
La gestion des droits d’accès aux ressources d’une entreprise est une question centrale de l’IAM. Un modèle d’habilitation apporte une couche d’abstraction qui guide l’attribution des permissions techniques aux utilisateurs et en facilite le suivi dans la durée.
A cette fin, les modèles de droits existants sont nombreux : MAC, DAC, GBAC, ABAC…
Comment comprendre concrètement ces multiples déclinaisons de modèles de droits et les appliquer à son entreprise ?
Les modèles diffèrent dans leur degré de complexité et dans la réponse qu’ils apportent à des besoins et contraintes spécifiques d’une organisation ou d’un système. Les plus récents intègrent des problématiques de sécurité, de scalabilité et de conformité dans un environnement technologique toujours plus complexe.
Dans cet article, nous suivrons une logique chronologique en identifiant comment l’autorisation a évolué au cours des décennies pour répondre aux défis des organisations. Nous verrons, que, comme les systèmes d’information, les approches de modèles de droits se sont complexifiées, et intègrent aujourd’hui de plus en plus de paramètres pour décider d’accorder ou de refuser un accès.
On peut ainsi regrouper les modèles selon 3 approches reflétant leur sophistication progressive :
- Approche classique : l’admin-time
- Approche moderne : run-time
- Approches prospectives : event-time
Nous illustrerons chacune de ces approches par des modèles emblématiques en mettant en évidence :
- la réponse apportée à un besoin initial
- les limitations du modèle.
Et conclurons notre propos par une synthèse chronologique des approches et de leurs modèles.
Approches classiques d’autorisation : Admin-time
Dans les années 60-70, le développement des systèmes informatiques, marqué par la mise au point des premiers systèmes multi-utilisateurs (Multics, HP-3000), fait naître la nécessité de repenser les droits des utilisateurs.
Des principes de sécurité innovants, encore utilisés aujourd’hui, sont ainsi définis sur ces systèmes, à l’instar des anneaux de protection (rings en anglais), qui d’une part, visent à protéger l’intégrité du système d’exploitation contre les modifications volontaires et accidentelles, et d’autre part, initient la réflexion sur les politiques d’accès aux ressources par les utilisateurs.
Dans les premiers modèles de droits d’accès qui émergent, la gestion des droits reste sommaire, définie en dur par des « administrateurs » : c’est l’admin-time, dont on retient en particulier les modèles DAC et MAC (années 60-70) et RBAC (années 90).
Discretionary Access Control (DAC) et Access Control Lists (ACLs)
Comme son nom le suggère, le modèle DAC – pour « contrôle d’accès discrétionnaire » – laisse à chaque propriétaire de ressource le soin d’attribuer les permissions aux utilisateurs. Il est le modèle de droits de base que l’on trouve sur les systèmes Unix, qui peut être complété par le mécanisme d’ACL, des « listes pour le contrôle d’accès ». Souvent associées à DAC, les ACLs spécifient, pour une ressource donnée, les utilisateurs et leurs droits sur la ressource, comme illustré ci-dessous sur l’exemple d’Unix.

Au-delà d’Unix, les systèmes de partage de fichiers tels que OneDrive ou encore les réseaux sociaux, où l’utilisateur peut choisir qui peut voir ou commenter chaque publication, sont d’autres exemples d’utilisation de DAC et des ACLs.
En effet, la flexibilité et la granularité de ce modèle constituent un avantage pour des implémentations locales et centrées sur les individus. En revanche, elles deviennent problématiques pour assurer un niveau correct de protection des ressources à large échelle sur des systèmes plus complexes.
Mandatory Access Control (MAC)
Le modèle MAC, pour « contrôle d’accès obligatoire », prend le contrepied de DAC. Plutôt que de laisser l’assignation des droits à la « discrétion » des utilisateurs, ressource par ressource, limitant la visibilité à l’échelle du système et favorisant de fait erreurs et failles, des règles sont prédéfinies par des administrateurs selon différentes classifications de sécurité et appliquées de façon stricte par une autorité centrale, généralement représentée par le système d’exploitation lui-même.
Il prévaut en particulier dans les milieux gouvernementaux, militaires ou industriels, car il permet un contrôle étroit de l’accès aux données sensibles. Il utilise ainsi des labels qui caractérisent la sensibilité des objets et des utilisateurs, selon les règles de l’organisation concernée :
- Un niveau de classification des ressources, par exemple : « Non classifié », « Restreint », « Confidentiel », « pointe de diamant »[1], …
- Un niveau d’habilitation des utilisateurs, liés aux niveaux de classification des ressources existants.
Nous détaillons ci-dessous Multics et SELinux, qui sont deux exemples fondamentaux d’implémentation de MAC.
Exemple MAC 1 : Multics et les anneaux de protection

Déjà évoqué précédemment comme un précurseur des systèmes multi-utilisateurs (également dits « à temps partagé »), le projet Multics, sorti en 1969, a été porteur de multiples fonctionnalités innovantes, notamment dans sa gestion de la mémoire ou de la sécurité. Il préfigure ainsi MAC avant même la formulation de modèles tels que Bell-LaPadula (1973) et sa première définition formelle énoncée dans le « Orange Book » (1983) du Department of Defense, qui établit les normes de sécurité informatiques américaines.
