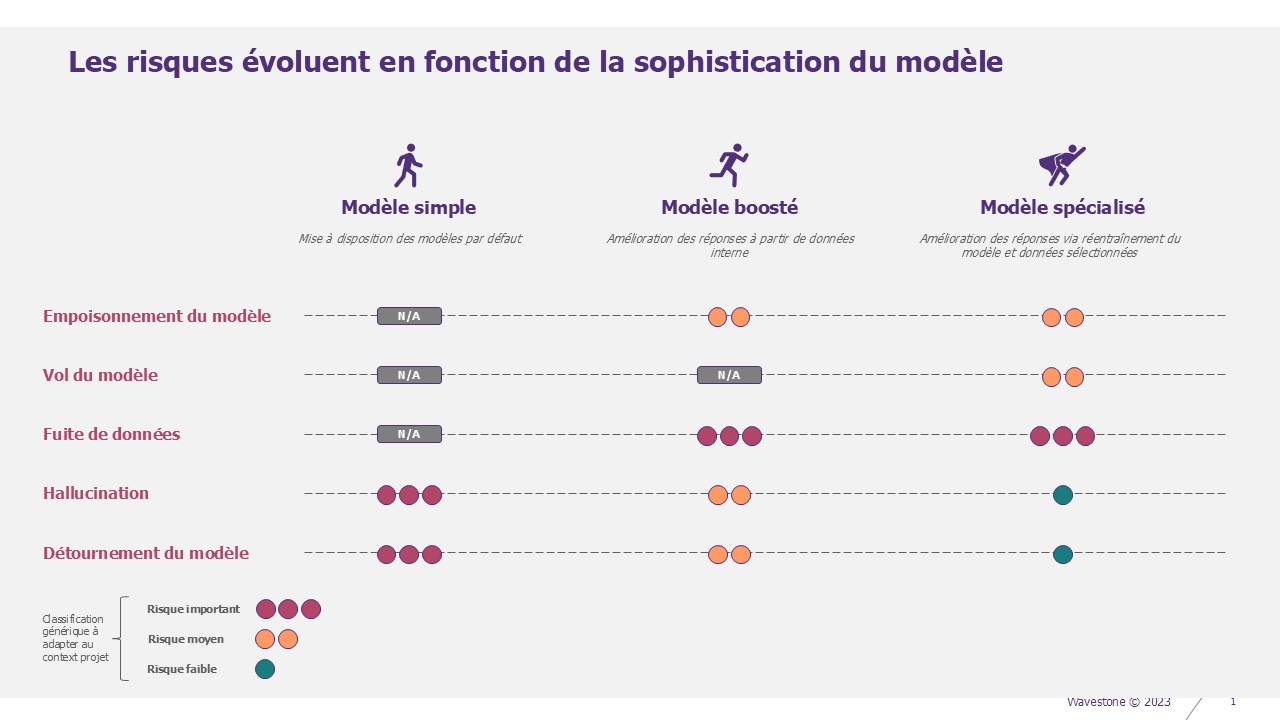
Quel modèle convient à votre besoin ?
Trois types d’IA génératives peuvent être utilisées pour créer une application. La différence s’observe dans la précision des réponses apportées :
- Simple : modèle d’IA générique (GPT-4, Mistral, etc.) branché comme tel, avec une interface utilisateur. C’est un GPT interne.
- Boosté : modèle d’IA générique qui fait levier sur les données de l’entreprise, par exemple via du RAG (Retrieval Augmented Generation). Ce sont les compagnons spécialisés pour un usage, RH GPT, Opération GPT, CISO GPT…).
- Spécialisé : le modèle d’IA réentraîné pour une utilisation particulière. Par exemple l’Inde a réentraîné Llama 3 sur ses 22 langues officielles pour en faire un traducteur spécialisé.
Ces trois modes de déploiement induisent des risques. Nous vous proposons dans un premier temps de décrire les différents modes. Nous verrons ensuite les risques, puis les remédiations associées.
