
Depuis le lancement de ChatGPT en novembre 2022, de nombreuses entreprises ont commencé à développer et à publier leurs propres modèles de langage de grande taille (LLM). À tel point que nous sommes actuellement dans une phase que de nombreux experts décrivent comme une « course à l’IA ». Non seulement entre les entreprises, mais aussi entre les pays et les organisations internationales. Cette course à l’IA décrit la frénésie mondiale visant à construire de meilleurs modèles, tout en élaborant des directives et des réglementations pour les encadrer. Mais qu’est-ce qu’un meilleur modèle, exactement ?
Pour répondre à cette question, des chercheurs et des ingénieurs du monde entier ont mis au point un système standardisé pour tester les LLM dans divers contextes, domaines de connaissance, et les quantifier de manière objective. Ces tests sont communément appelés des « Benchmarks », et différents benchmarks reflètent des cas d’utilisation très variés.
Cependant, pour l’utilisateur moyen, ces benchmarks seuls ne signifient pas grand-chose. Il existe un manque évident de sensibilisation pour l’utilisateur final : un résultat de 97,3 % dans le benchmark « MMLU » est difficile à comprendre et à transposer dans leurs tâches quotidiennes.
Pour éviter de telles confusions, l’article présente des facteurs qui limitent les choix d’un utilisateur en matière de LLM, les benchmarks de LLM les plus populaires et largement utilisés, leurs cas d’utilisation, et comment ils peuvent aider les utilisateurs à choisir le LLM le plus optimal pour eux.
Facteurs qui impactent le choix des LLM
Différents facteurs impactent la qualité du modèle : la date limite de connaissance, l’accès à Internet, la multimodalité, la confidentialité des données, la fenêtre contextuelle ainsi que la vitesse et la taille des paramètres. Ces facteurs doivent être bien établis avant de passer aux évaluations des benchmarks et aux comparaisons de modèles, car ils limitent les modèles que vous pouvez utiliser en premier lieu.
Date limite de connaissances et accès à Internet
Presque tous les modèles sur le marché ont une date limite de connaissance. Il s’agit de la date à laquelle la collecte de données pour la formation du modèle prend fin. Par exemple, si la date limite est septembre 2021, le modèle n’a aucun moyen de connaître les informations après cette date. Les dates limites sont généralement fixées un à deux ans avant la publication du modèle.
Cependant, pour surmonter ce problème, certains modèles tels que Copilot (GPT-4) et Gemini ont été dotés d’un accès à Internet, leur permettant de naviguer sur le web. Cela a permis à des modèles ayant une date limite de connaissances de continuer à accéder aux nouvelles et aux articles les plus récents. Cet accès permet également aux LLM de fournir des références aux utilisateurs, ce qui réduit le risque d’hallucinations et rend les réponses plus fiables.
Enfin, l’accès à Internet est une fonctionnalité ajoutée au modèle plutôt qu’une caractéristique intrinsèque du modèle lui-même. Il est donc limité aux modèles disponibles sur Internet, principalement ceux en source fermée et hébergés dans le cloud. Pour cette raison, il est important de déterminer vos besoins et de vérifier si disposer d’informations à jour est réellement essentiel pour atteindre vos objectifs.
Multimodalité
Différentes applications nécessitent des usages variés des LLM. Alors que la plupart d’entre nous les utilisent principalement pour leurs capacités de génération de texte, de nombreux LLM sont en réalité capables d’analyser des images, des voix, et de répondre avec des images également.
Cependant, tous les LLM n’ont pas cette capacité. La capacité d’analyser différentes formes d’entrée (texte, image, voix) est ce que l’on appelle la « multimodalité ». C’est un facteur important à prendre en compte, car si votre tâche nécessite l’analyse de messages vocaux ou de diagrammes d’entreprise, il est essentiel de rechercher des modèles qui sont multimodaux, tels que Claude 3 et ChatGPT.
