
L’intelligence artificielle (IA) occupe désormais une place centrale dans les produits et services offerts par les entreprises et les services publics, en grande partie grâce à l’essor de l’IA générative. Pour soutenir cette croissance et favoriser l’adoption de l’IA, il a été nécessaire d’industrialiser la conception des systèmes d’IA en adaptant les méthodes et procédures de développement de modèles.
C’est ainsi qu’est né le MLOps, une contraction de “Machine Learning” (le cœur des systèmes d’IA) et “Operations”. À l’instar du DevOps, le MLOps facilite la réussite des projets de Machine Learning tout en assurant la production de modèles performants.
Cependant, il est crucial de garantir la sécurité des algorithmes pour qu’ils demeurent performants et fiables dans le temps. Pour ce faire, il est nécessaire de faire évoluer le MLOps vers le MLSecOps, en intégrant la sécurité dans les processus, à l’image du DevSecOps. Peu d’entités ont adopté et déployé un processus MLSecOps complet. Dans cet article, nous explorerons en détail la forme que pourrait prendre le MLSecOps.
Le MLOps, les fondamentaux de développement de modèle d’IA
Rapprochement avec le DevOps
Le DevOps est une approche qui combine le développement logiciel (Dev) et les opérations informatiques (Ops). Son objectif est de raccourcir le cycle de vie du développement tout en assurant des livraisons continues de haute qualité. Les principes clés incluent l’automatisation des processus (développement, test et mise en production), la livraison continue (CI/CD) et des boucles de rétroaction rapides.
MLOps, quant à lui, est une extension des principes DevOps appliqués spécifiquement aux projets de Machine Learning (ML). Les flux de travail sont simplifiés et automatisés au maximum, de la préparation des données d’entraînement à la gestion des modèles en production. Le MLOps se distingue du DevOps sur plusieurs points :
- Importance des données et des modèles : Dans le Machine Learning, les données et les modèles sont cruciaux. Le MLOps va plus loin en automatisant toutes les étapes du Machine Learning, de la préparation des données aux phases d’entraînement. De plus, un volume de données plus important est souvent utilisé dans les projets de Machine Learning.
- Nature expérimentale du développement : Le développement en Machine Learning est expérimental et implique de tester et d’ajuster continuellement les modèles pour trouver les meilleurs algorithmes, paramètres et données pertinentes pour l’apprentissage. Cela pose des défis pour l’adaptation du DevOps au Machine Learning, car le DevOps se concentre sur l’automatisation et la stabilité des processus.
- Complexité des tests et de la recette : La nature évolutive des modèles et la complexité des données rendent les phases de test et de recette plus délicates en Machine Learning. De plus, la surveillance des performances est essentielle pour garantir le bon fonctionnement des modèles en production. Ainsi, en Machine Learning, il faut adapter les procédures de Maintenance en Conditions Opérationnelles pour maintenir la stabilité et la fiabilité des systèmes.
En somme, une chaîne MLOps partage des éléments communs avec une chaîne DevOps, mais introduit des étapes supplémentaires et accorde une importance particulière à la gestion et à l’utilisation des données. Le graphique suivant souligne en jaune toutes les étapes supplémentaires que le MLOps introduit :
- Accès et utilisation des données : Cette étape inclut toutes les phases du Data Engineering (collecte, transformation et versionnement des données utilisées pour l’entraînement). L’enjeu est d’assurer l’intégrité des données et la reproductibilité des tests.
- Recette du modèle : Les recettes et les tests d’intégration en ML sont plus complexes et se déroulent sur trois couches différentes : la pipeline des données, la pipeline du modèle de ML et la pipeline applicative.
- Monitoring en production : Il s’agit de garantir la performance du modèle dans le temps et d’éviter le “model drifting” (déclin de la performance dans le temps). Pour cela, toutes les déviations (changement instantané, changement graduel, changement récurrent) doivent être détectées, analysées et corrigées si nécessaire.
