
Le déploiement massif des solutions d’intelligence artificielle au fonctionnement complexe et reposant sur de larges volumes de données dans les entreprises fait poser des risques uniques sur la protection des données personnelles. Plus que jamais, il apparait nécessaire pour les entreprises de revoir leur outillage afin de répondre aux enjeux nouveaux associés aux solutions d’IA qui traiteraient des données personnelles. Le PIA (Privacy Impact Assessment) se propose comme un outil clé pour les DPO dans l’identification des risques liés aux traitements de données personnelles et à la mise en place de mesures de remédiation appropriées. Il constitue également un outil crucial d’aide à la décision pour répondre aux exigences réglementaires.
Nous détaillerons dans cet article les impacts de l’IA sur la conformité des traitements aux grands principes réglementaires mais aussi sur la sécurité des traitements sur laquelle pèsent de nouveaux risques. Nous partagerons ensuite notre vision d’un outil de PIA adapté afin de répondre à des questionnements et enjeux remaniés par l’arrivée de l’IA dans les traitements de données personnelles.
L’impact de l’IA sur les principes de protection des données
Bien que l’IA se développe rapidement depuis l’arrivée de l’IA générative, elle n’est pas nouvelle dans les entreprises. Les nouveautés résident dans les gains d’efficacité des solutions, dont l’offre est plus étoffée que jamais, et surtout dans la multiplication des cas d’usages qui viennent transformer nos activités et notre rapport au travail.
Ces gains ne sont pas sans risques sur les libertés fondamentales et plus particulièrement sur le droit à la vie privée. En effet, les systèmes d’IA nécessitent des quantités massives de données pour fonctionner efficacement, et ces bases de données contiennent souvent des informations personnelles. Ces larges volumes de données font par la suite l’objet de multiples calculs, analyses et transformations complexes : les données ingérées par le modèle d’IA deviennent à partir de ce moment indissociables de la solution d’IA[1]. Outre cette spécificité, nous pouvons mentionner la complexité de ces solutions qui diminue la transparence et la traçabilité des actions opérées par celles-ci. Ainsi, de ces différents aspects caractéristiques de l’IA, en résulte une multitude d’impacts sur la capacité des entreprises à se conformer aux exigences réglementaires en matière de protection des données personnelles.
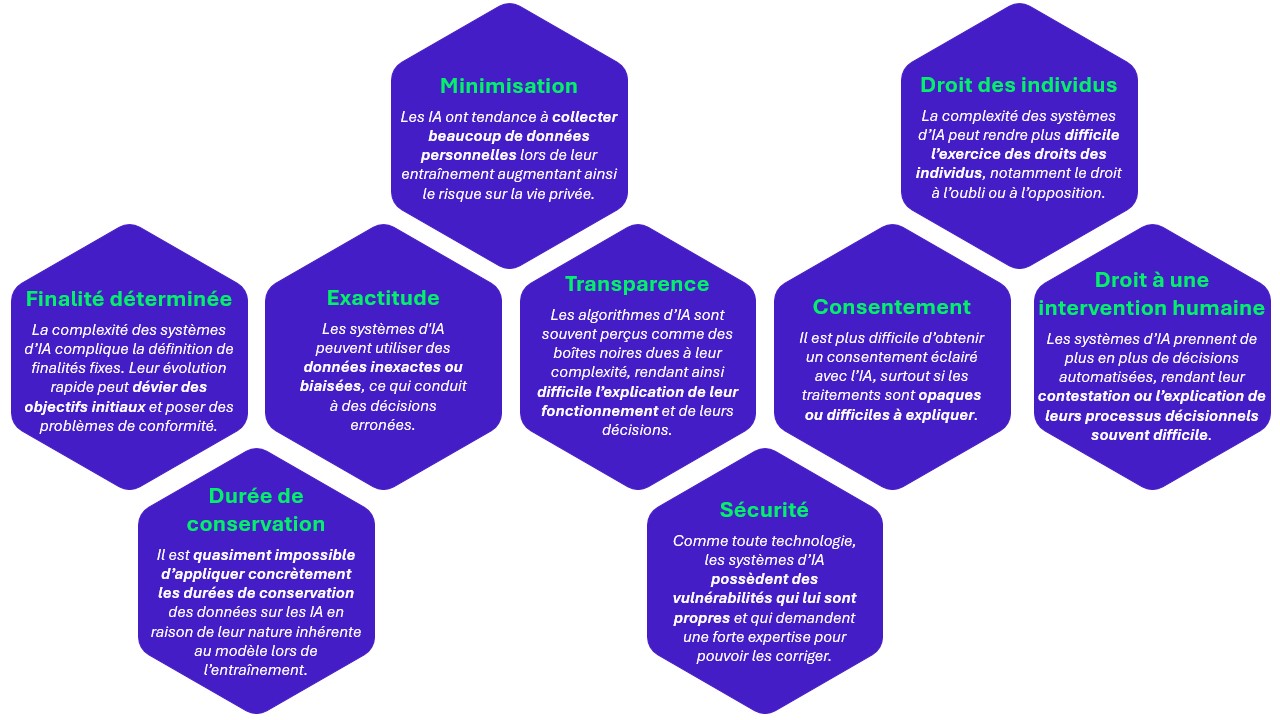
Figure 1 : exemples d’impacts sur les principes de protection des données.