Protection des données
L’un des risques liés à l’utilisation de la plupart des modèles actuellement disponibles sur le marché est la confidentialité et la fuite des données. Plus précisément, la confidentialité et la sécurité des données dans les LLM peuvent être divisées en deux parties :
- Confidentialité des données lors de l’entraînement et de l’ajustement : il s’agit de savoir si le modèle a été formé sur des données contenant des informations personnelles identifiables (PII) et s’il pourrait divulguer ces informations personnelles lors des échanges avec les utilisateurs. Cela dépend de l’ensemble de données utilisé pour l’entraînement du modèle et du processus d’ajustement.
- Confidentialité des données lors du réentraînement et de la mémorisation : il s’agit de savoir si le modèle utilise les conversations avec les utilisateurs pour se réentraîner, ce qui pourrait potentiellement entraîner la divulgation d’informations d’une conversation à une autre. Cependant, ce risque est limité à certains modèles en ligne. Cela dépend de la manière dont le modèle est configuré et des couches logicielles entre le modèle et l’utilisateur.
Fenêtre contextuelle
La fenêtre contextuelle fait référence au nombre de jetons d’entrée qu’un modèle peut accepter. Ainsi, une fenêtre contextuelle plus grande signifie que le modèle peut accepter un texte d’entrée plus important. Par exemple, le dernier modèle de Google, le Gemini 1.5 pro, dispose d’une fenêtre contextuelle d’un million de jetons, ce qui lui permet de lire des manuels entiers et de vous répondre sur la base des informations qu’ils contiennent.
Pour donner un contexte, une fenêtre de 1 million de jetons permet au modèle d’analyser environ 60 livres entiers simplement à partir des entrées de l’utilisateur avant de répondre à la demande de l’utilisateur.
Ainsi, il est donc évident que les modèles avec des fenêtres contextuelles plus grandes peuvent souvent être personnalisés pour répondre à des questions basées sur des documents d’entreprise spécifiques sans avoir recours à la génération augmentée par récupération (RAG), qui est la solution la plus courante pour ce problème sur le marché.
Cependant, les LLM facturent souvent les utilisateurs en fonction du nombre de jetons d’entrée utilisés et il est donc à prévoir que les frais soient plus élevés lorsqu’on utilise une fenêtre contextuelle plus grande. De plus, il n’est pas courant que les modèles prennent plus de 10 minutes avant de répondre lorsqu’ils utilisent une fenêtre contextuelle plus grande.
Vitesse et taille des paramètres
Les LLM présentent des variations techniques qui peuvent influencer la rapidité de traitement de la demande de l’utilisateur et la vitesse de génération de la réponse. La variation technique la plus importante qui affecte la vitesse des LLM est la taille des paramètres, qui fait référence au nombre de variables internes que le modèle possède. Ce nombre, généralement en milliards, reflète la sophistication du modèle, mais indique également que le modèle pourrait nécessiter plus de temps pour générer une réponse.
Toutefois, l’architecture interne du modèle a également son importance. Par exemple, certains des derniers modèles à plus de 70 milliards de paramètres sur le marché peuvent répondre en temps réel, tandis que certains modèles à 8 milliards de paramètres ont besoin de quelques minutes pour générer une réponse.
Globalement, il est important de prendre en compte le compromis entre la vitesse d’une part et la taille des paramètres (sophistication et complexité) d’autre part, bien que cela dépende aussi fortement de l’architecture interne du modèle et de l’environnement dans lequel il est utilisé (API, service cloud, ou auto-déploiement, etc.).
Néanmoins, la vitesse est un élément clé qui se situe à la frontière entre le facteur et le critère de référence puisqu’elle est mesurée et utilisée pour comparer les différents modèles STOA. Cependant, la vitesse n’est pas une forme d’évaluation pragmatique standardisée et, pour cette raison, elle n’est pas considérée comme un critère de référence.
Prochaines étapes
Après avoir examiné les facteurs, les utilisateurs peuvent maintenant limiter leur choix de LLM et utiliser les critères d’évaluation présentés dans la section suivante pour les aider à choisir le modèle le plus optimal. Cela permet à l’utilisateur de maximiser son efficacité et de ne comparer que les modèles qui sont pertinents pour lui (en termes de date limite de connaissances, de vitesse, de confidentialité des données, etc.)