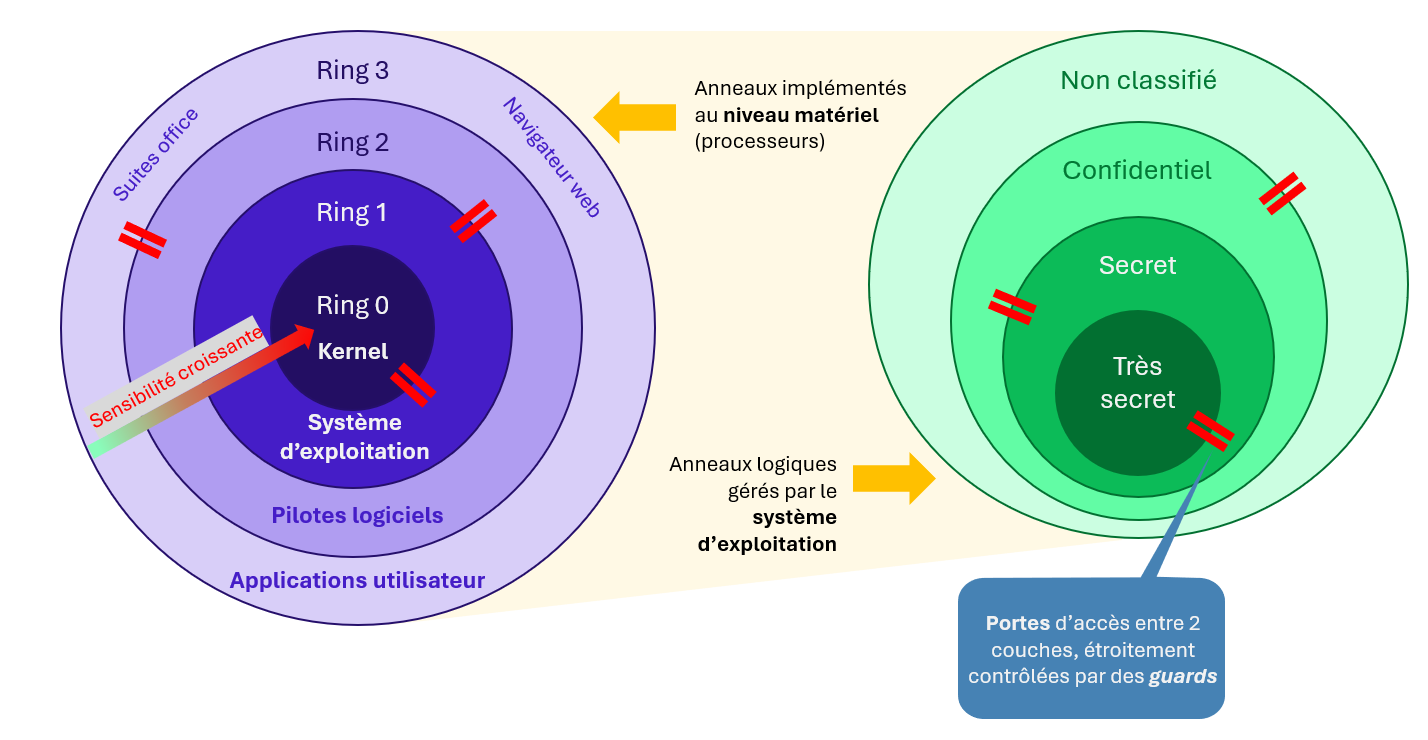
Il repose sur le concept d’anneaux de protection (rings), que Multics a créé, en témoigne son logo (image ci-dessus), et qui constituent le fondement des systèmes MLS – Multi-Level Security –, très utilisés dans les contextes de haute confidentialité. Il s’agit d’un ensemble d’anneaux concentriques représentant des niveaux de sensibilité d’autant plus élevés que l’on se rapproche du centre (ring 0) – et donc de privilèges requis pour y accéder. Des mécanismes dits guards ou gatekeepers, situés à l’interface entre deux anneaux, contrôlent étroitement la légitimité des accès dans les deux sens, qu’ils accordent ou réfutent.
En réalité, ces anneaux sont de deux types :
- Les anneaux de protection du kernel sont des anneaux physiques intégrés aux processeurs et exploités par le système d’exploitation pour garantir son intégrité contre les fautes (à l’origine de plantages de la machine) ou des modifications, intentionnelles ou non.
- Les anneaux de l’espace utilisateur sont des anneaux logiques mis en œuvre par le système d’exploitation. C’est là que l’on retrouve MAC. Par le biais de labels, chaque utilisateur et chaque ressource se retrouve rattaché à un niveau d’anneau. De là, des règles définissent les actions possibles ou non, à l’instar du modèle Bell-LaPadula qui met l’accent sur la confidentialité des données : « No read up » (un utilisateur ne peut accéder en lecture à des couches supérieures à la sienne), « No write down » (il ne peut non écrire dans des couches inférieures, évitant les fuites).
L’image ci-dessous résume le principe des anneaux de protection.
Exemple MAC 2 : SELinux, module de sécurité du noyau Linux

Initialement développé par la NSA, en 2001, SELinux a été proposé et ajouté dès 2003 aux modules de sécurité pour le noyau Linux (LSM, Linux Security Modules), et est nativement intégré aux distibutions RedHat, telles que Fedora.
C’est un autre exemple notoire d’implémentation de MAC : il permet aux administrateurs d’attribuer à chaque ressource un label security context afin de les classifier, et de définir les politiques de sécurité qui seront appliquées par le système d’exploitation. Même avec des droits privilégiés, une application verra ses droits cantonnés au domaine qui lui est nécessaire pour fonctionner (par exemple les dossiers qui ont été lui spécifiés), SELinux détectant et empêchant toute action non conforme.
SELinux apporte donc une couche de protection supplémentaire dans le cas où un utilisateur ou un processus parvient à contourner les contrôles d’accès traditionnels.