En complément de la Figure 1, trois principes peuvent être détaillés pour illustrer les impacts de l’IA sur la protection des données ainsi que les nouvelles difficultés auxquelles les professionnels de ce domaine seront confrontés :
- Transparence: Assurer la transparence devient bien plus complexe en raison de l’opacité et de la complexité des modèles d’IA. Les algorithmes de machine learning et de deep learning peuvent être des « boîtes noires », où il est difficile de comprendre comment les décisions sont prises. Les professionnels doivent relever le défi de rendre ces processus compréhensibles et explicables, tout en garantissant que les informations fournies aux utilisateurs et aux régulateurs soient claires et détaillées.
- Principe d’exactitude: Appliquer le principe d’exactitude est particulièrement difficile avec l’IA en raison des risques de biais algorithmiques. Les modèles d’IA peuvent reproduire ou même amplifier les biais présents dans les données d’entraînement, ce qui conduit à des décisions inexactes ou injustes. Les professionnels doivent donc non seulement s’assurer que les données utilisées sont précises et à jour, mais aussi mettre en place des mécanismes pour détecter et corriger les biais algorithmiques.
- Durée de conservation: La gestion de la durée de conservation des données devient plus complexe avec l’IA. L’entraînement des modèles d’IA avec des données crée une dépendance entre l’algorithme et les données utilisées, rendant difficile, voire impossible, de dissocier l’IA de ces données. Aujourd’hui, il est pratiquement impossible de faire « oublier » à une IA des informations spécifiques, ce qui complique la conformité avec les principes de minimisation des données et de durée de conservation.
Les nouveaux risques soulevés par l’IA
Outre les impacts sur les principes de conformité abordés à l’instant, l’IA produit également des effets significatifs sur la sécurité des traitements, modifiant ainsi les approches en matière de protection des données et de gestion des risques.
L’utilisation de l’intelligence artificielle fait alors ressortir 3 types de risques sur la sécurité des traitements :
- Risques traditionnels: Comme toute technologie, l’utilisation de l’intelligence artificielle est sujette à des risques de sécurité traditionnels. Ces risques incluent, par exemple, des failles au niveau des infrastructures, des processus, des personnes et des équipements. Qu’il s’agisse de systèmes traditionnels ou de solutions basées sur l’IA, les vulnérabilités en matière de sécurité des données et de gestion des accès persistent. Les erreurs humaines, les pannes matérielles, les mauvaises configurations de systèmes ou les processus insuffisamment sécurisés demeurent des préoccupations constantes, indépendamment de l’innovation technologique.
