
Dans près de 90% des incidents gérés par le CERT Wavestone [1], le domaine Active Directory était compromis : se doter de capacités de reconstruction rapide n’est plus une option. Pour autant, la sauvegarde et la restauration d’environnements Active Directory est un sujet supposé sous contrôle de longue date : des sauvegardes sont effectuées quotidiennement, des tests de restauration sont opérés régulièrement et très souvent, des tests de PRA/PCA sont menés afin de s’assurer des capacités de reprise et continuité d’activité. Mais très souvent, ces processus n’ont pas évolué depuis plusieurs années et n’ont pas suivi l’évolution de la menace cyber.
La réflexion sur la bonne manière de traiter ce sujet dans les organisations se trouve à la croisée des projets de renforcement de la sécurité de l’AD et des projets de cyber-résilience.
Infrastructure et agent de sauvegarde : un point faible voire un vecteur de compromission
Nos différents états des lieux réalisés ces derniers mois nous le montrent : les stratégies de sauvegarde n’ont pas toujours évolué vers l’état de l’art.
Premier problème : les infrastructures de sauvegarde ne sont pas résilientes au risque cyber par défaut. L’authentification sur ces infrastructures de sauvegardes est par exemple très souvent liée à l’Active Directory lui-même. Par rebond, le système de sauvegarde pourrait être compromis par l’attaquant, induisant une potentielle destruction des sauvegardes… y compris celles de l’Active Directory !
Et les sauvegardes sont une cible de choix pour les attaquants. Dans plus de 20% des incidents gérés par le CERT Wavestone en 2021, les sauvegardes étaient impactées. Il convient donc d’intégrer le scénario cyber – et tout particulièrement le scénario rançongiciel – lorsque l’on pense à la résilience des sauvegardes.
Deuxième problème : les sauvegardes des Domain Controllers (DC) sont hébergées dans l’outil de sauvegarde, qui a souvent un niveau de sécurité plus faible que celui d’Active Directory. En effet, une organisation ayant déjà mené des travaux de sécurisation d’AD aura potentiellement fortement renforcé son tier 0 (l’on revient toujours au tiering !) : mise en place de postes dédiés pour l’administration, authentification multi-facteurs, filtrage réseau, matériel dédié, limitation du nombre de comptes à privilèges, etc. Cela ne sera hélas pas forcément le cas pour l’infrastructure de sauvegarde. Ces sauvegardes n’étant pas nécessairement chiffrées, un attaquant pourrait la récupérer et l’exfiltrer d’un DC en passant par l’infrastructure de sauvegarde, plus facile à compromettre. Une fois la sauvegarde exfiltrée, l’attaquant sera en mesure d’étendre encore son périmètre de compromission via une attaque de type pass the hash, après récupération des condensats ou encore une attaque par force brute, après extraction des secrets de la base ntds.dit pour récupérer des mots de passe en clair à rejouer sur des services dont l’authentification ne se base pas sur Active Directory.
Troisième problème : les méthodes traditionnelles de sauvegarde reposent sur des agents installés sur les Domain Controllers, dont les hauts privilèges servent parfois de vecteurs de compromissions. Les agents de sauvegarde nécessitent pratiquement toujours des droits d’administration sur l’actif sauvegardé, ce qui expose mécaniquement le Domain Controllers et donc les domaines Active Directory. L’on arrive donc à la situation paradoxale où la mesure de réduction de risque d’indisponibilité (installation d’un agent de sauvegarde sur un DC) devient elle-même la vulnérabilité à l’origine d’un risque pouvant devenir critique (indisponibilité de l’ensemble du système d’informations).