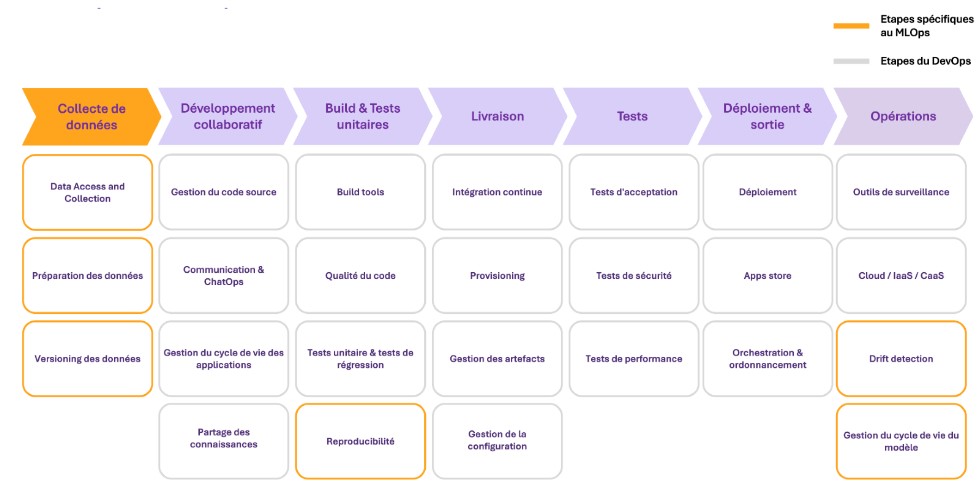
Figure 1 – Adaptation des étapes du DevOps au Machine Learning
Mettre en place le MLOps nécessite de créer un dialogue entre ingénieur des données et les opérateurs de DevOps
Le passage au MLOps implique de créer de nouvelles étapes organisationnelles spécifiquement adaptée à la gestion des données. Cela inclut notamment la collecte et la transformation des données d’entrainement, ainsi que les processus de suivi des différentes versions de données.
En ce sens, la collaboration entre les experts en MLOps, Data Scientists et les Data Engineers est essentielle pour réussir dans ce domaine en constante évolution. L’enjeu principal d’une mise en place d’une chaine MLOps réside donc dans l’intégration des Data Engineers dans les processus DevOps. Ces derniers sont responsables de préparer les données dont les ingénieurs MLOps ont besoin pour entraîner et exécuter des modèles.
Et la sécurité dans tout ça ?
L’adoption massive des IA génératives en 2024 nous a fourni une variété d’exemples de compromissions de terme de sécurité. En effet, la surface d’attaque est grande : un acteur malveillant peut à la fois attaquer le modèle en lui-même (vol de modèle, reconstruction de modèle, détournement de l’usage initial) mais également attaquer ses données (extraire des données d’entraînement, modifier le comportement en ajoutant des fausses données, etc.). Pour illustrer ces derniers, nous avons simulé deux attaques réalistes dans de précédents articles : Attaquer une IA ? Un exemple concret ! ou Quand les mots deviennent des armes : prompt injection.
En parallèle, le MLOps, introduit une automatisation qui accélère la mise en production. Bien que cela puisse réduire le time to market (délais de mise sur le marché), cela augmente également les risques (attaque par supply chain, massification). Il est donc crucial de s’assurer que les risques liés à la cybersécurité et à l’IA sont correctement gérés.
Comme le fait le DevSecOps pour le DevOps, la chaine de production du MLOps doit être sécurisée. Voici un panorama des principaux risques sur la chaine MLOps :
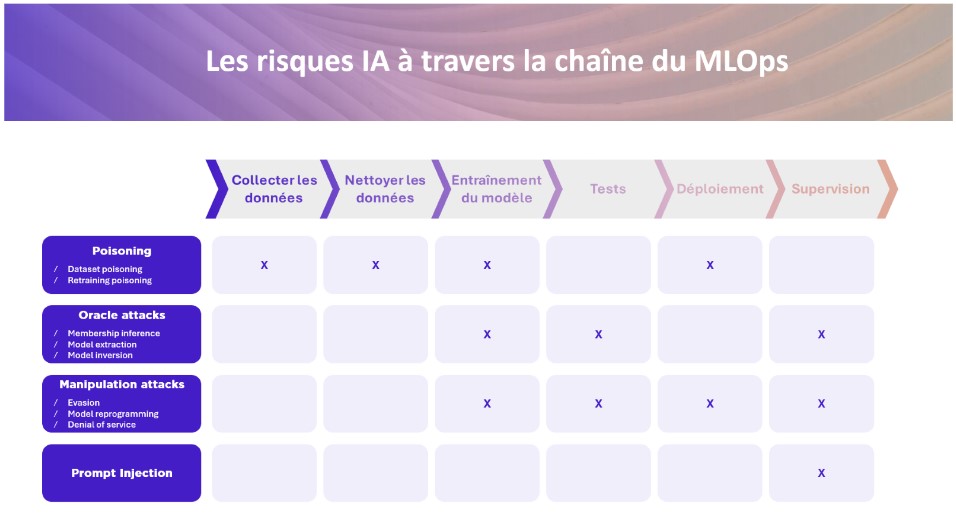
Adopter le MLSECOPS
Intégrer la sécurité dans les équipes MLOPS et renforcer la culture sécurité
Les principes du MLSecOps doivent être compris par les Data Scientists et les Data Engineers. Pour cela, il est crucial que les équipes de sécurité soient intégrées dès le début du projet. Cela peut se faire de deux manières :
- Lors de la création d’un nouveau projet, un membre de l’équipe de sécurité est assigné en tant que responsable de la sécurité. Il supervise les avancées et répond aux questions des équipes du projet.