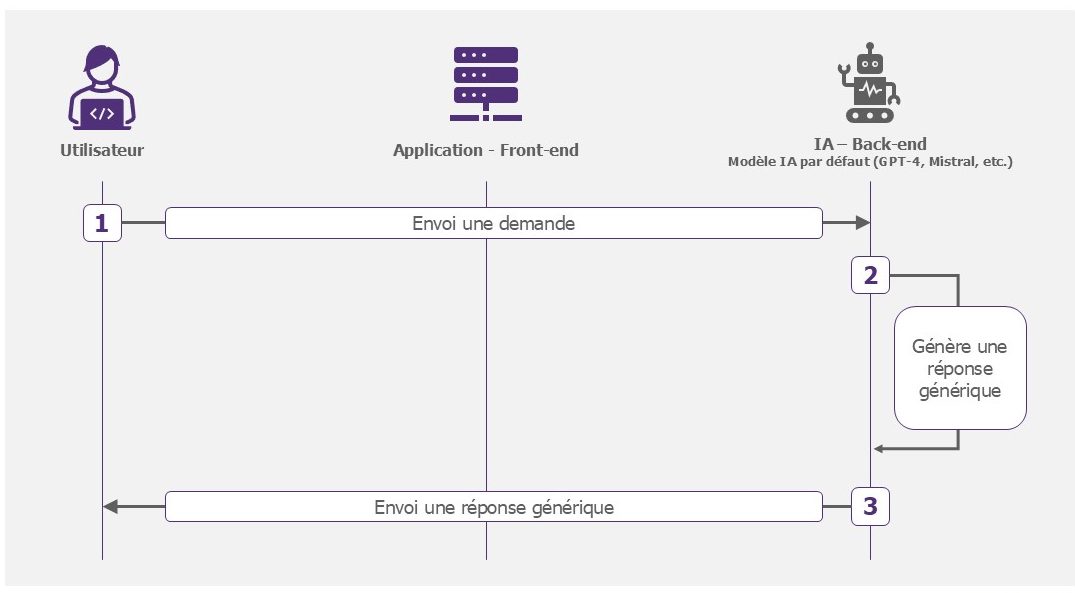
Modèle simple
Ce modèle est le plus simple à déployer. Il permet aux utilisateurs d’interagir avec les modèles d’IA proposés par les plateformes. Il simplifie l’intégration d’envoi de prompt et de réception des réponses dans une application. Il s’agit d’un ChatGPT interne, l’intérêt étant de limiter la fuite de donnée sensible insérée dans un prompt, à contrario de la version web. Aussi, dans ce cas, les échanges avec les utilisateurs ne sont pas utilisés pour réentraîner et améliorer le modèle. Vos données sont protégées. Les plateformes Cloud proposées par Azure, AWS ou GCP permettent un déploiement rapide de ces solutions.
Exemples d’utilisation : résumé de texte, assistant de développement.
Fonctionnement du modèle simple
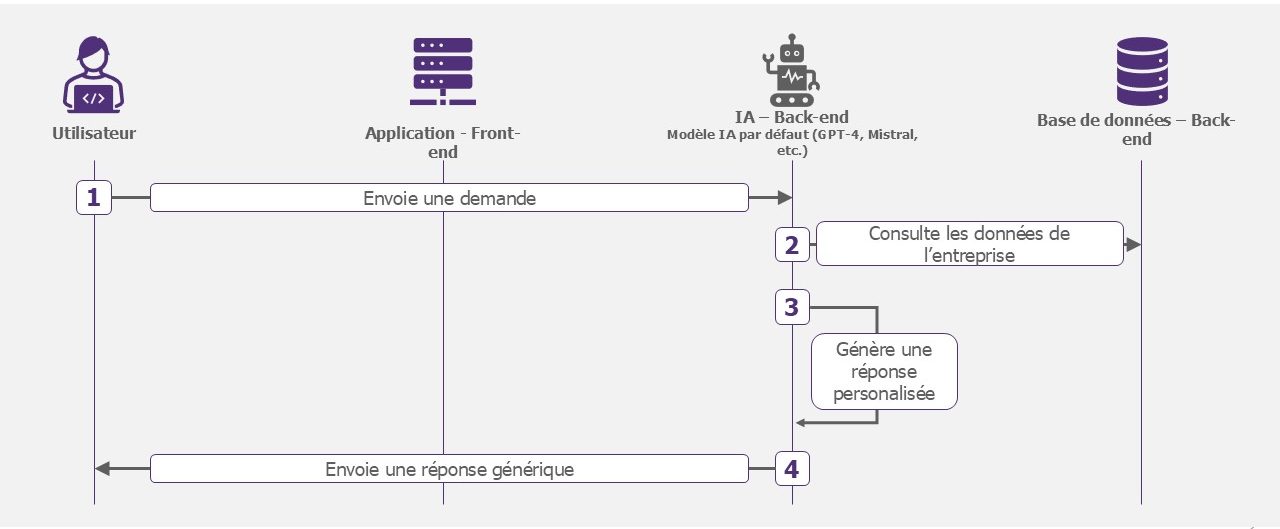
Modèle boosté
Le modèle reste générique mais aura accès à des données de l’entreprise sélectionnées. L’IA pourra par exemple consulter la PSSI du groupe pour fournir la politique de mots de passes.
Exemples d’utilisation : chatbot d’entreprise, analyse de données.