Comment les benchmarks sont-ils menés ?
Les benchmarks sont des outils utilisés pour évaluer la performance des LLM dans un domaine spécifique. Ils peuvent être réalisés de différentes manières, le facteur clé étant le nombre de paires question-réponse d’exemples fournies au LLM avant qu’il ne soit invité à résoudre une question réelle.
Les benchmarks évaluent la capacité du LLM à accomplir une tâche spécifique. La plupart des benchmarks posent une question au LLM et comparent sa réponse avec une réponse correcte de référence. Si la réponse correspond, le score du LLM augmente. À la fin, les benchmarks fournissent un score de précision (Acc/Accuracy), qui est un pourcentage du nombre de questions auxquelles le LLM a répondu correctement.
Cependant, en fonction de la méthode d’évaluation, le LLM peut obtenir un certain contexte sur le benchmark, le type de questions ou d’autres éléments. Cela se fait par le biais de tests à répétition ou d’exemples multiples.
Tests à répétition
Les benchmarks sont réalisés de trois manières distinctes.
- Zéro répétition
- Une répétition
- Multi-répétition (souvent des multiples de 2 ou de 5)
Le terme « répétition » se réfère au nombre de fois qu’une question exemple est donnée au LLM avant son évaluation.
La raison pour laquelle nous avons différents types de tests (zéro répétition, une répétition, multi-répétitions) est que certains LLM surpassent d’autres en termes de mémoire à court terme et d’utilisation du contexte. Par exemple, le LLM1 pourrait avoir été formé avec plus de données et donc surpasser le LLM2 dans les tests zéro répétition. Cependant, la technologie sous-jacente du LLM2 lui permet de bénéficier d’une capacité de raisonnement et de contextualisation supérieure, qui ne serait mesurée que par des évaluations d’une répétition ou de plusieurs répétitions.

Figure 1 : illustration de 3-shots vs 0-shot prompting
Pour cette raison, chaque fois qu’un LLM est évalué, des réglages à plusieurs répétitions sont utilisés pour garantir une compréhension complète du modèle et de ses capacités. Par exemple, si vous êtes intéressé par la recherche d’un modèle qui contextualise bien et est capable de raisonner logiquement à travers de nouveaux et divers problèmes, envisagez d’examiner comment la performance du modèle s’améliore à mesure que le nombre de répétitions augmente. Si un modèle montre une amélioration significative, cela signifie qu’il possède une forte capacité à raisonner et à apprendre des exemples précédents.
Principaux benchmarks et facteurs de différenciation
De nombreux benchmarks évaluent souvent les mêmes aspects. Il est donc important, lors de l’examen des benchmarks, de comprendre ce qu’ils évaluent, comment ils le font et quelles sont les implications de ces évaluations.
Compréhension du Langage Multitâche Massif (MMLU)
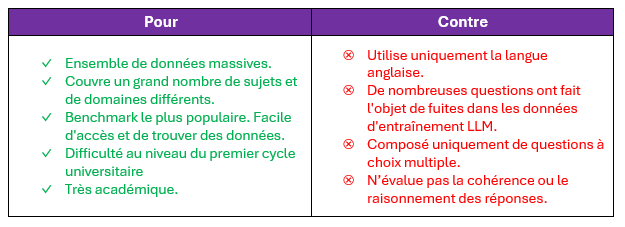

Figure 2 : exemple d’un questionnaire à choix multiple
Le MMLU est l’un des benchmarks les plus largement utilisés. Il s’agit d’un ensemble de données au format de questions à choix multiple couvrant 57 sujets uniques à un niveau de licence. Ces sujets incluent les humanités, les sciences sociales, les STIM (Sciences, Technologie, Ingénierie et Mathématique) et plus encore. Pour cette raison, le MMLU est considéré comme le benchmark le plus complet pour tester les connaissances générales d’un LLM dans tous les domaines. De plus, il est également utilisé pour identifier les lacunes dans les données d’entraînement du LLM, car il n’est pas rare qu’un LLM soit exceptionnellement bon dans un sujet et moins performant dans un autre.