- Risques amplifiés: L’utilisation de l’IA peut également exacerber des risques déjà existants. Par exemple, l’utilisation d’un grand modèle de langage, comme Copilot, pour assister dans les tâches quotidiennes peut poser des problèmes. En se connectant à toutes vos applications, le modèle d’IA centralise toutes les données en un seul point d’accès, ce qui augmente considérablement le risque de fuite de données. De la même manière, une gestion des identités et des droits des utilisateurs imparfaite aboutira à des risques accrus d’actes malveillants en présence d’une solution d’IA capable d’accéder et d’analyser avec une efficacité singulière à des documents illégitimes pour l’utilisateur.
- Risques émergents: De la même manière que pour les risques liés à la durée de conservation, il devient de plus en plus difficile de dissocier l’IA de ces données d’entrainements. Cela peut parfois rendre l’exercice de certains droits comme le droit à l’oubli bien plus difficile, entrainant un risque de non-conformité.
Un contexte réglementaire en mutation
Avec la prolifération mondiale des outils basés sur l’intelligence artificielle, divers acteurs ont intensifié leurs efforts pour se positionner dans ce domaine. Pour répondre aux préoccupations, plusieurs initiatives ont vu le jour : le Partnership on AI réunit des géants technologiques comme Amazon, Google, et Microsoft pour promouvoir une recherche ouverte et inclusive sur l’IA, tandis que l’ONU organise l’AI for Good Global Summit pour explorer l’IA au service des objectifs de développement durable. Ces initiatives ne sont que des exemples parmi de nombreuses autres initiatives visant à encadrer et guider l’utilisation de l’IA, assurant ainsi une approche responsable et bénéfique de cette technologie.

Figure 2 : exemples d’initiatives liées au développement de l’IA.
Le changement récent et le plus impactant est l’adoption de l’AI Act (ou RIA, règlement européen sur l’IA), qui introduit une nouvelle exigence dans l’identification des traitements de données à caractère personnel devant bénéficier d’un soin particulier : en plus des critères classiques des lignes directrices du G29, l’utilisation d’une IA à haut risque nécessitera systématiquement la réalisation d’une PIA. Pour rappel, le PIA est une évaluation qui vise à identifier, évaluer et atténuer les risques que certains traitements de données peuvent poser à la vie privée des individus, en particulier lorsqu’ils impliquent des données sensibles ou des processus complexes. Ainsi, l’utilisation d’un système d’IA requerra souvenant la réalisation d’un PIA.
Cette nouvelle législation complète l’arsenal réglementaire européen pour encadrer les acteurs et solutions technologiques, elle vient en complément du RGPD, du Data Act, du DSA ou encore du DMA. Bien que l’objectif principal de l’AI Act soit de promouvoir une utilisation éthique et digne de confiance de l’IA, elle partage de nombreuses similitudes avec le RGPD et renforce les exigences existantes. Nous pouvons par exemple citer les exigences renforcées en matière de transparence ou bien la mise en place obligatoire d’une surveillance humaine pour les systèmes d’IA, soutenant le droit à l’intervention humaine du RGPD.
Une adaptation nécessaire des outils et méthodes
Dans ce contexte évolutif où l’IA et les réglementations continuent de se développer, la veille réglementaire et l’adaptation des pratiques par les différents acteurs sont essentielles. Cette étape est cruciale pour comprendre et s’adapter aux nouveaux risques liés à l’utilisation de l’IA, en intégrant ces évolutions efficacement au sein de vos projets d’IA.
Afin d’adresser les nouveaux risques induits par l’utilisation de l’IA, il devient nécessaire d’adapter nos outils, méthodes et pratiques afin de répondre efficacement à ces défis. De nombreux changements doivent être pris en compte, tels que :
- l’amélioration des processus d’exercice des droits ;
- l’intégration d’une méthodologie Privacy By Design adaptée :
- la mise à niveau des mentions d’information fournis aux utilisateurs ;
- ou encore l’évolution des méthodologies de PIA.
Nous illustrerons dans la suite de cet article ce dernier besoin en matière de PIA à l’aide du nouvel outil interne PIA² conçu par Wavestone et né de la jonction de ses expertises Privacy et en intelligence artificielle, et qui a été alimenté par de nombreux retours terrain. Son objectif est de garantir une gestion optimale des risques pour les droits et libertés des personnes liés à l’utilisation de l’intelligence artificielle en offrant un outil méthodologique capable d’identifier finement les risques sur ces-derniers.