Fonctionnement du modèle boosté
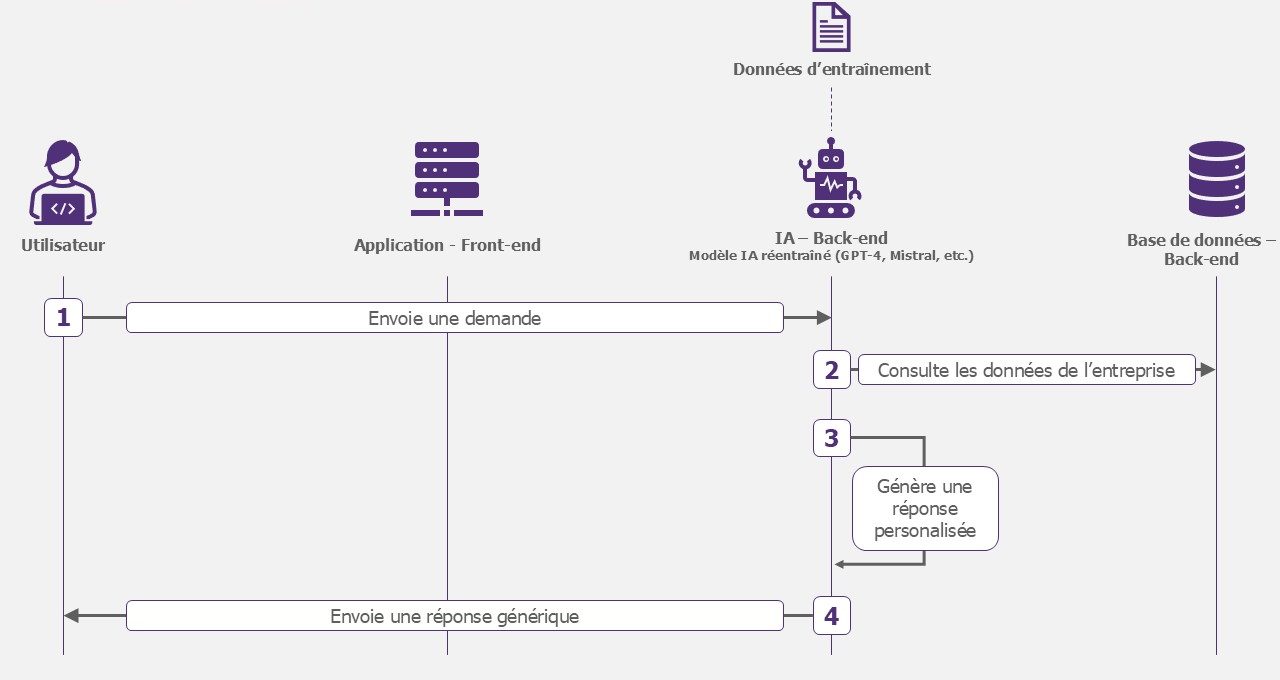
Modèle spécialisé
L’application ne repose plus sur un modèle générique (GPT-4, Mistral, etc.). En amont de son exploitation, vous devrez entraîner votre propre modèle sur les données de votre entreprise. Il pourra toujours consulter les données de l’entreprise et en aura une meilleure compréhension pour générer sa réponse.
Exemples d’utilisation : détection de défaut sur une ligne de production, diagnostic médical.
Fonctionnement du modèle spécialisé
A quels risques êtes-vous exposés ?
Qu’importe le modèle sélectionné, il existe plusieurs risques transverses ou spécifiques. Il est important d’en tenir compte pour assurer l’intégration sécurisée de la solution.
Détournement du modèle
Les modèles d’IA sont exposés au risque de mauvaise utilisation. Imaginez un scénario où quelqu’un utilise cette technologie pour générer du contenu nuisible. Cela peut entraîner des conséquences réelles comme la propagation de contenu toxique. L’une des attaques connues pour cet objectif est le Prompt Injection [5].
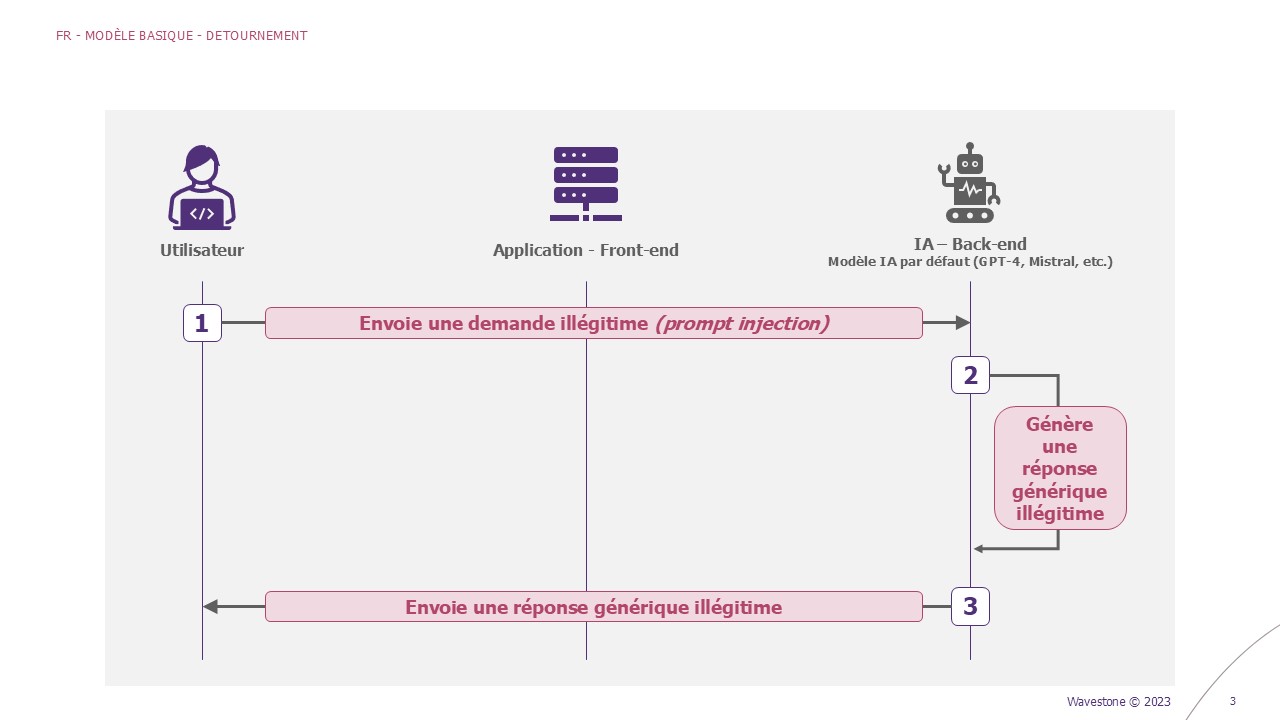
Exemple – Détournement du modèle (Prompt Injection)
Hallucination
Lorsque l’IA affirme une information qui est fausse, elle hallucine. Pensez-y comme si l’IA « rêvassait » : si elle n’a pas la réponse, elle va « inventer » des choses pour remplir le vide. Cela peut être particulièrement problématique dans des situations où la précision est cruciale : génération de rapports, prise de décisions. Les utilisateurs pourraient propager sans le savoir ces fausses informations, ou prendre de mauvaises décisions.