Cependant, le MMLU ne contient que des questions en anglais. Ainsi, un excellent résultat au MMLU ne se traduit pas nécessairement par de bonnes performances lorsqu’il s’agit de répondre à des questions de culture générale en français ou en espagnol. De plus, le MMLU est exclusivement basé sur des questions à choix multiple, ce qui signifie que le LLM est testé uniquement sur sa capacité à choisir la bonne réponse. Cela ne signifie pas nécessairement que le LLM est compétent pour générer des réponses cohérentes, bien structurées et sans hallucinations lorsqu’il est confronté à des questions ouvertes.
En règle générale, un score MMLU moyen élevé pour l’ensemble des 57 champs indique que le modèle a été entraîné sur une grande quantité de données contenant des informations sur de nombreux sujets différents. Ainsi, un modèle qui obtient de bons résultats en MMLU est un modèle qui peut être utilisé efficacement (éventuellement avec un peu d’ingénierie) pour répondre aux FAQ, aux questions d’examen et à d’autres questions courantes de la vie quotidienne.
HellaSwag (HS)
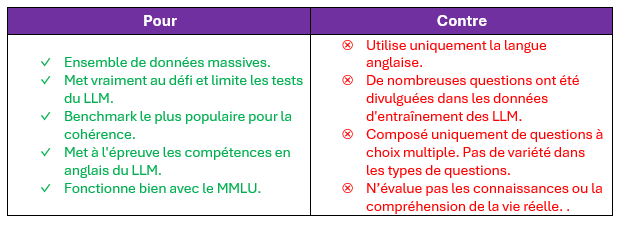

Figure 3 : exemple d’une question HellaSwag
HellaSwag est un acronyme pour « Harder Endings, Longer contexts, and Low-shot Activities for Situations with Adversarial Generations ». Il s’agit d’un autre benchmark massif (plus de 10 000 questions) axé sur l’anglais et basé sur des questions à choix multiple. Cependant, contrairement au MMLU, le HS n’évalue pas les connaissances factuelles ou spécifiques à un domaine. Au lieu de cela, le HS se concentre sur la cohérence et le raisonnement des LLM.
Les questions comme celle ci-dessus mettent le LLM au défi en lui demandant de choisir la suite de la phrase qui a le plus de sens humain. Grammaticalement, ces phrases sont toutes valables, mais seule l’une d’entre elles respecte le bon sens.
La raison pour laquelle ce critère a été choisi est qu’il fonctionne en tandem avec le MMLU. Alors que le MMLU évalue les connaissances factuelles, le HS évalue si le LLM serait capable d’utiliser ces connaissances factuelles pour vous fournir des réponses cohérentes et sensées.
Une bonne façon de visualiser l’utilisation de MMLU et HS est d’imaginer le monde dans lequel nous vivons aujourd’hui. Nous avons des ingénieurs et des développeurs qui possèdent une grande compréhension et des connaissances techniques, mais qui n’ont aucun moyen de les communiquer correctement en raison des barrières linguistiques et sociales. Pour cette raison, nous avons des consultants et des gestionnaires qui ne possèdent peut-être pas des connaissances aussi approfondies, mais qui ont la capacité d’organiser et de communiquer les connaissances des ingénieurs de manière cohérente et concise.
Dans ce cas, le MMLU représente l’ingénieur, tandis que le HS joue le rôle du consultant. L’un évalue les connaissances, tandis que l’autre évalue la communication.
HumanEval (HE)

Alors que le MMLU et le HS évaluent la capacité du LLM à raisonner et à répondre avec précision, HumanEval est le benchmark le plus populaire pour évaluer uniquement la capacité du LLM à générer du code utilisable pour 164 scénarios différents. Contrairement aux deux précédents, HumanEval n’est pas basé sur des questions à choix multiple et permet au LLM de générer sa propre réponse. Cependant, toutes les réponses ne sont pas acceptées par le benchmark. Chaque fois qu’un LLM est invité à coder une solution pour un scénario, HumanEval teste le code du LLM avec une variété de tests et de cas limites. Si l’un de ces tests échoue, le LLM échoue également.