Sauvegarde sur média déconnecté, immuable ou dans le cloud : de multiples stratégies pour de multiples cas de figure
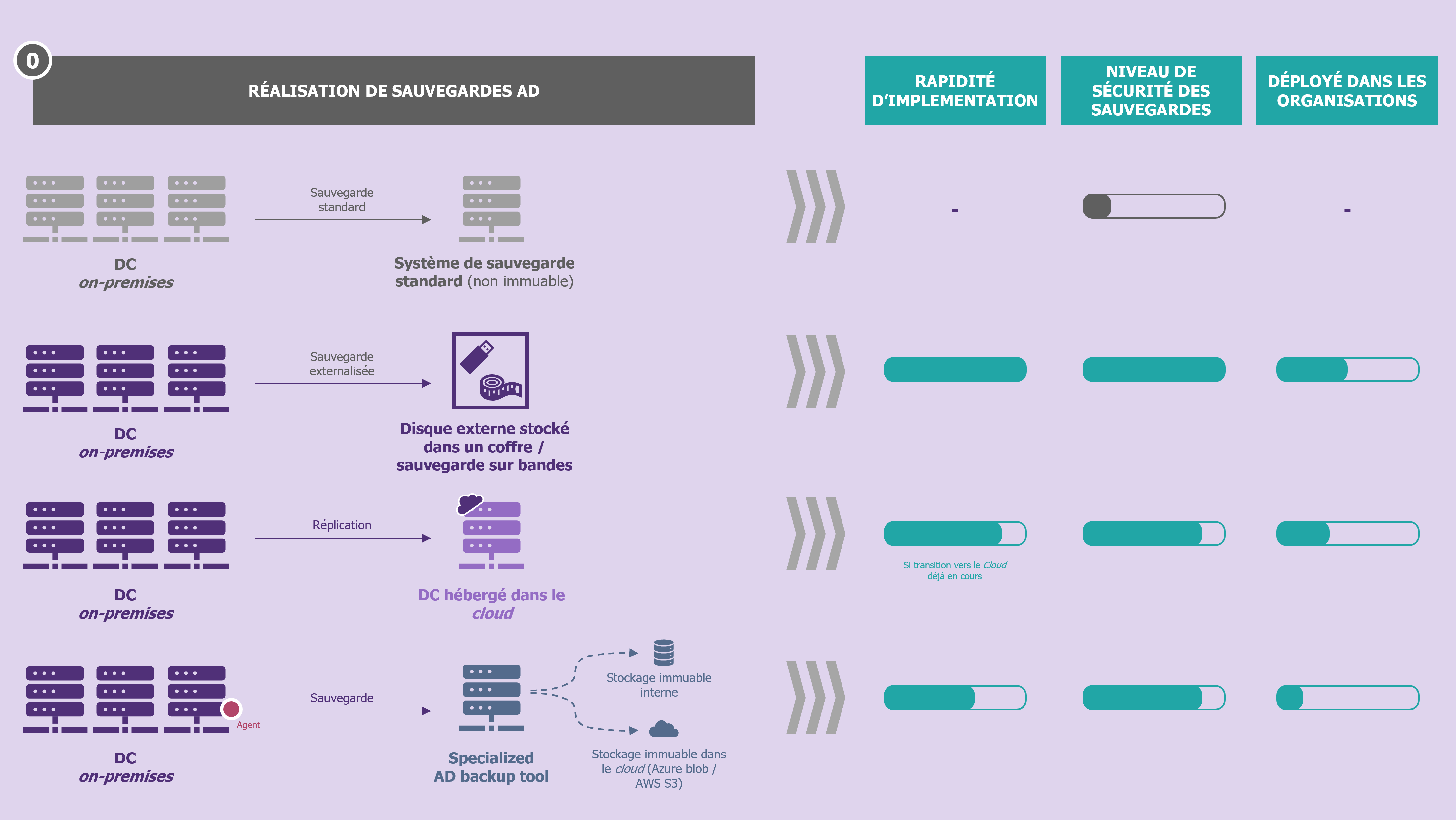
Pour résoudre ces deux problèmes, de multiples solutions existent et leur combinaison permet de construire une stratégie robuste. Cette stratégie doit prendre en compte le contexte de l’organisation ainsi que sa maturité en matière de cybersécurité.