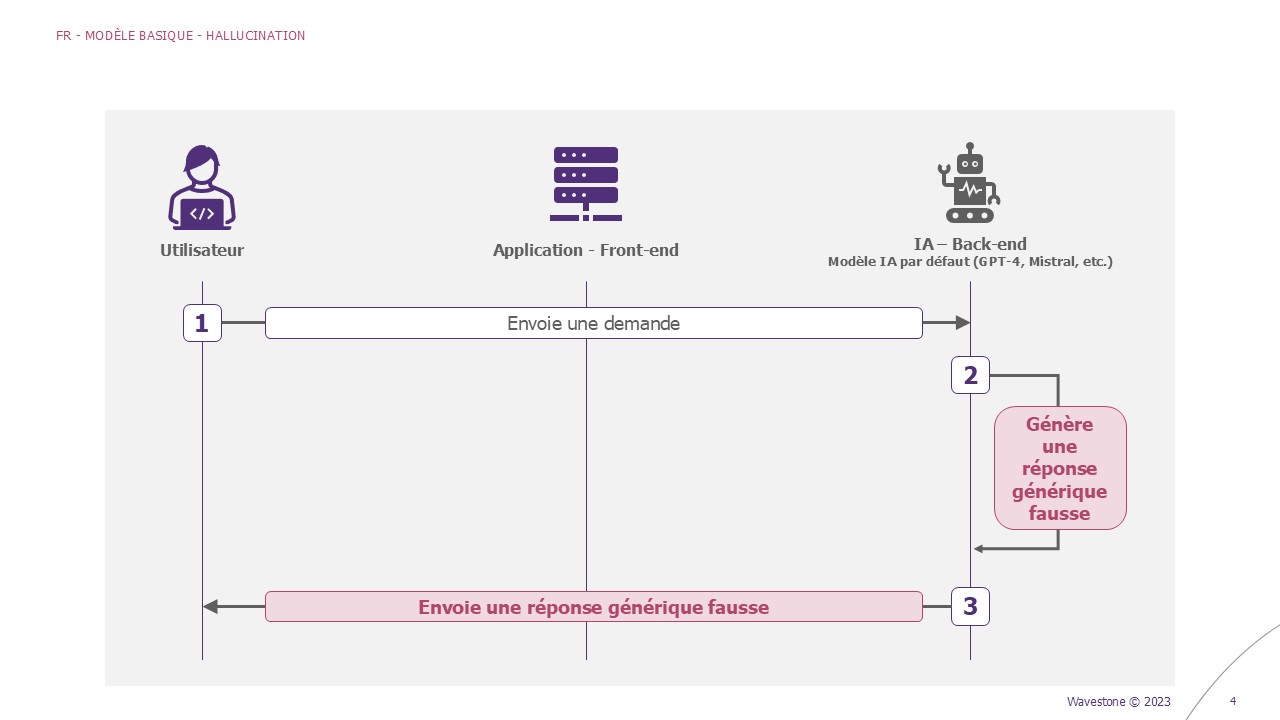
Exemple – Hallucination du modèle
Fuite de données
Il existe plusieurs façons de faire fuiter la donnée. Un attaquant peut injecter un prompt malicieux pour la récupérer, un employé peut se voir attribuer plus de droits que nécessaires et accéder à des informations sensibles (exemple : compte rendu stratégique d’un comité exécutif). La sécurisation de la base de données sous-jacente doit donc être proportionnelle à la donnée stockée.
A savoir que le modèle a accès à certaines données de l’entreprise. Si ses droits sont par exemple trop importants, il pourra consulter des données confidentielles. Ces réponses incluront donc des informations sensibles n’ayant pas vocation à être communiquées.