- Une approche plus agile, similaire au DevSecOps, consiste à désigner un membre de l’équipe comme “Security Champion”. Ce référent cybersécurité au sein de l’équipe projet devient l’interlocuteur privilégié des équipes cyber. Cette méthode permet une intégration plus réaliste de la sécurité dans le projet, mais nécessite une formation adéquate pour le Security Champion.
Pour que ce changement soit efficace, il est également nécessaire de modifier la perception de la cybersécurité par les équipes projets :
- En fournissant une formation de base aux équipes pour mieux comprendre les enjeux de la cybersécurité.
- En intégrant la cybersécurité dans les plateformes de collaboration et de connaissances.
- En organisant régulièrement des campagnes de sensibilisation.
Sécuriser les outils de la chaîne MLOPS
Pour garantir la sécurité des produits, il est essentiel de sécuriser la chaîne de production. Dans le cadre du MLOps, cela signifie s’assurer que tous les outils sont correctement utilisés avec des pratiques intégrant la cybersécurité, qu’il s’agisse du traitement et de la gestion des données (comme MongoDB, SQL, etc.), des outils de surveillance (tel que Prometheus), ou des outils de développement plus ou moins spécifiques (comme MLFlow ou GitHub).
Par exemple, il est crucial que les équipes restent vigilantes sur des thématiques telles que l’identification et la gestion des identités, la continuité d’activité, la surveillance, et la gestion des données. Les possibilités offertes par les différents outils utilisés tout au long du cycle de vie, ainsi que leurs spécificités, doivent être examinées en lien avec ces enjeux. Idéalement, les caractéristiques de cybersécurité devraient servir de critères de sélection pour choisir l’outil le plus adapté.
Définir des pratiques en matière de sécurité de l’IA
Au-delà de la sécurité des outils qui permettent de construire les systèmes d’IA, il convient d’intégrer des mesures de sécurité permettant de prévenir les vulnérabilités spécifiques aux systèmes d’IA. Ces mesures doivent être incorporées dès la conception et tout au long du cycle de vie de l’application, suivant une approche MLSecOps. De la collecte des données à la surveillance du système, il existe de nombreuses mesures de sécurité à intégrer :
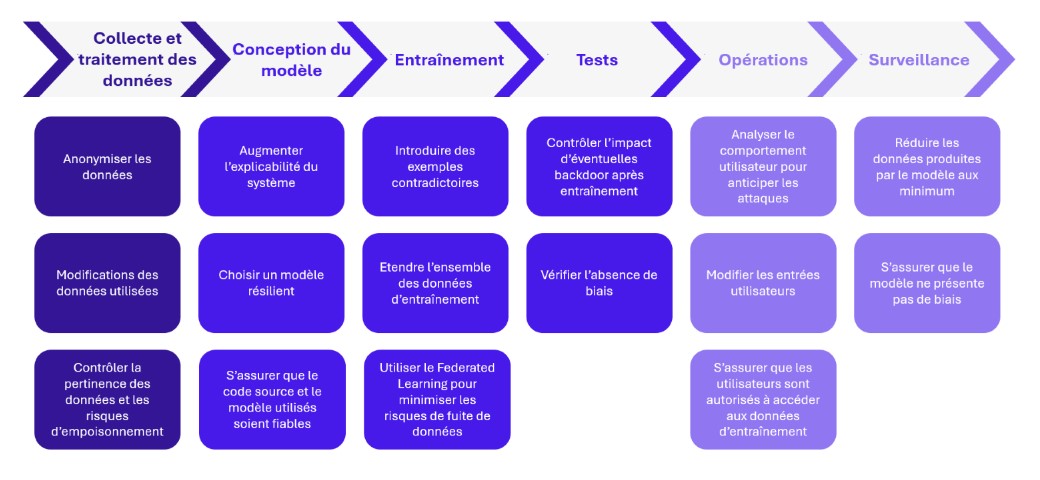
Figure 2 – Les mesures de sécurité applicables tout au long du cycle de vie
Trois mesures de sécurité à implémenter dans vos processus MLSecOps
Selon la stratégie de sécurité adoptée, diverses mesures de sécurité peuvent être intégrées tout au long du cycle de vie du MLOps. Nous avons détaillé les principaux mécanismes de défenses pour sécuriser l’IA dans l’article suivant : Sécuriser l’IA : Les Nouveaux Enjeux de Cybersécurité.