Pour pallier le premier problème induit par l’agent vulnérable deux approches existent, toutes les deux viables :
- Diminuer la probabilité d’exploitation de la vulnérabilité induite par l’agent de sauvegarde. Cela passe, au-delà des classiques sujets de maintien en condition de sécurité (mise à jour régulière, correction rapide de vulnérabilités de l’agent, etc.), par l’intégration d’un outil de sauvegarde dédié dans le tier 0, dont le niveau de sécurité aura été renforcé.
- Se débarrasser de l’agent de sauvegarde. Comment ? En utilisant la fonction de sauvegarde native de Windows (Windows Backup), qui permet de réaliser et d’exporter une sauvegarde, que l’on pourra chiffrer et sortir du tier 0, vers un actif du tier 1, qui lui-même pourra être sauvegardé par la solution standard de sauvegarde de l’entreprise.
Pour renforcer la résilience des sauvegardes de l’Active Directory, plusieurs mesures doivent autant que possible se combiner :
- Externaliser la sauvegarde sur média (version hors ligne). La première déclinaison peut être mise en place rapidement et à faible coût : un disque dur externe à déconnecter une fois la sauvegarde faite. Il s’agit simplement de mettre en place le processus organisationnel associé pour que l’action humaine puisse être faite sans oubli. La seconde déclinaison, pour les rares organisations qui en sont encore dotées, est de s’appuyer sur le système de sauvegarde sur bandes. Dans ce cas aussi, un point d’attention est de rigueur : la sauvegarde et l’externalisation régulière du catalogue de sauvegarde, pour ne pas perdre de temps en cas de restauration, dans le cas où celui-ci a disparu lui aussi (histoire s’inspirant de faits réels rencontrés par nos équipes de réponse à incident). Point d’attention : la sauvegarde sur bandes doit être vue comme un dernier recours pour s’assurer de conserver une copie des données, en cas de scénario catastrophe. En effet, ce format de sauvegarde ne se prête pas à la reconstruction rapide, en raison de délais incompressibles conséquents, avant même de pouvoir commencer à restaurer sur le SI de production : délai de rapatriement des bandes et délai la lecture de leur contenu.
- Externaliser la sauvegarde en dehors du système d’information (version en ligne). Que cela soit réalisé à l’aise de scripts maison ou de solutions du marché (voir notre radar), après chiffrement robuste, une sauvegarde peut être externalisée. L’avantage des solutions du marché est qu’elles intègrent directement la partie reconstruction rapide (cf. partie suivante) d’un DC.
- S’appuyer sur une sauvegarde complémentaire mais indépendante. Pour augmenter la disponibilité de l’infrastructure de sauvegarde, il suffit de la redonder en s’assurant qu’il n’y ait pas de risque de compromission simultanée. Pour cela, profitant de leur transition vers le cloud, de nombreuses organisations ont choisi récemment d’ajouter un DC supplémentaire, mais hébergé dans le cloud (les autres étant traditionnellement encore on-premises), bénéficiant ainsi naturellement des mécanismes de sauvegarde qui lui est propre. Du fait des mécanismes de réplication internes à AD, le DC hébergé dans le cloud sera compromis (compromission de certains comptes ou de certaines configurations d’AD) dans la même échelle de temps que ceux on-premises, mais l’étanchéité entre actifs sauvegardés et système de sauvegarde étant supposé meilleur dans le cloud, l’on aura plus de chance d’avoir une sauvegarde d’un DC encore disponible.