Dans la pratique, les politiques MAC se suffisent rarement à elles-mêmes mais viennent se superposer aux règles DAC existantes, dont elles pallient la flexibilité. Deux modèles avant tout fondés sur l’identité de l’utilisateur ou du processus, à partir de laquelle ils autorisent ou refusent des accès : on parle de contrôle d’accès basé sur l’identité ou IBAC (Identity-Based Access Control). Ces modèles restent limités à des contextes locaux qui résistent peu au passage à l’échelle.
Role-based Access Control (RBAC)
Formulé en 1992 par David FERRAIOLO et Richard KUHN, deux ingénieurs du NIST américain, le modèle RBAC – modèle d’accès basé sur les rôles – a été pensé pour simplifier la gestion des permissions à l’échelle d’une organisation tout en en reflétant au mieux la structure (hiérarchie, responsabilités, départements…).
Au lieu d’octroyer les droits directement à une identité comme avec IBAC, une méthode vite difficile à maintenir, on conçoit des rôles métier et les privilèges associés. L’utilisateur hérite alors des droits rattachés à son rôle au sein de l’entreprise, ce qui lui permet d’accéder aux différents applicatifs et systèmes de partage d’entreprise considérés comme nécessaires pour ses activités internes.
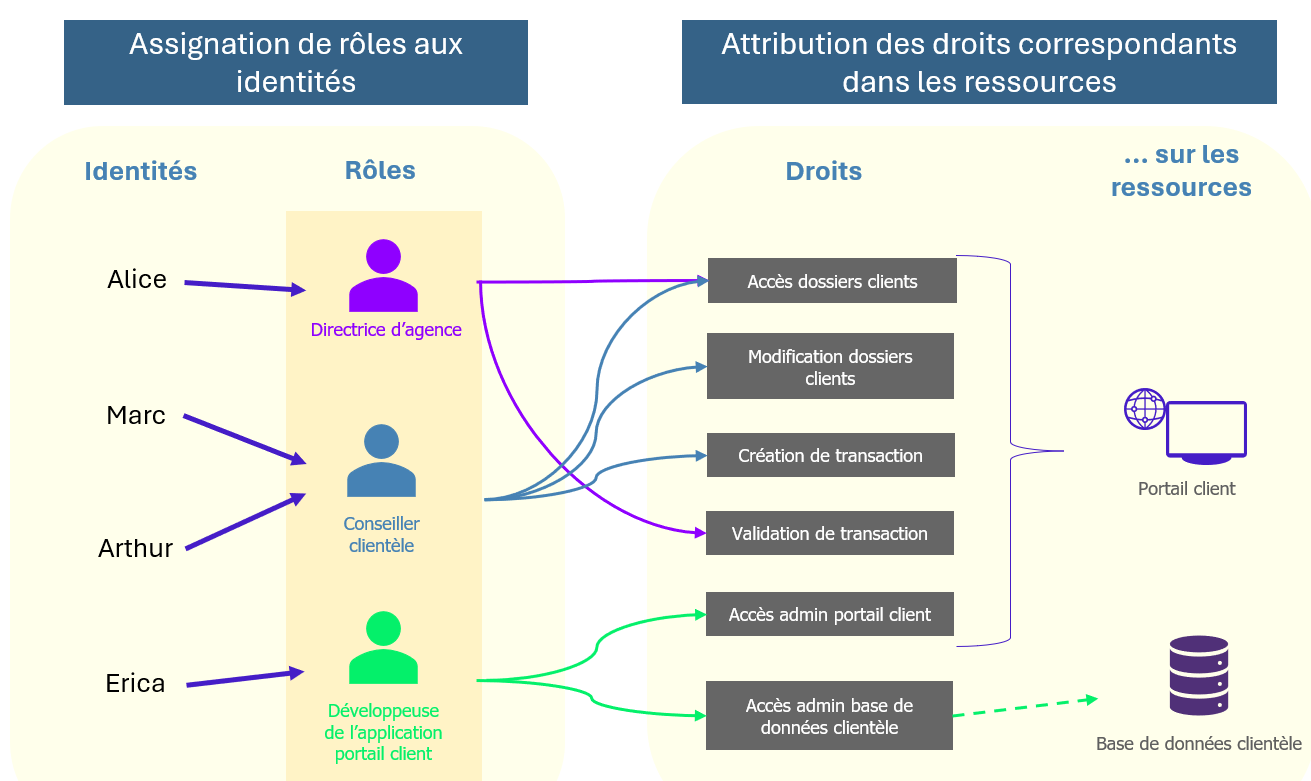
Ce premier cadre conceptuel a été complété et standardisé en 2004 avec la norme ANSI INCITS 359-2004, qui tient compte de cas pratiques et scénarios d’entreprise. Par exemple, il aborde les besoins en séparation des responsabilités (SoD, Segregation of Duty), fondamentale dans les institutions financières et bancaires, mais aussi le principe de moindre privilège, ou encore l’héritage des permissions.
Une adoption progressive et toujours plus centralisée de RBAC
Dès les années 80-90, largement adoptées par des grandes entreprises et susceptibles de contenir des informations sensibles dont on a naturellement voulu contrôler l’accès, les bases de données ont été pionnières dans la mise en œuvre du modèle RBAC. Elles illustrent son implémentation au niveau d’applications isolées, non répercutée sur les applications ou systèmes externes.