Un nouvel outil de PIA au service d’une meilleure maîtrise des risques Privacy issus de l’IA
La réalisation d’un PIA sur des projets d’IA exige une expertise plus pointue que celle requise pour un projet classique, avec des questionnements multiples et complexes liés aux spécificités des systèmes d’IA. Outre ces points de contrôles et questionnements qui s’ajoutent à l’outil, c’est toute la méthodologie de déclinaison du PIA qui se trouve adaptée au sein du PIA² de Wavestone.
A titre d’illustration, les ateliers avec les parties prenantes s’élargissent à de nouveaux acteurs tels que les data scientists, des experts en IA, des responsables éthiques ou les fournisseurs de solutions d’IA. Mécaniquement, la complexité des traitements de données reposant sur des solutions d’IA requière donc davantage d’ateliers et un temps de mise en œuvre plus important pour cerner finement et pragmatiquement les enjeux de protection des données de vos traitements.
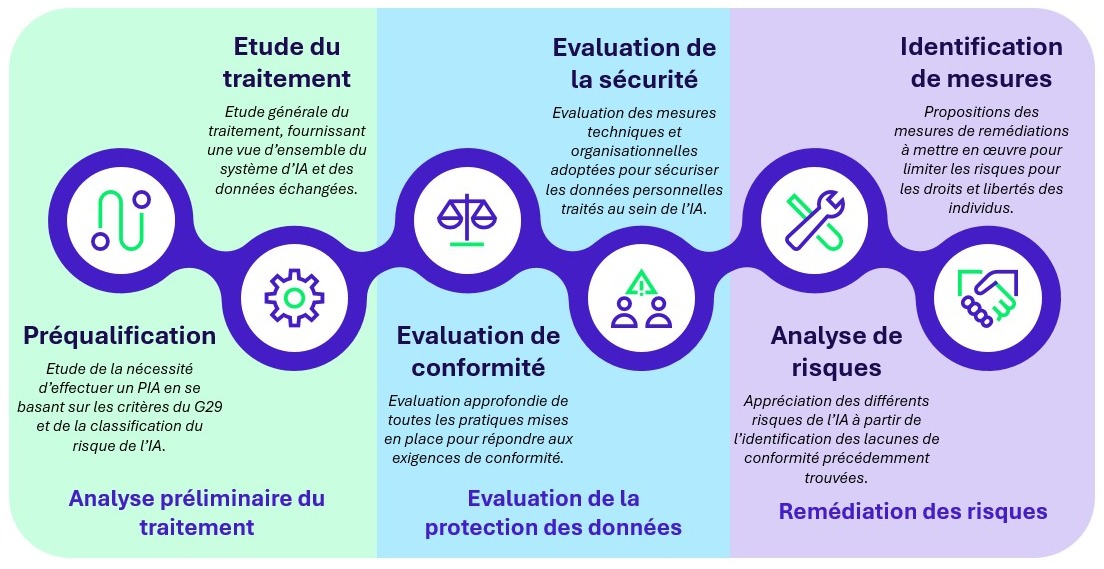
Figure 3 : représentation des différentes étapes du PIA².
Le PIA² renforce et complète la méthodologie de PIA traditionnelle. L’outil conçu par Wavestone est ainsi constitué de 3 étapes centrales :
- Analyse préliminaire du traitement
Dans la mesure où l’IA revêt des risques pouvant être significatifs pour les personnes et dans un contexte où l’AI Act vient exiger la réalisation d’un PIA pour les solutions d’IA à haut risque traitant de données à caractère personnel, le premier questionnement d’un DPO est d’identifier son besoin ou non de réaliser une telle analyse. L’outil PIA² de Wavestone s’ouvre donc sur une analyse des critères traditionnels du G29 venant requérir la mise en œuvre d’un PIA et est ensuite complétée de questionnements associés à l’identification du niveau de risque de l’IA. L’analyse se complète classiquement d’une étude générale du traitement. Cette étude complétée de points de connaissance précis sur la solution d’IA, de son fonctionnement et de son cas d’usage, servant de fondation à l’ensemble du projet (notons que l’AI Act vient également exiger que de telles informations soient présentes dans le PIA portant sur des IA à haut risque). A l’issue de cette étude, le DPO dispose d’une vue d’ensemble des données personnelles traitées, de la manière dont les données personnelles circulent au sein du système et des différentes parties prenantes.