- Rendre son infrastructure de sauvegarde immuable, en s’appuyant au maximum sur les solutions proposées par les éditeurs des logiciels de sauvegarde. En effet, la plupart des éditeurs proposent désormais des mécanismes d’immuabilité, qui parfois ne nécessitent pas l’achat de baies de stockage supplémentaires. En rendant les sauvegardes immuables sur leur stockage primaire, on s’assure d’un temps de reconstruction optimal puisqu’il ne sera pas nécessaire de rapatrier les sauvegardes depuis un stockage hors ligne (axe 1) ou en ligne (axe 2) avant de pouvoir commencer à restaurer. N.B.: l’axe 2 peut et doit bénéficier de ce concept (Amazon S3, Azure blob, etc.).
| Sauvegarde immuable : l’adage souvent associé est « write once, read many », résumant bien ce concept. Il s’agit d’une sauvegarde reposant sur des fichiers dont l’état ne peut pas être modifié après leur création, le rendant ainsi résistant aux attaquants essayant de les supprimer. En pratique, ni l’administrateur du logiciel de sauvegarde, ni l’administrateur des baies de stockage, ne peuvent supprimer ou altérer une sauvegarde identifiée comme immuable. |
Enfin, dernier point de détail, connaître quel(s) DC sauvegarder et utiliser pour la restauration en cas de besoin est indispensable (DC Global Catalog, version d’OS la plus récente, etc.), tout comme la fréquence (sûrement quotidienne) et la durée de rétention (sujet beaucoup plus subjectif).
Reconstruction rapide : des capacités souvent incomplètement testées
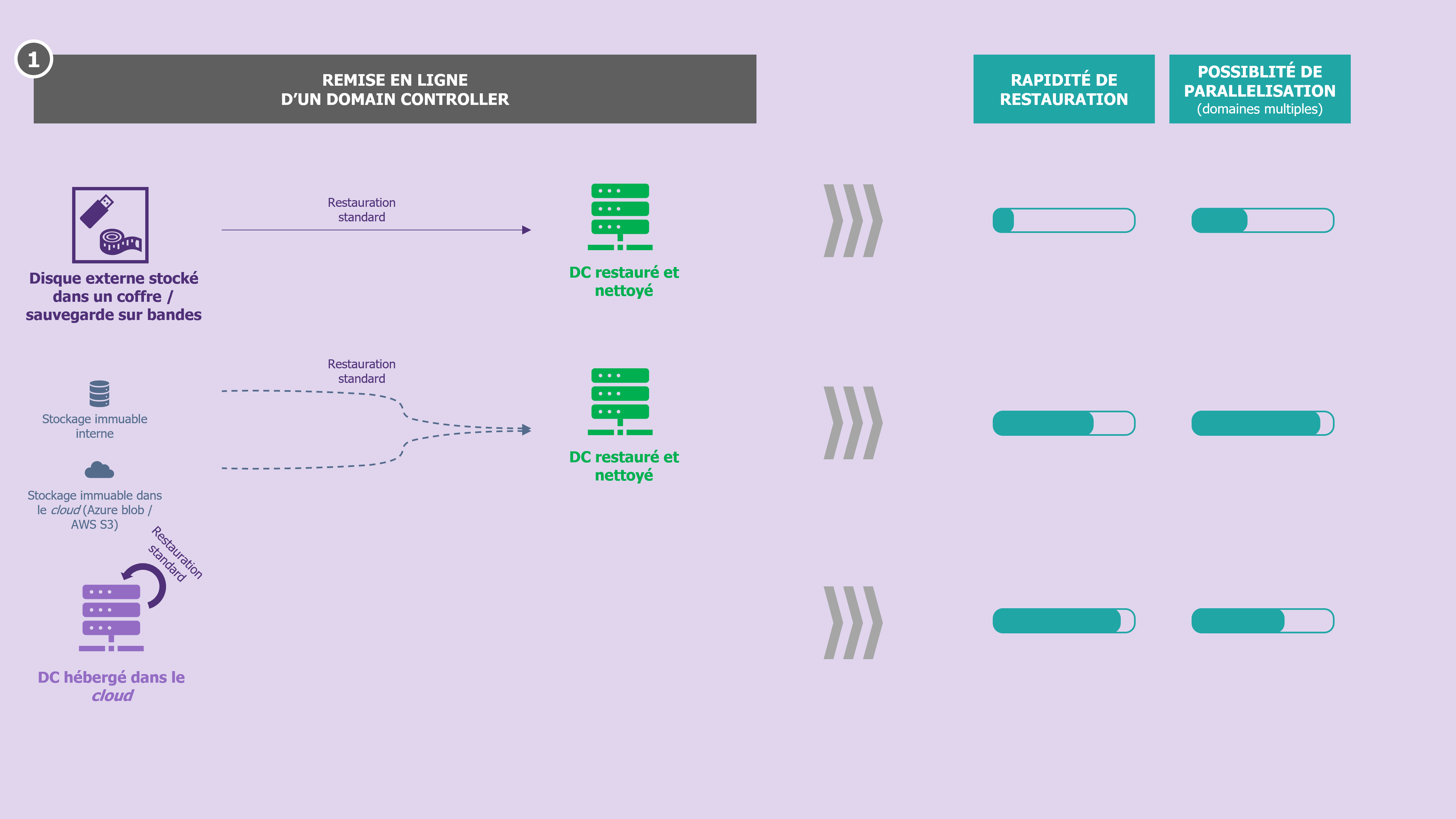
Les tests de reconstruction sont aussi vieux que le concept de PCA/PRA. Mais là encore, l’on ne peut pas juste reposer sur ces tests annuels pour se considérer prêt, à la lumière de l’état de la menace. En effet, ces tests reposent très souvent sur des hypothèses qui ne seront pas vérifiées en cas de cyberattaque majeure : sauvegardes disponibles, confiance dans l’état du système d’information, outils collaboratifs (poste de travail, messagerie, outil de ticketing, etc.) fonctionnels, infrastructure d’accueil cible prête et disponible, etc.