Les années 2000 voient le lancement de l’Active Directory de Microsoft, à partir du Windows 2000 Server. Cet annuaire centralisé vise la gestion de l’ensemble des ressources de l’organisation (personnes, ressources physiques, applicatifs). Bien que ce ne soit pas à proprement parler un outil RBAC, un rapprochement peut être fait. L’attribution de droits d’accès se base en effet sur des groupes de sécurité – qui peuvent être perçus comme des rôles – avec des mécanismes d’héritage de permissions et des concepts de domaines, arbres et forêts visant à représenter les structures logiques d’entreprise.
Depuis, les solutions IAM modernes, comme Okta, SailPoint IIQ ou Microsoft AzureAD, supportent RBAC pour des environnements hétérogènes, notamment les services cloud. Elles illustrent la centralisation progressive de la gestion des droits d’accès, d’abord gérée localement dans les applications, et aujourd’hui de plus en plus déléguée à des solutions IAM couvrant un spectre maximal.
RBAC attribue des droits en fonction d’un rôle métier tandis qu’IBAC est lié à une identité. La couche d’abstraction créée entre l’identité du sujet et son rôle permet de s’extraire de contextes restreints (systèmes de fichiers pour DAC, systèmes d’exploitation pour MAC) et de s’adapter (enfin !) aux besoins de contrôle d’accès d’organisations. Tous partagent néanmoins comme caractéristique une définition rigide des droits, basée sur une identité ou un rôle.
Dans des entités où les échanges sont plus dynamiques et plus fluctuants, cette abstraction au travers de rôles seuls peut s’avérer insuffisante. De nouveaux modèles ont émergé pour représenter des organisations plus complexes, prenant en compte des attributs supplémentaires, évolutifs, pour évaluer plus finement un droit d’accès à un instant t : de l’admin-time, nous entrons dans le run-time.
Les nouvelles approches d’autorisation : Run-time
La complexification des systèmes d’informations, donc des accès, ont conduit à l’approche run-time. Une approche qui répond aux besoins de flexibilité et de sécurité dynamiques des organisations. Contrairement à l’ère “admin-time”, caractérisée par des permissions statiques, l’ère “run-time” offre une gestion en temps réel au moment de la demande d’accès, fondée sur différents éléments contextuels. Cette transition vers des modèles d’autorisation plus flexibles et précis permet aux organisations de s’adapter aux changements et de mieux protéger leurs ressources contre les menaces actuelles.
Graph-Based Access Control (GBAC)
Le modèle GBAC (Graph-Based Access Control) ou GraphBAC, repose sur l’utilisation de graphes pour représenter les relations entre les utilisateurs, les rôles et les ressources au sein d’une organisation. Ces 3 types d’entités (utilisateurs, rôles, ressources) et les relations entre elles constituent le cœur de ce modèle : on peut représenter les entités par les nœuds du graphe, et les relations entre elles par les arêtes.
Les autorisations d’accès à une ressource sont déterminées en temps réel par des requêtes sur cette base de données de graphe, permettant de prendre des décisions d’accès basées sur les connexions entre les entités au moment de la demande. Un utilisateur peut ainsi obtenir l’accès à une ressource en fonction de son rôle et de ses relations avec d’autres utilisateurs ou ressources de l’organisation
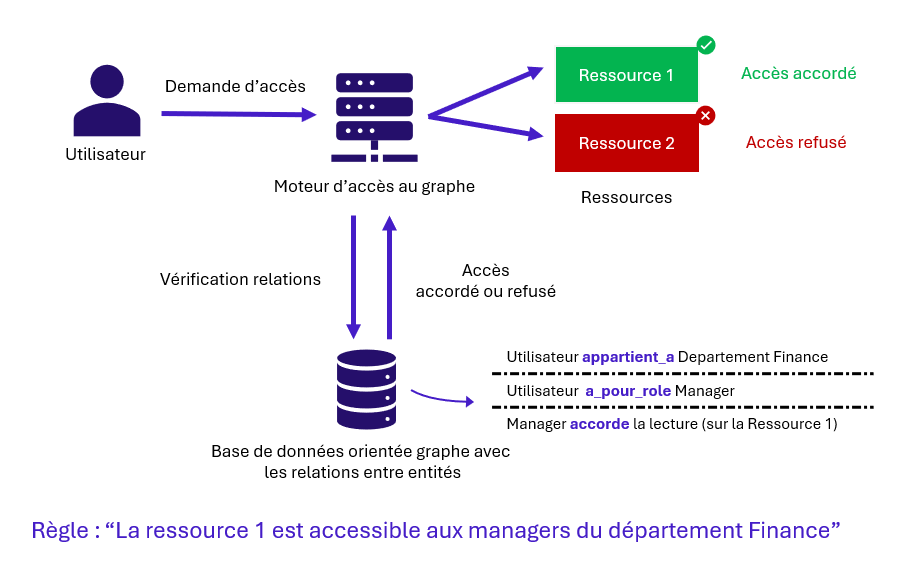
Le modèle GBAC est adapté aux environnements dynamiques de grandes organisations, où les relations entre entités évoluent constamment. En revanche, sa mise en œuvre peut s’avérer complexe et les projets de mise en place sont relativement longs donc avec des coûts élevés non négligeables. De plus, l’ajout progressif de nouvelles relations peut rendre le graphe de plus en plus difficile à gérer, compliquant ainsi les activités d’audit interne ou encore de recertification par exemple.
Attribute-Based Access Control (ABAC)
Dans le modèle d’accès ABAC (Attribute-Based Access Control), la gestion des accès à une ressource s’appuie sur la combinaison dynamique d’attributs. Ces attributs concernent aussi bien l’utilisateur demandant l’accès (rôle, groupe), la ressource demandée (type de ressource), que le contexte dans lequel s’effectue la demande (heure, type de réseau). Cette approche permet d’autoriser ou non l’accès de façon flexible et en temps réel.