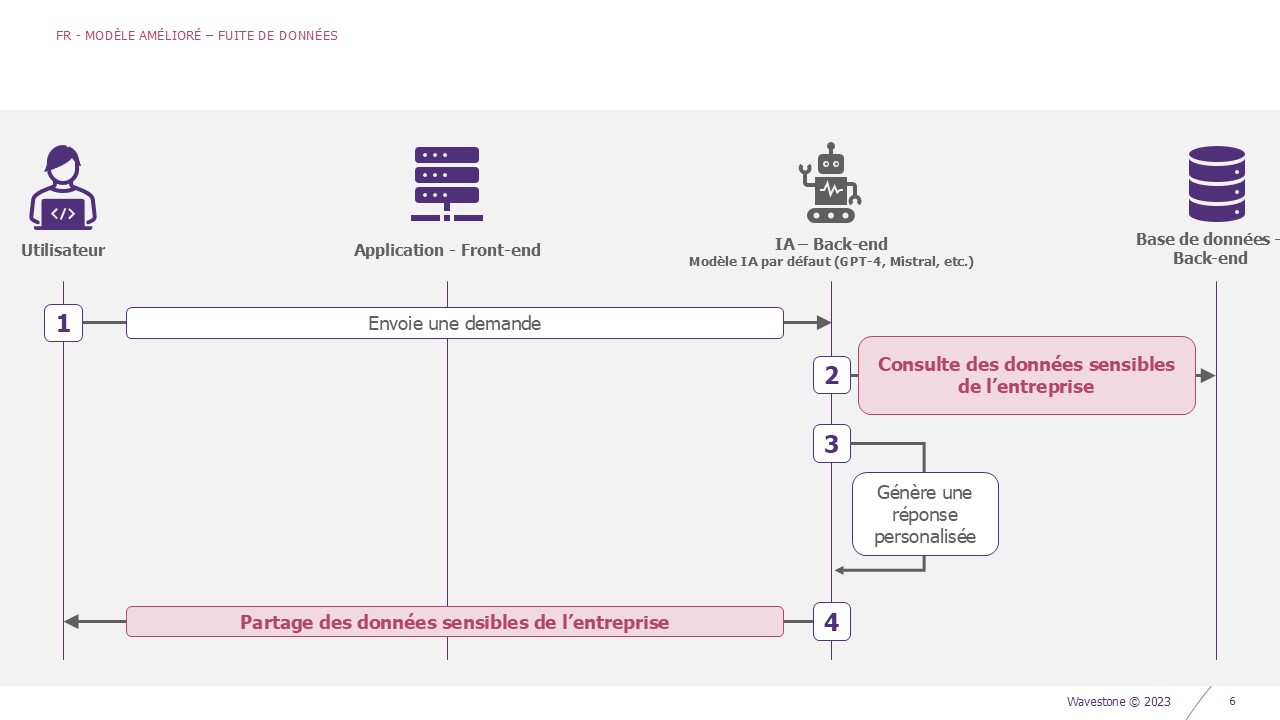
Exemple – Fuite de données
Vol du modèle
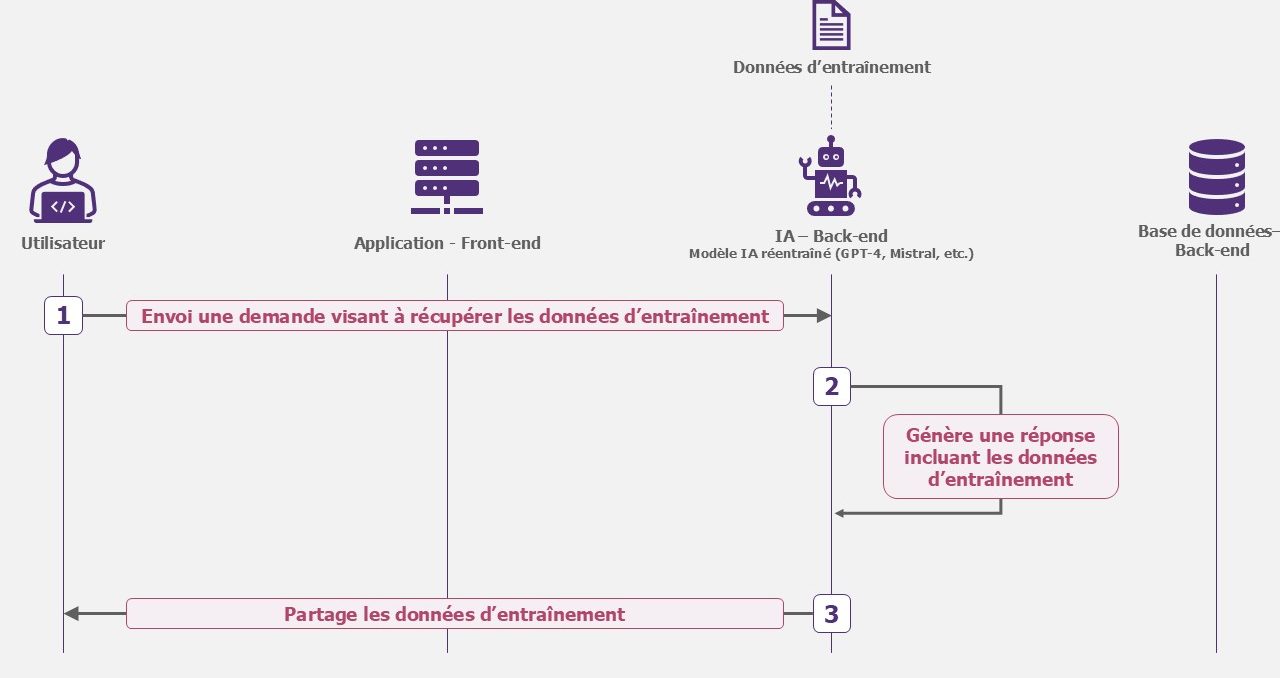
Si le modèle est spécialisé, c’est désormais la propriété intellectuelle de votre entreprise. À ce titre, il pourrait attiser la convoitise de l’attaquant. Les données d’entraînement confidentielles peuvent par exemple être ciblées. La question de confiance en l’hébergeur Cloud peut aussi se poser : ne vaut-il pas mieux l’héberger en local ?