De ce que l’on observe dans les organisations, les temps affichés et communiqués sur les temps de reconstruction d’un domaine AD sont souvent sous-estimés a priori. Les temps de déclenchement et d’arrêt du chronomètre sont bien souvent discutables : déclenchement au moment où l’on appui sur le bouton de démarrage de la restauration de la sauvegarde, arrêt au moment où un DC est restauré et opérationnel (procédure AD forest recovery exécutée [2]). Pour autant, l’on fait souvent fi de certains points qui peuvent difficilement être écartés pour comparer cette durée à celle du RTO :
- dépendance non satisfaite à un autre domaine indispensable (domaine présentant une ou plusieurs relation(s) d’approbation avec d’autres domaines) ;
- capacité à tenir la charge d’authentification que représentera une réouverture de service ;
- temps d’exécution des opérations de « toilettage » (changement de mot de passe en masse, désactivation de certains services ou compte, remise au propre dans les objets et les groupes, etc.) ;
- etc.
Lorsque l’infrastructure AD est paralysée par une cyberattaque majeure, sa reconstruction deviendra rapidement la priorité de la cellule de crise, en raison de la dépendance des applications et utilisateurs à celle-ci. C’est d’ailleurs un service dont le RTO est le plus faible. Dans le cas où les sauvegardes sont disponibles, se posent rapidement certaines questions qui doivent nourrir la stratégie de cyberdéfense que l’on est en train de définir (voir notre Top 10 des pièges à éviter pour une gestion de crise rançongiciel réussie) :
- Faut-il avoir une zone permettant d’accueillir la future infrastructure saine ?
- La création des utilisateurs dans Azure AD durant la crise permet-elle de rouvrir le service plus rapidem ent ?
- Dans le cas où il existe de nombreux domaines AD (cas des très grandes organisations) dans quel ordre procéder ?
