
Fin juin 2017, une image avait marqué les esprits du monde de la cyber sécurité et de la continuité d’activité. Un open-space, rempli de postes de travail, tous affichant le même écran : le message de demande de rançon de NotPetya. Encore aujourd’hui, 90% des crises gérées par le CERT Wavestone sont causées par des rançongiciels [1]. Comment faire alors pour commencer les investigations, la reconstruction ou permettre au métier de continuer de travailler si aucun poste de travail ne fonctionne ? Quelle stratégie développer pour intégrer la composante poste de travail aux plans de continuité, qui l’adressaient majoritairement jusqu’alors sous l’angle du sinistre bâtimentaire ?
Définir les besoins
Pour commencer, il est important de définir le scénario cyber duquel on veut se protéger. Est-ce un scénario « Total blackout » où l’ensemble du SI est indisponible ? Ou un scénario ransomware Windows basique où une partie des serveurs Windows ainsi que les postes sont compromis, mais les équipements réseaux et les briques Linux fonctionnent toujours ?
Ensuite et sur base des scénarios retenus, il est nécessaire de segmenter les populations en fonction de leur besoin : il n’est pas possible de fournir un nombre infini de postes en une période donnée, et il faut savoir à qui attribuer les premiers postes qui seront mis à disposition. Par exemple, on peut distinguer les équipes métier vitales de l’entreprise, dont l’activité ne peut être interrompue plus de 4 heures, et les activités métier moins critiques, pour lesquels l’activité peut être interrompu pendant 3 jours avec des impacts acceptables pour l’entreprise en mode de crise. De la même manière, les équipes IT et Cyber à mobiliser dans les toutes premières heures de la crise pour conduire les investigations et lancer la reconstruction doivent être identifiés.
Autre point à prendre en compte, les fonctionnalités métier minimales pour que le poste reconstruit soit utile. Certaines populations métier utilisent des clients lourds sur leurs postes, dont l’installation et la maintenance se révèle complexe. De même, certains métiers ont besoin d’interagir avec des tiers pour leurs activités vitales, via des VPN dédiés ou un whitelist IP. Cadrer précisément combien de personnes ont ces besoins et à quelle échéance est donc essentiel pour définir les solutions techniques envisageables.
On ne proposera aussi pas forcément la même solution aux équipes IT d’investigation et de reconstruction – qui ont besoin d’avoir accès au réseau interne – qu’aux équipes métier qui peuvent pour les quelques premiers jours de crise avoir des modes dégradés hors du système d’information (SI) de l’entreprise.
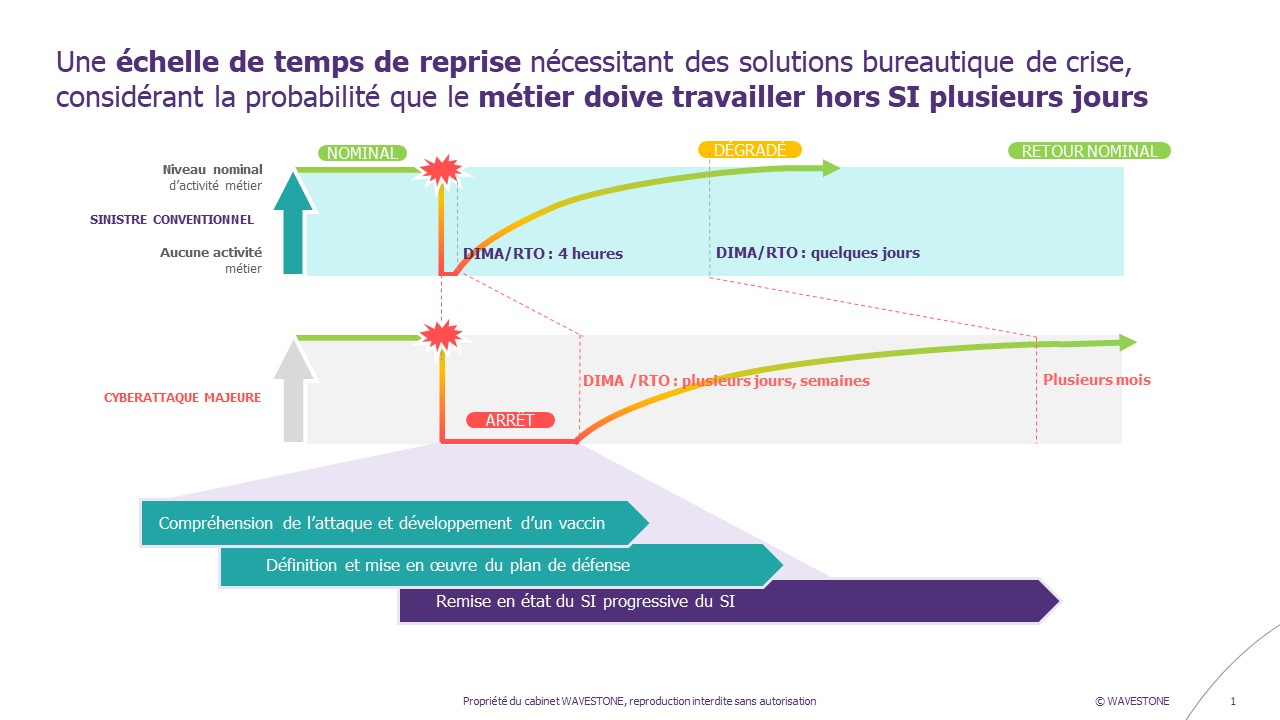
Au final, on aura tendance à distinguer deux phases bien différenciées dans la stratégie de fourniture de poste de travail en cas de crise ransomware :
- Une première phase lors des tous premiers jours de crise pour une population limitée, qui s’appuiera en général sur des solutions ayant le moins d’adhérence possible avec le Système d’Information nominal, afin d’assurer les activités métier critiques ;