- Evaluation de la protection des données
L’évaluation de conformité permet ensuite d’examiner la conformité de l’organisation vis-à-vis des réglementations applicables en matière de protection des données. L’objectif est d’examiner en profondeur toutes les pratiques mises en place par rapport aux exigences légales, tout en identifiant les lacunes à combler. Cette évaluation se concentre sur les mesures techniques et organisationnelles adoptées pour se conformer aux réglementations et sécuriser les données personnelles au sein d’un système d’IA. Cette partie de l’outil a été spécialement développée pour répondre aux nouveaux enjeux et défis de l’IA en termes de conformité et de sécurisation, prenant en compte les nouvelles contraintes et normes imposées aux systèmes d’IA. Cette évaluation comporte à la fois des points de contrôle classiques d’un PIA et issues du RGPD et se complète des questionnements spécifiques associés à l’IA qui ont profité des retours terrains observés par nos experts en IA.
- Remédiation des risques
Après avoir recensé l’état de la conformité du projet et identifié les lacunes présentes, il est possible d’évaluer les impacts potentiels sur les droits et libertés des personnes concernées par le traitement. Une étude approfondie de l’impact de l’IA sur les différents éléments de conformité et de sécurité a été effectuée pour nourrir cet outil de PIA². Cette approche opérée par Wavestone, si elle est optionnelle, nous a permis de gagner en facilité de réalisation du PIA en permettant une automatisation de notre outil PIA² qui propose automatiquement des risques spécifiques liés à l’utilisation de l’IA au sein du traitement, en fonction des réponses remplies en parties 1 et 2. Les risques étant identifiés, il convient ensuite de réaliser leur traditionnelle cotation en évaluant leur vraisemblance et leurs impacts.
Toujours dans cette optique d’automatisation, l’outil PIA de Wavestone identifie et propose également automatiquement des mesures correctives adaptées aux risques détectés. Quelques exemples : des solutions comme le Federated Learning, le chiffrement homomorphique (qui permet de traiter des données chiffrées sans les déchiffrer) et la mise en place de filtres sur les entrées et sorties peuvent être suggérées pour atténuer les risques identifiés. Ces mesures permettent de renforcer la sécurité et la conformité des systèmes d’IA, assurant ainsi une meilleure protection des droits et libertés des personnes concernées.
Une fois ces trois grandes étapes franchies, il sera nécessaire de faire valider les résultats et de mettre en œuvre des actions concrètes pour garantir la conformité et les risques liés à l’IA.
Ainsi, lorsqu’un traitement implique de l’IA, la réduction des risques devient encore plus complexe. Une veille constante sur le sujet et l’accompagnement d’experts dans le domaine deviennent indispensables. À l’heure actuelle, de nombreuses inconnues subsistent, comme en témoigne la posture de certains organismes encore en phase d’étude ou des positions des régulateurs qui restent à préciser.
Pour mieux appréhender et gérer ces défis, il devient alors essentiel d’adopter une approche collaborative entre différentes expertises. Chez Wavestone, nos expertises en intelligence artificielle et en protection des données ont dû coopérer étroitement pour cerner et répondre à ces enjeux majeurs. Nos travaux d’analyse des solutions d’IA, des nouvelles réglementations afférentes et des risques en matière de protection des données ont nettement mis en lumière l’importance pour les DPO de bénéficier d’une expertise toujours plus pluridisciplinaire.
Remerciements
Nous remercions Gaëtan FERNANDES pour son travail dans la rédaction de cet article.
Notes
[1] : Bien que des expérimentations ambitionnent d’offrir une forme de réversibilité et la possibilité de retirer les données de l’IA, comme le désapprentissage machine, ces techniques restent encore assez peu fiables aujourd’hui.