Sur le volet infrastructure, d’abord, dans la vaste majorité des cas, disposer d’une zone isolée et sécurisée de reconstruction permet de gagner du temps. Celle-ci doit être disponible, prête à accueillir le nombre de VM permettant d’atteindre le niveau service considéré comme acceptable dans une telle situation et à la main (comptes avec les droits suffisants, accessibilité, etc.) de l’équipe responsable du service Active Directory uniquement. Cela pour réduire le risque de compromission mais aussi pour ne pas créer de freins (demandes à effectuer à une autre équipe) le jour où le besoin survient.
Cette zone peut-être on-premises ou dans un service cloud, dépendamment des coûts et de la posture cybersécurité de l’organisation quant à l’hébergement de DC sur un cloud (dans le cas où celui-ci est public). Cette zone dormante peut d’ailleurs être mise à profit pour accueillir les tests de restauration réguliers de l’Active Directory, pour être au plus proche d’une situation réelle. Enfin, cette infrastructure doit évidemment être dans le tier 0, si l’organisation s’appuie sur ce framework.
Sur le volet des processus, ensuite, il convient de préparer en amont plusieurs informations indispensables le jour où le besoin de reconstruire le service surviendra :
- déterminer le nombre de DC minimal ainsi que leur localisation (zone de reconstruction dans le cloud / on-premises, mais également géographiquement en cas de présence sur de multiples plaques) ;
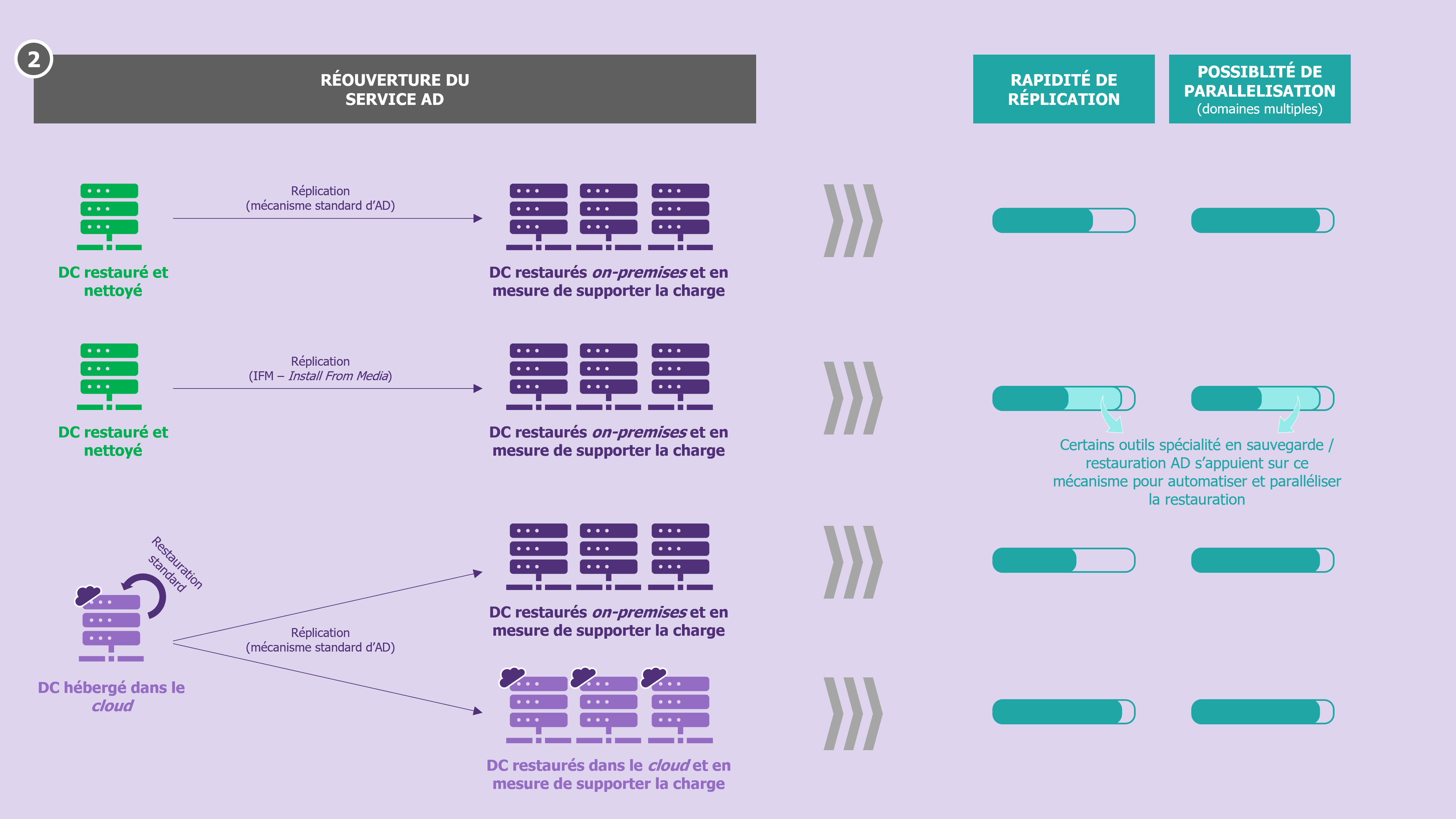
- déterminer la méthode de réplication (réplication standard ou recours à IFM [3]) des DC permettant de minimiser le temps entre la disponibilité du premier et du dernier DC nécessaire à la réouverture du service ;
- des règles de filtrage prêtes et désactivées, qu’il suffira d’activer avant l’ouverture du service ;
- du niveau de risque acceptable pour la reconstruction (reconstruction simple et « toilettage » des objets ou méthode du pivot) ;
- (dans les organisations avec de multiples domaines servant plusieurs métiers) une séquence de reconstruction, qu’il aura fallu déterminer au-préalable avec les responsables métier, pour rouvrir le service selon les bonnes priorités.