Exemple – Vol du modèle
Empoisonnement du modèle
Sans prétendre voler le modèle, l’objectif de l’attaquant pourrait être de le rendre non fiable. Les réponses générées ne pourraient donc plus être exploitées par les équipes.
L’empoisonnement peut se produire dans deux cas de figures :
- Modèle boosté : l’attaquant accèdent au RAG et modifie les informations. Alors le modèle s’appuie sur des données empoisonnées pour fournir ses réponses.
- Modèle spécialisé : l’attaquant empoisonne les données de réentraînement du modèle. Soit directement sur la base de données qu’il met à disposition sur une plateforme publique (type Hugging face), soit en accédant à la base de données d’entraînement hébergé dans votre système d’information.
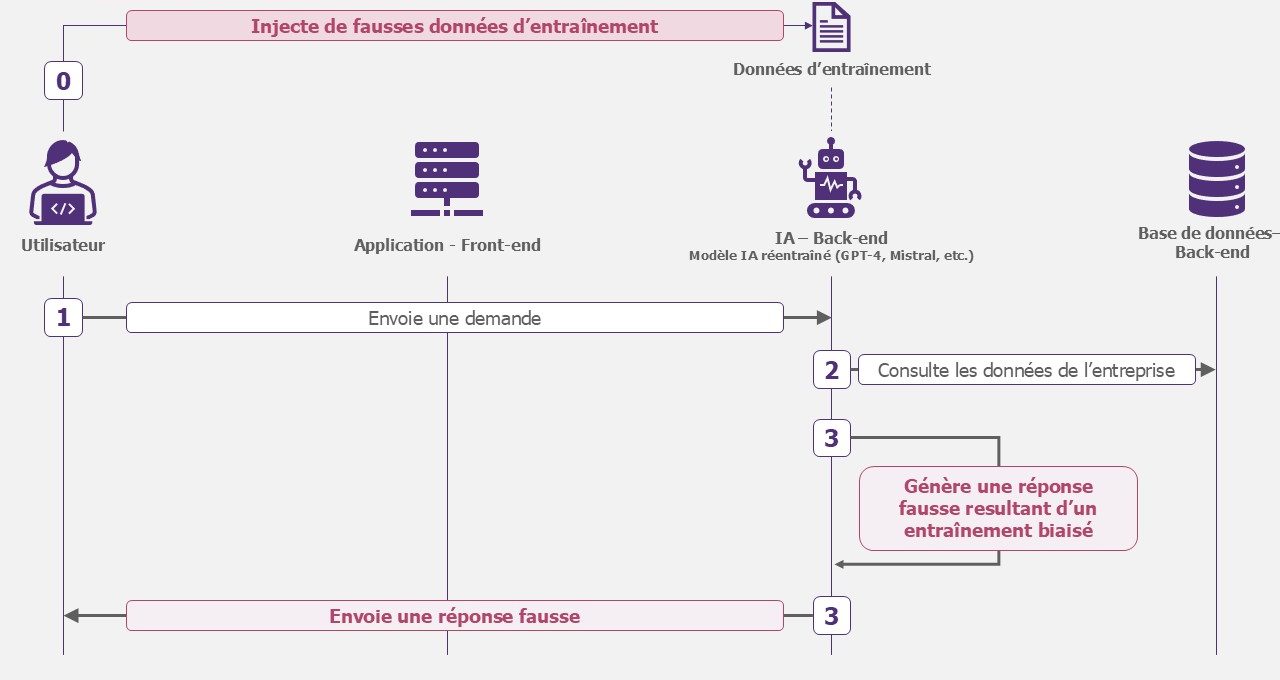
Exemple – Empoisonnement du modèle
Risques principaux : quelles remédiations ?
Parmi les 5 risques présentés, 3 prédominent dans les analyses de risques effectuées par nos équipes. Nous vous proposons d’étudier les remédiations associées.
Le caractère nouveau de la technologie offre l’opportunité de construire des bases de sécurité solide. Pour aboutir à une solution efficace et sécurisée, plusieurs itérations seront nécessaires.
Risque #1 : Détournement du modèle

Détournement du modèle : clé de remédiation
Pour faire face au détournement du modèle, nous conseillons les mesures suivantes :
#1 – Durcir la configuration suivant deux axes. Premièrement, la gestion du prompt maître (fenêtre de discussion avec le modèle). Certains mots clés peuvent par exemple être bannis afin d’éviter les dérives. Deuxièmement, le nombre de jetons et donc la taille des réponses. Un modèle moins verbeux aura moins de chance d’être détourné. D’autres paramètres peuvent être pris en compte : la température, la langue utilisée, etc.
#2 – Filtrer les réponses en appliquant par exemple un simple algorithme filtrant les réponses. Pour aller plus loin, il est envisageable de déployer des pares-feux LLM spécialisés. Cela permettra par exemple de se prévenir de potentiels abus (on parle dans ce cas-là d’Abuse monitoring).