- Une seconde phase lorsque les investigations auront avancé, avec une reconstruction de poste massive en utilisant le master de l’entreprise, qui aura pu être durci au préalable en tirant les leçons des investigations passées.
Adapter la solution à son contexte
Plusieurs paramètres sont à prendre en considération lorsqu’on planifie sa stratégie de reconstruction de postes. En effet, une solution pourrait fonctionner pour une entreprise, mais être inadaptée pour une autre.
Par exemple, de nombreuses mesures de sécurité et de contrôle d’accès ont été mis en place ces dernières années concernant l’accès au réseau interne des postes de travail. Le NAC (Network Access Control) est de plus en plus répandu et dans les bâtiments récents, les prises Ethernet accessibles à chaque bureau tendent à disparaître. Les accès Office 365 sont restreints via du conditional access et l’authentification aux passerelles VPN (Virtual Private Network) se fait par certificat sur le poste. Lorsque toutes ces contraintes existent, une stratégie pour les premiers jours de crise basée sur le BYOD (Bring Your Own Device) ne peut être la réponse – en tout cas pas seule.
Également, la façon dont sont gérés les postes est déterminante et ne permet pas forcément d’envisager les mêmes solutions techniques de reconstruction. On retrouve en général deux principales approches :
- D’une part une approche dite « historique » avec des solutions de gestion de flotte s’appuyant sur une architecture classique type Microsoft System Center Configuration Manager (SCCM), qui est aujourd’hui la solution la plus répandue.
- D’autre part une approche plus « moderne » (i.e Modern Management) avec des solutions Cloud de gestion de flotte type Microsoft Intune, qui monte en puissance ces dernières années.
La méthodologie de reconstruction est également à anticiper. Deux méthodes sont envisageables : la restauration et la réinstallation. La restauration représente un retour à un état antérieur de l’environnement (OS et/ou applications et/ou données) grâce à une sauvegarde. La réinstallation, signifie comme son nom l’indique qu’on reconstruit de zéro le poste, en perdant les documents locaux.
Dans le cas des postes de travail, le nombre de documents conservés en local tend à diminuer. En effet, la plupart des documents sont à présent stockés dans des serveurs de fichiers (NAS ou Sharepoint) pour le travail en commun, ou au sein du OneDrive personnel de l’utilisateur. Ainsi, on aura tendance à privilégier la réinstallation de zéro des postes, plutôt que de prendre le risque de restaurer le système à un état antérieur, où le ransomware était peut-être déjà présent mais non encore activé. D’autant que les ransomware récents s’attaquent aux points de restauration locaux [2].
Choisir les méthodes de reconstruction les plus adaptées à sa stratégie
Plusieurs méthodes de mise à disposition de poste de travail peuvent être envisagées en fonction de l’état des lieux et de la formalisation des besoins dont nous avons parlé plus haut. Voici une liste des principales solutions que nous avons rencontrées sur le terrain, et notre avis sur les avantages et inconvénients de chaque solution.