Dans cette partie, nous allons nous attarder sur 3 mesures spécifiques qui peuvent être mises en œuvre pour renforcer la sécurité du MLOps :
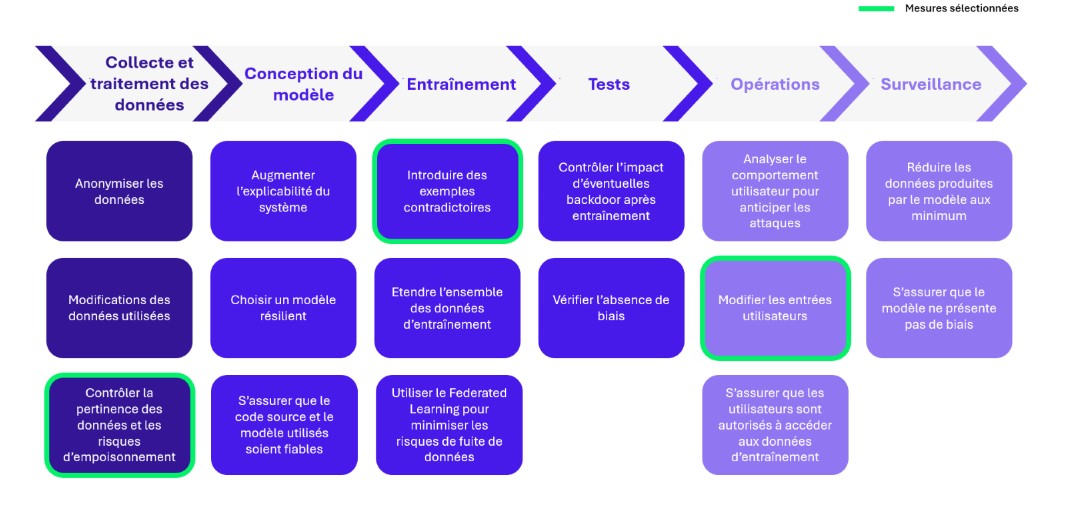
Figure 3 – Mesures de sécurité sélectionnées
Contrôler la pertinence des données et les risques d’empoisonnement
Dans le cadre du Machine Learning, la sécurité des données est primordiale pour prévenir les risques d’empoisonnement et garantir l’intégrité des données traitées.
Avant de procéder au traitement des données collectées, un contrôle continu de l’origine des données est essentiel afin d’en garantir leur qualité et leur pertinence. Cela est d’autant plus complexe lors de l’utilisation de flux de données externes, dont la provenance et la véracité peut parfois être incertain. Ainsi, le risque majeur réside dans l’intégration de données utilisateurs lors d’un apprentissage en continu. Cela peut conduire à des résultats imprévisibles, comme illustré par l’exemple du ChatBot TAY de Microsoft en 2016. Ce dernier, était conçu pour apprendre à travers les interactions utilisateurs. Cependant, sans une modération adéquate, il a rapidement adopté des comportements inappropriés, reflétant les entrées négatives reçues. Cet incident souligne l’importance d’une surveillance et d’une modération constantes des données d’entrée, en particulier lorsqu’elles proviennent d’interactions humaines en temps réel.