Le modèle a été formalisé en 2014 dans la publication par le NIST (SP 800-162) qui fournit des informations détaillées pour sa mise en place.
4 composants sont essentiels au fonctionnement de ce modèle : les Policy Enforcement Points (PEP), les Policy Decision Points (PDP), les Policy Administration Points (PAP), et les Policy Information Points (PIP).
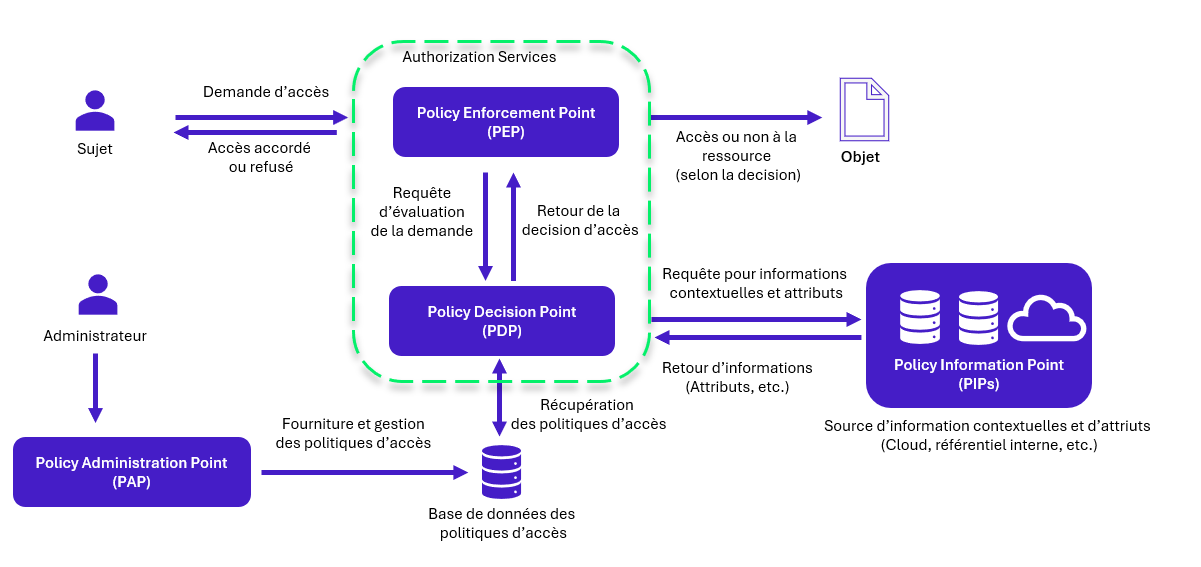
Après interception par le PEP, la demande d’accès est transmise au PDP, qui est responsable de la prise de décision en analysant les politiques d’accès qui sont gérer au niveau du PAP et souvent accessible depuis une base de données de politique d’accès. Le PIP fournit lui, au PDP des informations complémentaires sur l’utilisateur ou la ressource provenant de différentes sources permettant ainsi de rendre des décisions conformes aux règles d’accès. Pour les informations contextuelles le système d’information peut être connecter à d’autres outils ou sources (IDS, logs, capteurs) qui permettent la collecte de ces informations au moment d’une demande d’accès.
L’ABAC se présente comme un modèle particulièrement intéressant dans les environnements où les besoins d’accès sont variés et évolutifs, car il permet une gestion fine et granulaire des autorisations, notamment dans le cadre du PAM (Privileged Access Management), concernant des accès, et ressources critiques.
Cependant, ce niveau de détail et de flexibilité vient avec des défis comme la revue continue des attributs, la maintenance des politiques qui nécessitent une attention constante afin de s’assurer qu’ils répondent aux besoins de l’entreprise. Au fil du temps, le nombre croissant d’attributs et de conditions peut compliquer le maintien d’une architecture ABAC claire et fonctionnelle, surtout dans des environnements en perpétuelle transformation.
Dans les architectures ABAC actuelle, les PEPs sont généralement conçus pour fonctionner uniquement avec les PDPs du même fournisseur, avec des protocoles propriétaires, sans support pour une compatibilité entre différents fournisseurs.
Standardiser la manière dont ces différents PEP et PDP interagissent, afin d’améliorer l’interopérabilité des systèmes et de réduire la dépendance à un seul fournisseur est l’objectif du groupe de travail OpenID AuthZEN.
OpenID AuthZEN : Vers une interopérabilité améliorée
AuthZen est une initiative lancée en 2023, au travers d’un groupe de travail, par l’OpenID Foundation visant à standardiser les interactions entre les PEPs et les PDPs afin d’améliorer l’interopérabilité entre les systèmes de différents fournisseurs.
Cette initiative répond aux problèmes actuels où les services d’autorisation (PEP et PDP) sont souvent conçus pour fonctionner uniquement avec des solutions du même fournisseur, limitant leur interopérabilité.
AuthZen a été lancée pour développer un protocole standardisé qui faciliterait l’intégration et la communication entre les PEPs et les PDPs, et réduirait la dépendance aux solutions provenant d’un seul fournisseur mais aussi d’améliorer la sécurité globale des autorisations.