- La constitution d’un stock de PC de crise
Méthode souvent appliquée dans les plans de secours classiques (répondant au scénario perte de bâtiment / de site), des PC de crise sont placés dans des caissons type Ergotron, prêt à être utilisés en cas de sinistre. Ils sont connectés au réseau local via l’Ergotron, et reçoivent donc automatiquement les mises à jour. Une stratégie peut également être de se baser sur le stock de roulement des postes dans les services IT, ou de conserver des postes décommissionnés pour constituer un stock de secours.
Notre avis : Si cette approche répond bien aux scénarios de résilience type perte d’un bâtiment / d’un site, elle présente un risque face au ransomware car ces PC seraient compromis au même titre que les autres puisqu’accessibles et visibles sur le réseau local. Il faudrait alors avoir une gestion de ces postes « hors ligne », nécessitant une charge de MCO (Maintien en condition opérationnelle) plus forte puisqu’il faudrait manuellement allumer les PC et les mettre à jour régulièrement. De plus, avoir du matériel dormant non utilisé pose la question de l’optimisation des ressources et de l’empreinte carbone. Cette solution est à considérer pour une population restreinte ayant un temps d’interruption acceptable très faible. Par ailleurs, pour les populations utilisant des clients lourds, il est possible de gagner du temps en les préinstallant sur ces postes dormants.
- L’utilisation de PC non managés, via le BYOD (Bring Your Own Device) ou l’utilisation de « PC grand public » acheté en cas de crise
Cette stratégie est en général associée à un scénario « Total IT Blackout » où l’on considère que l’ensemble du système d’information est compromis et qu’il faut travailler sans lien avec celui-ci. On utilise alors des postes non managés soit personnels soit mobilisables en cas de crise via un contrat avec un fournisseur.
Notre avis : les fonctionnalités de cette solution sont limitées car le poste n’a pas d’accès au VPN de l’entreprise, et si du NAC est déployé, en se rendant sur site le PC n’aura pas non plus accès aux ressources internes encore fonctionnelles. Elle peut cependant être considérée en la couplant avec des mesures de crises qui auront été prévues en amont et permettront d’améliorer les fonctionnalités du poste (coupure d’urgence du NAC ; modification temporaire du Conditional Access O365 avec ouverture sur internet ; stockage