#3 – Limiter les sources auxquels le modèle à accès pour générer ses réponses. Dans l’hypothèse où l’accès aux données de l’entreprise est accordé au modèle, il est possible de le limiter uniquement à ces données. Ainsi, il ne pourra pas chercher d’autres informations sur Internet par exemple.
Risque #2 : Hallucination
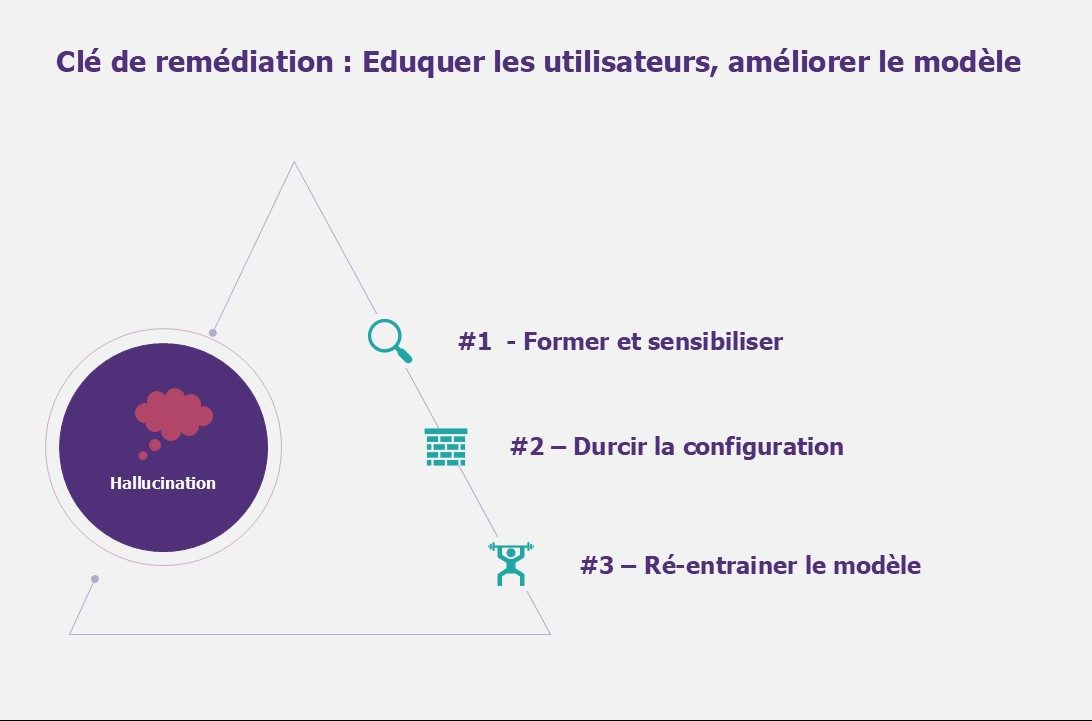
Hallucination : clé de remédiation
Pour faire face aux hallucinations, nous conseillons les mesures suivantes :
#1 – Former et sensibiliser les utilisateurs sur le fonctionnement des modèles, leurs limites et les meilleures pratiques. Cela permet aux utilisateurs d’utiliser les Large Language Model de manière responsable et de reconnaître les utilisations abusives ou les menaces de sécurité potentielles.
#2 – Durcir la configuration suivant deux axes. Premièrement, un ajustement du paramétrage incluant le réglage de la température du modèle (degré de créativité du modèle) et la limitation des jetons (nombre de mots par questions/réponses). Deuxièmement, l’utilisation d’un modèle plus récent (GPT-4 plutôt que GPT 3.5 par exemple).
#3 – Optionnel – Ré-entrainer le modèle lui donne un contexte. La fiabilité des réponses sera donc positivement impactée. Utiliser un large éventail de données d’entraînement peut aider à couvrir plus de scénarios et réduire les biais, ce qui aide l’IA à mieux comprendre et générer des réponses appropriées. Il est de même important d’éliminer les erreurs et les incohérences dans les données d’entraînement peut réduire la probabilité que l’IA apprenne et répète ces mêmes erreurs.