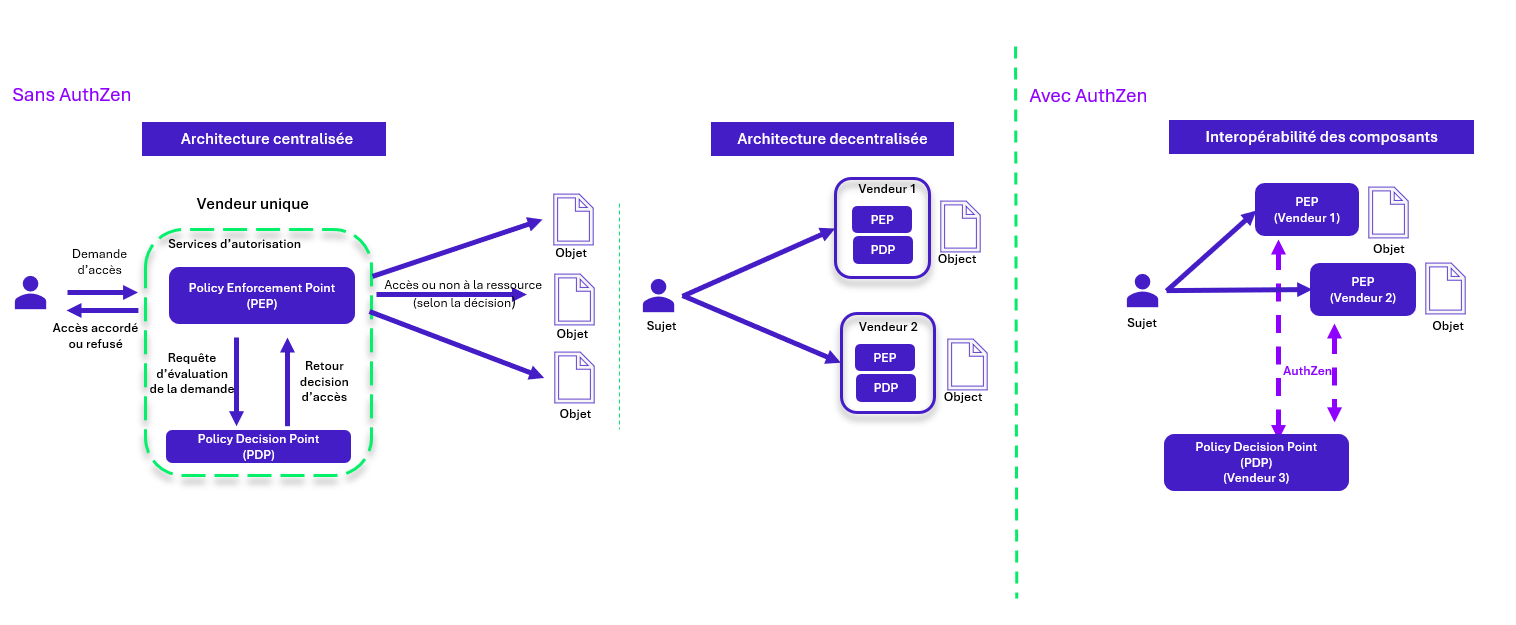
Pour rendre ces interactions plus flexibles et universelles, AuthZen s’appuie sur des architectures et des technologies existantes (OPA/Rego, XACML…), afin d’améliorer le déploiement, la scalabilité et l’interopérabilité. Les deux premières étapes de cette standardisation avec l’Open ID AuthZen sont la mise en place d’un protocole simple de type “Request/Response” et “Permit/Deny” et d’une approche de décisions multiples afin de regrouper plusieurs demandes d’autorisation en une seule et de recevoir plusieurs décisions en retour.
Ce cadre de réflexion autour de l’AuthZen comprend des acteurs du domaine de la sécurité tels que 3Edges, Axiomatic, et d’autres. Il est également ouvert aux acteurs voulant faire évoluer les systèmes d’autorisation et rendre les architectures plus sécurisées et interopérables.
Perspectives d’évolution d’autorisation : Event-time
Une nouvelle approche dans l’évolution des systèmes d’accès est l’event-time. Il se défini comme une implémentation de l’autorisation dynamique où les droits des accès sont ajustés en temps réel en réponse à des événements ou changements immédiats qui surviennent. Contrairement aux approches statiques ou basées sur des attributs, l’event-time se caractérise par une évaluation continue des droits d’accès, afin de s’assurer que tous les accès restent conformes aux politiques en place dans l’organisation.
Par exemple, lorsque l’état d’un utilisateur change (promotion, départ, mobilité, etc.), le système ajuste ou révoque automatiquement ses droits d’accès. Cette approche d’ajustement proactive basée sur des évènements est courante dans la surveillance des systèmes d’informations et la gestion des incidents de sécurité.
L’event-time repose sur des concepts clés qui sont :
- Les écouteurs (listeners), des composants du système surveillant les évènements en temps et analysant les changements importants (mobilité, promotions, départ, etc.) provenant de diverses sources notamment systèmes RH.
- Les déclencheurs (triggers), des actions en réponse à un événement identifié par un écouteur comme la révocation des droits d’accès au jour effectif de départ d’un utilisateur.
- Shared Signals (Signaux partagés), permettant à différents systèmes de partager des informations sur des événements en temps réel.
- L’évaluation continue est la vérification constante des droits d’accès pour s’assurer que chaque action ou accès reste en conformité avec les politiques.
Les frameworks et standards jouent un rôle clé dans l’implémentation de l’event-time en fournissant une structure pour la mise en œuvre les concepts dans les systèmes :
Le Shared Signals Framework (SSF) est directement lié au concept de shared signals, qui permet aux systèmes via une API de partager des informations sur les événements en temps réel pour assurer une gestion cohérente des accès. L’évaluation continue de ces informations est soutenue par le CAEP (Continuous Access Evaluation Protocol), un protocole permettant de standardiser l’écriture des changements de statut. Le RISC (Risk and Incident Sharing and Coordination) est un protocole générique qui lui permet la standardisation de la transmission et la réception des incidents de sécurité entre ces différents systèmes, renforçant ainsi la réactivité globale d’un système d’information.