de données critiques métier dans un Vault de crise hors du SI pour continuer de travailler). Dans la plupart des cas, cette solution sera surtout réservée aux populations métier, et éventuellement aux populations IT en charge de la reconstruction – en la couplant avec une stratégie de retour sur site et une levée du NAC, permettant l’accès au réseau interne en physique. Cela reste une solution qui peut être très efficace lorsque bien anticipée avec la combinant avec les mesures de crise citées plus haut.
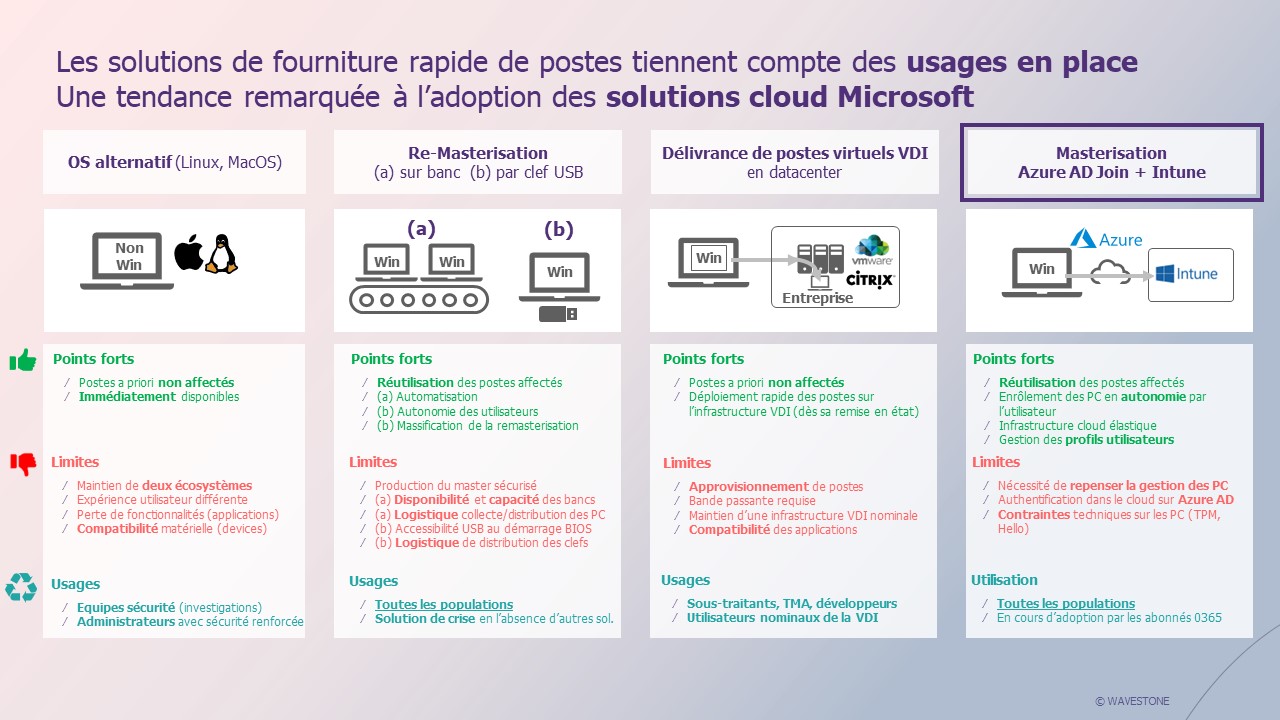
- L’existence nominale de postes sous un autre OS
En cas d’attaque visant les environnements Windows spécifiquement (les plus couramment rencontrés sur le terrain), les ordinateurs impactés peuvent être remplacés par la solution fonctionnant sur un autre OS.
Notre avis : cette solution implique un MCO (Maintien en Conditions Opérationnelles) d’au moins deux technologies, et elle ne garantit pas que les utilisateurs travaillants habituellement sous Windows pourront travailler sous Linux ou MacOS (clients lourds non compatibles, etc.). Cependant, c’est une solution tout à fait envisageable pour des populations très précises, comme les équipes d’investigation. Ces équipes préfèrent en général utiliser des distributions spécifiques comme Kali Linux, et ce sont les personnes qui doivent avoir accès au SI dans les premières heures de la crise.
- La remasterisation des postes de travail sur banc
En cas de crise, les équipes se rendent dans les différents sites possédant des bancs de masterisation avec leur PC compromis pour être remasterisé. Même dans les entreprises les plus conséquentes, les bancs de remasterisation de run ont une capacité de reconstruction limitée (quelques centaines de postes/jour maximum par site). Pour augmenter cette capacité, des bancs de remasterisation supplémentaires de crise peuvent également être prévus dans le cadre d’un contrat avec un fournisseur externe.
Notre avis : la méthode de remasterisation en mode nominal sur banc demande une bonne préparation en amont pour être efficace en cas de crise au vu du volume de poste à reconstruire. Il convient d’avoir préparé un plan pour organiser le retour sur site de nombreuses personnes en parallèle (répartition par site, communication aux utilisateurs sur les créneaux de passage, etc.) en fonction de la capacité de remasterisation des bancs par site physique.