Risque #3 : Fuite de données
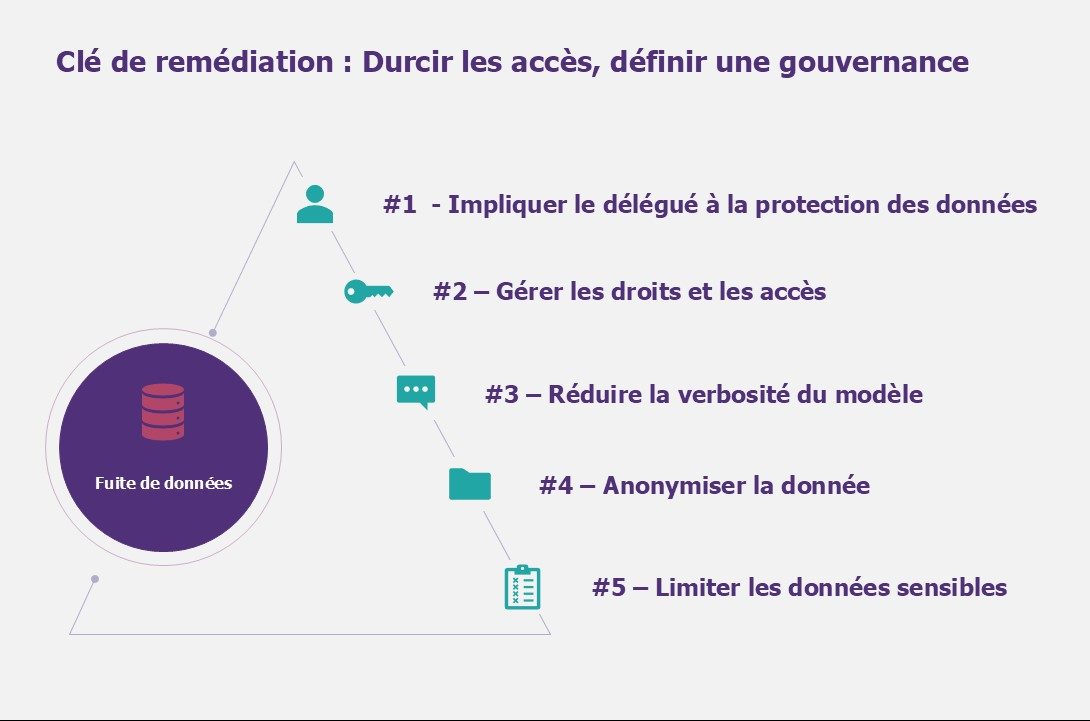
Fuite de données : clé de remédiation
Pour faire face aux fuites de données sensibles, nous conseillons les mesures suivantes :
#1 – Impliquer le délégué à la protection des données afin d’assurer la conformité aux lois et protocoles de protection des données en impliquant le Délégué à la Protection des Données (DPO) dans les projets accédant aux plateformes de Large Language Model est important pour protéger les données personnelles et sensibles. En adhérant à ces normes, les organisations protègent non seulement la vie privée individuelle mais renforcent également leur défense contre les violations de données et la mauvaise utilisation.
#2 – Gérer les droits et les accès sur l’ensemble des composantes interagissant avec le modèle. Comprendre quelles données quelles données peuvent être accéder par le modèle n’est pas trivial. Auditer et recertifier ces données dans le temps permet de limiter les écarts potentiels.
#3 – Réduire la verbosité du modèle via la limitation du nombre de jetons de sortie. Moins un modèle est verbeux, plus la probabilité qu’il partage de la donnée confidentielle par inadvertance est faible.
#4 – Anonymiser la donnée, ou la rendre générique, si le cas d’usage le permet. L’IA pourra par exemple travailler sur les tendances d’une population sans qu’un nom explicite ne puisse être cité. En plus de réduire fortement le risque de fuite de donnée, cela réduira les normes auxquelles se conformer (exemple : RGPD).
#5 – Limiter les données sensibles utilisées, il faut ici réfléchir aux données nécessaires et suffisantes pour que le modèle fonctionne. Un traitement préalable de la donnée peut être effectuée pour supprimer ou modifier les données sensibles et ainsi en réduire l’exposition (exemple : anonymisation de la donnée).
Remédiations transverses
Certaines mesures s’appliquent à tous les risques cités ci-dessus. Deux d’entre elles apparaissent comme fondamentales.
#1 – Intégrer la sécurité aux projets via, par exemple, une analyse de sécurité contextualisée. Cela permet aux organisations peuvent identifier et atténuer préventivement les vulnérabilités potentielles, assurant ainsi que seuls les projets sécurisés et vérifiés accèdent aux applications d’IA génératives.
#2 – Documenter chaque application afin d’établir un cadre opérationnel facilitant non seulement une supervision et une gestion plus aisées, mais réduit également le risque d’utilisation non autorisée ou malveillante.
Le développement d’applications d’IA est accéléré par les plateformes disponibles. Cependant, la sophistication qu’il apporte n’est pas sans risque.
Reconnaissant ces défis, la priorité est l’établissement d’une gouvernance robuste pour la plateforme. Cela implique une délimitation des rôles et responsabilités, assurant une approche structurée pour gérer et atténuer les risques.
La gouvernance s’étend au-delà de la plateforme elle-même. Sécuriser la myriade de cas d’utilisation d’application d’IA est tout aussi important. Il s’agit de garantir que l’application de cette technologie d’IA est à la fois responsable et alignée sur les normes éthiques, se prémunissant contre la mauvaise utilisation et les conséquences non intentionnelles.
Cela appelle à un modèle de responsabilité partagée, où tous les acteurs — développeurs, utilisateurs et organes de gouvernance — collaborent pour maintenir l’intégrité et la sécurité des applications d’IA.
Références
- https://synthedia.substack.com/p/microsoft-azure-ai-users-base-rose
- https://www.usine-digitale.fr/article/amazon-fait-son-entree-sur-le-marche-de-l-ia-generative-avec-bedrock.N2121081
- https://www.theguardian.com/technology/2024/jan/20/dpd-ai-chatbot-swears-calls-itself-useless-and-criticises-firm
- https://openai.com/blog/march-20-chatgpt-outage
- https://www.riskinsight-wavestone.com/2023/10/quand-les-mots-deviennent-des-armes-prompt-injection-et-intelligence-artificielle/