Diverses techniques d’analyse peuvent être utilisées pour nettoyer un ensemble de données. L’objectif étant de vérifier l’intégrité des données et de supprimer toute données pouvant avoir un impact négatif sur les performances du modèle. Deux méthodes principales sont possibles :
- D’une part, nous pouvons vérifier individuellement l’intégrité de chacune des données par contrôle des valeurs aberrantes, validation du format ou de métriques caractéristiques…
- D’autre part, avec une analyse globale, des approches comme la validation croisée et le clustering statistique sont efficaces pour identifier et éliminer les éléments inappropriés de l’ensemble de données.
Introduire des exemples contradictoires
Les exemples contradictoires sont des entrées corrompues, modifiées pour induire en erreur les prédictions d’un algorithme de Machine Learning. Ces modifications sont construites pour être indétectables à l’œil humain mais suffisantes pour tromper l’algorithme. Ce type d’attaque exploite les vulnérabilités ou failles présentes dans l’entrainement du modèle pour provoquer des erreurs de prédiction. Pour les réduire, il est alors possible d’apprendre au modèle à identifier et ignorer ce type d’entrée.
Pour cela, nous pouvons délibérément ajouter des exemples contradictoires aux données d’entraînements. L’objectif est de présenter au modèle des données légèrement altérées, afin de le préparer à identifier et gérer correctement les erreurs potentielles. La création de ce type de données dégradée est complexe. La génération de ces exemples contradictoires, devra être adapté au problème et aux menaces identifiées. Il est crucial de surveiller attentivement la phase d’entraînement afin de s’assurer que le modèle reconnaît efficacement ces entrées incorrectes et sache réagir correctement.
Modifier les entrées utilisateurs
La sécurisation des entrées est essentielle pour minimiser les risques liés aux manipulations malveillantes. Une faiblesse importante des LLM (Large Language Models) est leur manque de compréhension contextuelle approfondie et leur sensibilité à la formulation précise des prompts. Une des techniques les plus connue pour exploiter cette vulnérabilité est l’attaque par prompt injection. Il est donc nécessaire d’introduire une étape intermédiaire de transformation des données utilisateur avant leur traitement par le modèle.
Il est possible de modifier légèrement l’entrée afin de contrer ce type d’attaque, tout en préservant la précision du modèle. Cette transformation peut se faire via diverses techniques (e.g. codage, ajout de bruit, reformulation, compression des caractéristiques, etc.). L’objectif est de conserver uniquement ce qui est essentiel à la réponse. Ainsi, toute information superflue potentiellement malicieuse est écartée. De plus, cette méthode prive l’attaquant de la possibilité d’accéder à la véritable entrée du système. Ce qui empêche toute analyse approfondie des relations entre entrées et sorties et complique ainsi la conception de futures attaques. Il reste toutefois essentiel de tester les différentes mesures implémentées, pour s’assurer qu’elles ne dégradent pas les performances du modèle, garantissant ainsi une sécurité renforcée sans compromettre l’efficacité.
Avec l’industrialisation de la production d’applications basées sur le Machine Learning et l’IA, la sécurité à grande échelle devient une question organisationnelle cruciale pour le marché. Il est impératif d’entreprendre une transition vers le MLSecOps. Cette transformation repose sur trois piliers principaux :
- Renforcer la culture de sécurité des équipes de Data Scientists : Il est essentiel que les Data Scientists comprennent et intègrent les principes de sécurité dans leur travail quotidien. Cela permet de créer une culture de sécurité partagée et de renforcer la collaboration entre les différents acteurs.
- Sécuriser les outils qui produisent les algorithmes de Machine Learning : Il est essentiel de sélectionner des outils de MLOps sécurisés et d’appliquer des bonnes pratiques au sein de outils (gestion des droits, etc.) pour sécuriser « l’usine » à algorithmes de Machine Learning et ainsi réduire la surface de compromission.
- Intégrer des mesures de sécurité spécifiques à l’IA : Adapter les mesures de sécurité aux particularités des systèmes d’IA est crucial pour prévenir les attaques potentielles et assurer la fiabilité des modèles dans le temps. Il convient donc d’intégrer ces mesures de sécurité dans la chaîne de MLOps à l’aide du MLSecOps.
Engagez-vous dès aujourd’hui dans la transition vers le MLSecOps. Formez vos équipes, sécurisez vos outils et intégrez des mesures de sécurité spécifiques à l’IA. A ce titre, vous pourrez bénéficier de systèmes d’IA produits industriellement et sécurisés by design.
Remerciements à Louis FAY et Hortense SOULIER qui ont également contribué à la rédaction de cet article.