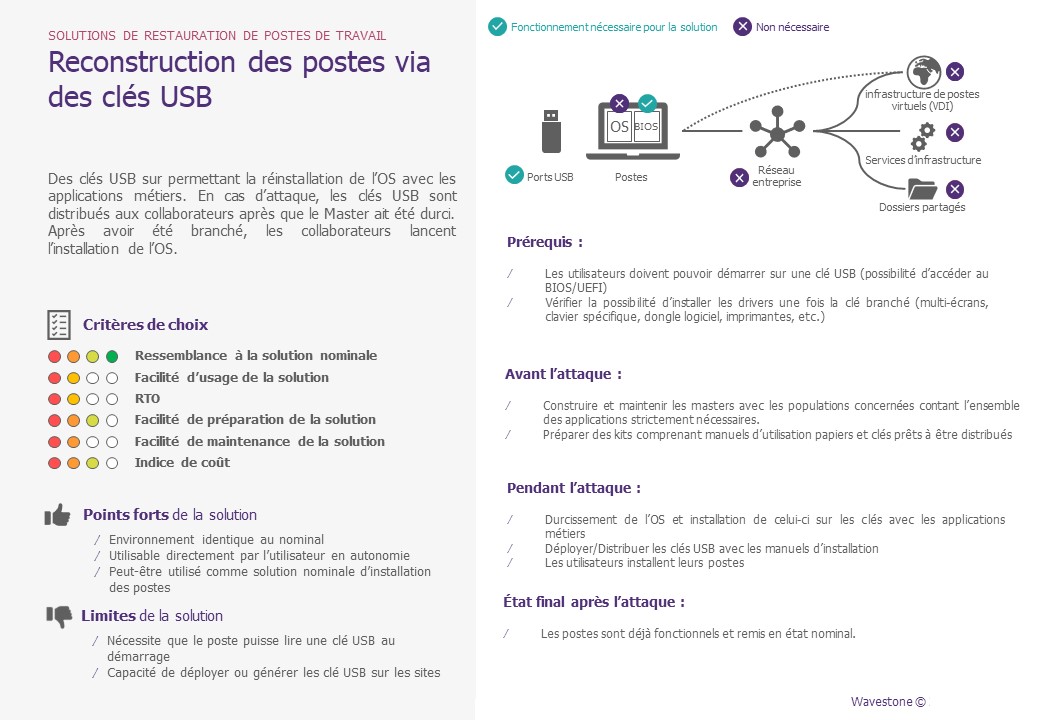
- La remasterisation des postes de travail via clés USB
En cas de crise, des clés USB préparée en amont (ou à générer pendant la crise avec une procédure prédéfinie) avec une image de Windows sont utilisées pour réinstaller un OS neuf sur la machine. Cela peut être un OS Windows vierge, ou une image propre à l’entreprise.
Notre avis : méthode éprouvée sur le terrain en cas de crise qui peut permettre de gagner beaucoup de temps si elle est anticipée. Il faut disposer d’un nombre suffisant de clés USB, avec une image de Windows récente, et une méthode pour cloner rapidement les clés. Il convient également de définir un moyen de distribuer ces clés aux utilisateurs (soit en amont de la crise mais cela complexifie la mise à jour des clés et il existe risque de perte des clés – ou alors pendant la crise en se rendant en kiosque IT, comme pour les bancs). Aussi, il est nécessaire de pouvoir booter sur un média externe. Si cette fonctionnalité est bloquée dans le BIOS, cette méthode ne peut fonctionner, ou en tout cas pas sans une procédure de levée de cette restriction. Cette méthode peut se combiner avec les bancs pour maximiser le nombre de poste à remasteriser en parallèle sur site (une partie des PC passent sur les bancs, l’autre partie lancent le process via clé USB). De même, en cas de compromission du bootstrap du poste, une clef USB avec un Windows vierge peut se combiner avec une remasterisation Intune dans un second temps.
- L’utilisation de VDI de crise (Virtual Desktop Infrastructure)
Des utilisateurs se connectent à un bureau virtuel à distance, via un navigateur. Cette solution doit nécessairement se combiner avec une autre (BYOD, PC grand public acheté pour l’occasion, ou autre) car il est nécessaire d’avoir un PC pour se connecter à la VDI distante. Les VDI peuvent présenter des fonctionnalités plus ou moins avancées en fonction de leur lien avec le SI de l’entreprise (accès au réseau interne, pré-installation de client lourd, etc.)
Notre avis : Ce système permet d’avoir des environnements de travail rapidement opérationnels, en limitant le risque de fuite de données puisqu’il est possible d’interdire le copier/coller des VDI vers le poste hôte. Par ailleurs, en s’appuyant sur des VDI dans le Cloud, il est possible d’avoir un fort potentiel de scale-up (passer de 1 VDI à 200 VDI actives très rapidement en cas de crise). Le principal risque reste que plus l’infrastructure VDI est corrélée au SI de l’entreprise, plus la probabilité qu’elle soit elle aussi compromise par l’attaque est grande. Et dans ce cas, se reposer uniquement sur cette solution est un pari risqué. A l’inverse, une VDI complètement décorrélée du SI fonctionnera, mais présentera des fonctionnalités limitées sans aucun accès aux briques non compromises du SI de l’entreprise.