L’event-time ne repose pas sur un modèle spécifique de type RBAC ou ABAC mais peut fonctionner comme une couche de gestion des accès complémentaires à ces systèmes d’accès traditionnels en les rendant plus dynamiques et alignés sur les situations en temps réel.
L’évolution des modèles d’autorisation, des approches traditionnelles aux méthodes modernes et dynamiques, reflète l’adaptation continue de l’IAM et des systèmes d’accès aux besoins croissants et changeants des organisations.
Les approches admin-time ont posé les bases de la sécurité des ressources avec des modèles tels que le DAC et le MAC. Le RBAC a introduit une gestion structurée des droits, largement adoptée dans les organisations aujourd’hui du fait de son application relativement simple.
Avec l’avènement du runtime, les décisions d’accès se sont affinées en s’appuyant sur des attributs spécifiques aux utilisateurs, aux ressources et au contexte, comme avec les modèles ABAC et GBAC. Cependant, ces modèles toujours plus sophistiqués ont conduit à l’apparition de nombreux éditeurs de solutions propriétaires, limitant l’interopérabilité des composants d’autorisation et créant une dépendance envers des technologies spécifiques. C’est ainsi qu’ont émergé des initiatives telles que le groupe de travail AuthZen œuvrant à l’élaboration de standards.
L’approche event-time apporte une réactivité en temps réel, permettant aux systèmes d’ajuster automatiquement les accès en réponse à des événements spécifiques. Le CAEP et le Shared Signals Framework facilitent cette dynamique en standardisant l’échange d’informations entre systèmes, renforçant ainsi la sécurité et la conformité.
Une vue d’ensemble de ces différentes approches et de leurs modèles associés est présentée dans la frise chronologique ci-dessous, accompagnée d’un tableau récapitulatif des différents modèles abordés.