Ici aussi, les outils de sauvegarde / restauration spécialisés AD apportent de la valeur : ils permettent d’exécuter la procédure de restauration d’une forêt AD en quelques clics et de manière automatisée. La parallélisation de ces opérations est également rendue possible, faisant de ces outils un accélérateur indéniable à considérer pour les organisations possédant de nombreuses forêts !
Sur le volet des ressources, enfin, il convient de disposer d’une organisation permettant de répondre à cette surcharge de travail ponctuelle mais très importante. Pour cela, l’automatisation des activités de reconstruction qui peuvent l’être, mais également le fait d’avoir des ressources ayant déjà pratiqué l’exercice à de multiples reprises s’avère souvent décisif.
Certaines organisations profitent des tests de Disaster Recovery (DR) pour simuler la pire situation possible pour le service Active Directory, plutôt que de simplement simuler une reprise seulement partielle. C’est indubitablement une bonne pratique.
En définitive, se poser la question de la résilience de son infrastructure Active Directory tire le sujet plus global de la résilience du système d’information, mais également celui du tiering, celui des exercices grandeur nature, à mener régulièrement. L’on pourrait même faire un pont avec le DevOps : ne rêverait-on pas de parvenir au redéploiement d’une infrastructure AD quasiment automatiquement, à l’image de ce que parviennent à faire les DevOps grâce au concept d’Infrastructure as Code ? En attendant, l’entraînement régulier reste le seul moyen d’atteindre un degré de sérénité sur ses capacités à rouvrir rapidement un service AD minimal, s’il venait à être entièrement détruit.
[1] https://www.wavestone.com/en/insight/cert-w-2022-cybersecurite-trends-analysis/
[2] https://learn.microsoft.com/fr-fr/windows-server/identity/ad-ds/manage/ad-forest-recovery-guide
[3] Install From Media : https://social.technet.microsoft.com/wiki/contents/articles/8630.active-directory-step-by-step-guide-to-install-an-additional-domain-controller-using-ifm.aspx