- La re-masterisation depuis le Cloud via Intune
Le master déployé sur les postes de travail est externalisé dans Intune, un service SaaS hébergé dans le cloud Microsoft. Au démarrage ou après un reset d’usine, le poste de travail demande à l’utilisateur de renseigner son email Microsoft et identifie ainsi son appartenance à l’entreprise, ce qui déclenche le téléchargement et l’installation automatique du master, sans autre intervention nécessaire. Avec un prérequis de taille, puisqu’il faut que sa flotte soit gérée nativement via Intune pour pouvoir utiliser ces méthodes.
Notre avis : Cette méthode est parmi les plus efficaces, notamment car il est possible de modifier l’image (en cas de compromission passant par un protocole vulnérable / un défaut de patching), puis lancer à distance et depuis Intune une remasterisation massive des postes de travail compromis. Il est également possible de réaliser cette remasterisation en self-service du côté de l’utilisateur, mais un prérequis existera alors : posséder la clé de récupération BitLocker (ou autre technologie de chiffrement le cas échéant) du poste, si le disque dur du poste est chiffré dans le cadre des mesures de protection du poste déployé par l’entreprise. Pour des raisons de praticité le jour de la crise, la remasterisation de masse lancée depuis la console Intune est donc à privilégier, ce qui permet de s’affranchir de la contrainte BitLocker. Encore faut-il garantir l’accès à Intune par les administrateurs pour pouvoir le faire – et considérer qu’Intune lui-même ne serait pas compromis. Enfin, même si cela est peu commun, si le ransomware détruit le bootstrap du poste, il ne sera pas possible de le remasteriser avec Intune seul et il faudra alors ajouter l’installation d’un Windows vierge sur le poste en prérequis (via une clef USB par exemple).
A noter qu’il existe également quelques cas exceptionnels de crise dans lesquels, du fait de moyens d’intervention et de gestion limités, certaines organisations peuvent choisir d’autoriser les collaborateurs à travailler en mode dégradé sur des machines compromises pendant une durée déterminée si elles sont encore opérationnelles. Cela peut être notamment le cas lorsque seuls les fichiers bureautiques ont été chiffrés, que le malware est passif et ne communique pas avec un Command and Control, et en supprimant l’accès à internet des postes pour éviter toute prise de contrôle à distance.
En synthèse, quels facteurs de réussite pour une stratégie de résilience de l’environnement bureautique ?
Il n’existe pas de solution « magique » adaptée à tous les cas de figure, chaque solution répond bien au besoin de retrouver un poste de travail opérationnel mais le choix de la meilleure solution dépend de plusieurs paramètres propres à chaque organisation. Aussi afin de s’assurer une stratégie efficace, il est important de :
- Segmenter les différentes populations de l’entreprise afin de définir la priorisation de mise à disposition des postes, et de proposer des solutions adaptées aux besoins spécifiques de chacune.
- Diversifier et adapter les solutions retenues. Tout miser sur une solution peut s’avérer dangereux si celle-ci venait à se révéler défaillante. Le but est bien d’avoir une boîte à outil de solutions techniques, que la cellule de crise pourra choisir d’activer ou non en fonction de la nature exacte de la crise rencontrée.
- Tester les solutions : quelles que soient les solutions et les stratégies mises en œuvre pour la reconstruction de postes, elles doivent systématiquement s’accompagner de la planification de tests. Une solution qui n’est pas utilisée régulièrement est une solution qui risque de ne pas fonctionner en cas de crise. Il faut donc lorsque cela est possible utiliser la solution de secours en day to day pour remasteriser des PC, ou si on parle de VDI, que ces VDI soient utilisées régulièrement. Si cela n’est pas possible, il faut intégrer la solution dans un plan de test de continuité métier et/ou IT, afin de la tester en condition réelle a minima une fois par an.
Les solutions les plus utilisées sur le terrain comprennent les remasterisation de masse sur banc, la constitution d’un stock de poste de travail de crise, l’utilisation des solutions Cloud type Intune et de bureau virtuel type VDI couplé au BYOD. Mais ces solutions prises une à une ne peuvent suffire, car comme indiqué sur le principe de diversification, mettre tous ses œufs dans le même panier peut poser problème. On pourrait par exemple imaginer une crise où l’accès à la console Intune est impossible et/ou l’image Intune elle-même a été altérée par l’attaque. Dans ce cas, avoir une solution de repli type VDI externe ou remasterisation par clef USB est indispensable.
[1] https://fr.wavestone.com/fr/insight/cyberattaques-en-france-le-ransomware-menace-numero-1/