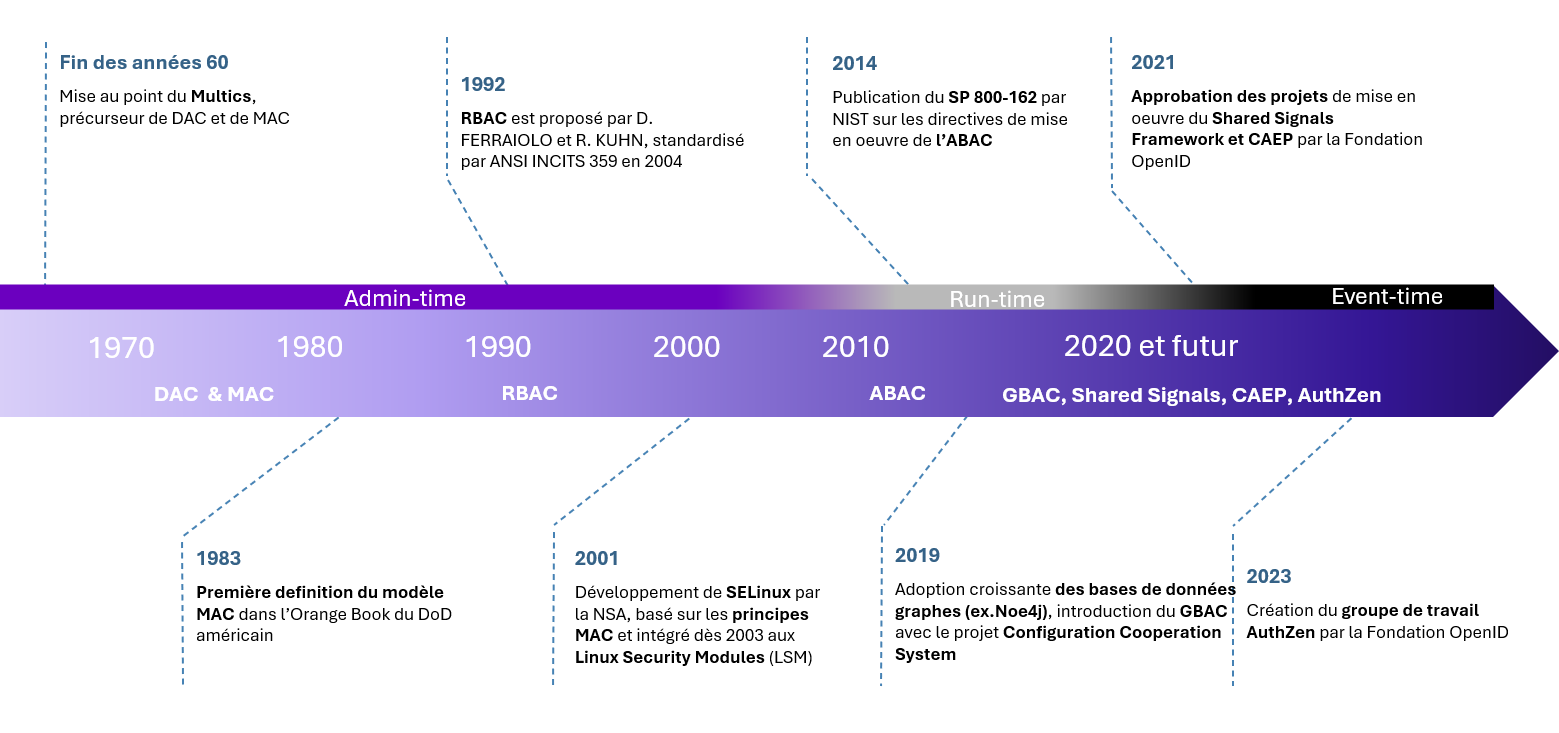
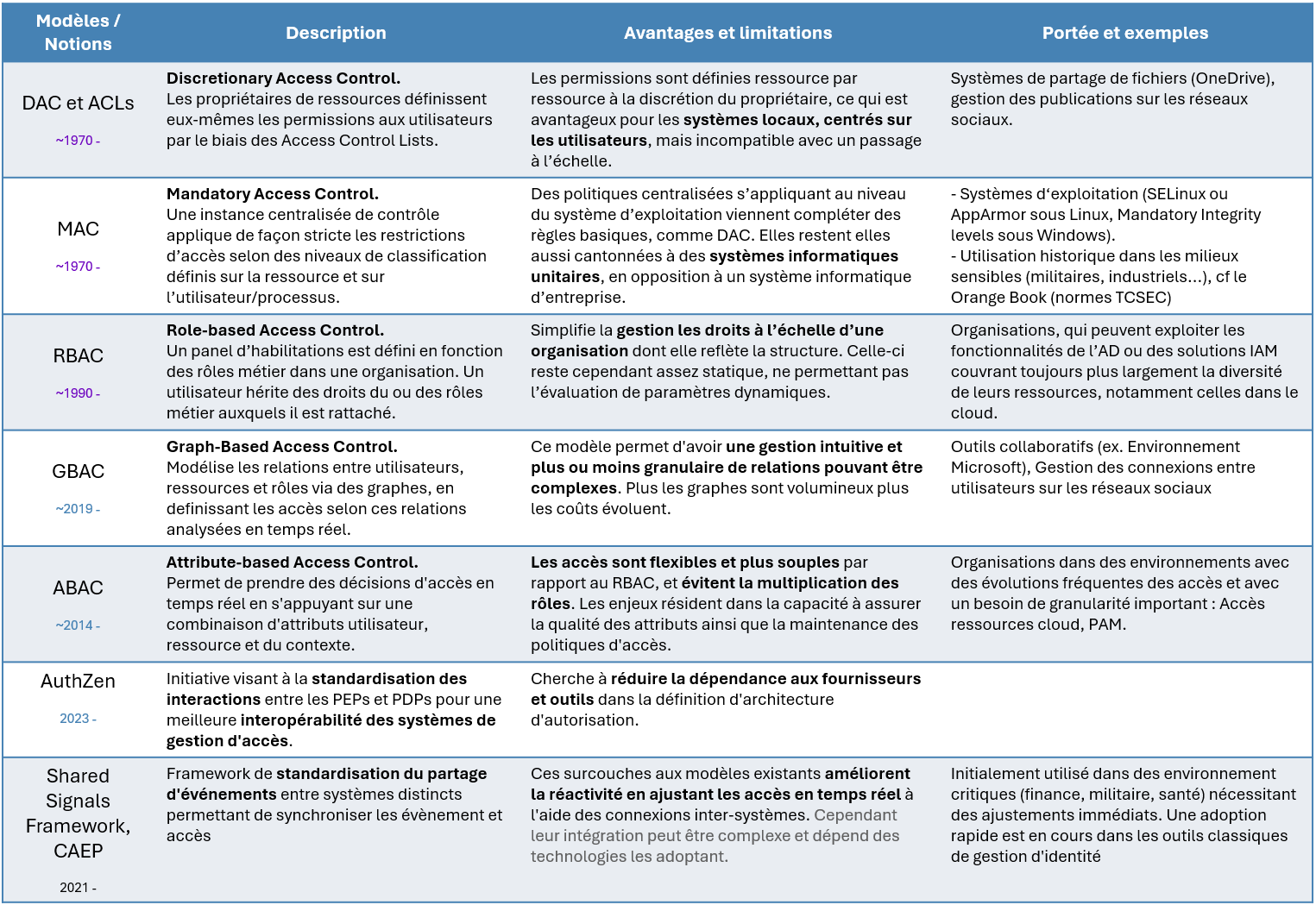 En combinant ces différentes approches, vous pouvez mettre en place une gestion des accès plus sécurisée, flexible et proactive, capable de répondre aux défis actuels et futurs liés à l’identité. Ces évolutions soulignent également l’importance d’adopter des solutions d’autorisation adaptatives et interopérables pour assurer une protection efficace des ressources tout en répondant aux exigences opérationnelles des équipes.
En combinant ces différentes approches, vous pouvez mettre en place une gestion des accès plus sécurisée, flexible et proactive, capable de répondre aux défis actuels et futurs liés à l’identité. Ces évolutions soulignent également l’importance d’adopter des solutions d’autorisation adaptatives et interopérables pour assurer une protection efficace des ressources tout en répondant aux exigences opérationnelles des équipes.
Ces évolutions posent une question essentielle sur la capacité des organisations à anticiper ces changements et intégrer ces nouvelles dynamique de la gestion de leur accès.
Que vous utilisiez encore des modèles admin-time, exploriez des options runtime, ou envisagiez de passer à une gestion event-time, il est crucial de choisir un modèle qui répond à vos enjeux spécifiques. Il est aussi très important d’anticiper les conséquences sur la gestion dans le temps de ce modèle (revue de droits, mesure de la qualité des données, revue des politiques, définition des réactions attendues, etc.).
Et vous quel type de modèle utilisez-vous ?
N’hésitez pas à nous contacter pour en savoir plus et comprendre concrètement comment les appliquer en fonction du contexte de votre organisation !
[1] Habilitation de sécurité en France, Wikipédia (wikipedia.org)


{kind=link}
{kind=link}