De plus, HumanEval exige que le code généré par le LLM soit optimisé en termes de temps et d’espace. Ainsi, si un LLM propose un certain algorithme alors qu’un algorithme plus optimal est disponible, il perd des points. Pour cette raison, HumanEval teste également la capacité du LLM à comprendre précisément la question et à y répondre de manière exacte.
HumanEval est un benchmark important, même pour les cas d’utilisation non techniques, car il reflète de manière indirecte la sophistication et la qualité générales d’un LLM. Pour la plupart des modèles, le public cible est composé de développeurs et des passionnés de technologie. Pour cette raison, il existe une forte corrélation positive entre des scores élevés à HumanEval et des scores élevés dans de nombreux autres benchmarks, ce qui indique que le modèle est de haute qualité. Cependant, il est important de garder à l’esprit qu’il s’agit simplement d’une corrélation, et non d’une causalité, ce qui signifie que les choses pourraient évoluer à mesure que les modèles commencent à cibler de nouveaux utilisateurs.
Chatbot Arena

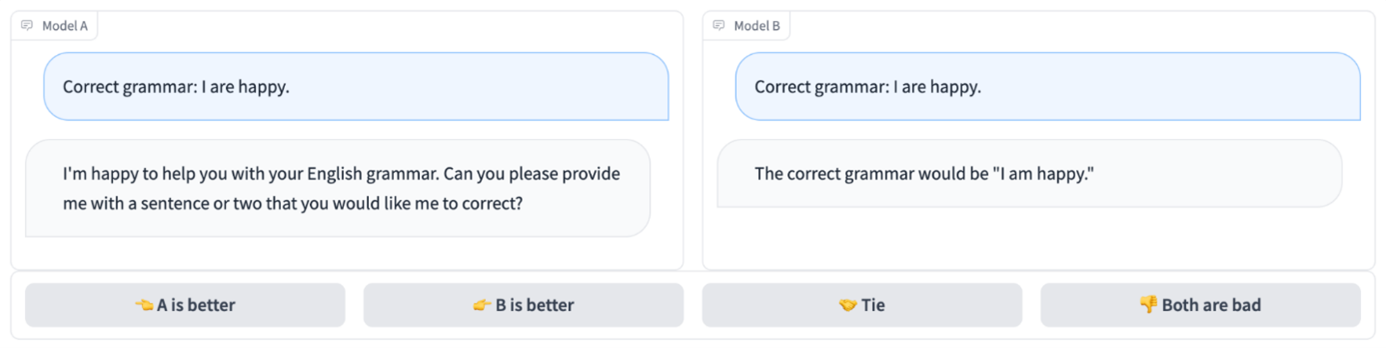
Figure 4 : exemple de l’interface Chatbot Arena
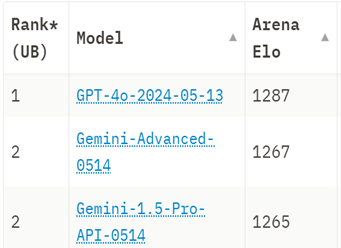
Figure 5 : classement Chatbot Arena, juillet 2024
Contrairement aux trois benchmarks précédents, Chatbot Arena n’est pas un benchmark objectif, mais un classement subjectif de tous les LLM disponibles sur le marché. Chatbot Arena recueille les votes des utilisateurs et détermine quel LLM offre la meilleure expérience utilisateur globale, y compris la capacité à maintenir des dialogues complexes, comprendre les demandes des utilisateurs et d’autres facteurs de satisfaction client. La nature subjective de Chatbot Arena en fait le meilleur benchmark pour évaluer l’expérience utilisateur finale. Cependant, cette subjectivité le rend également non reproductible et difficile à quantifier réellement.
Les classements actuels placent GPT-4o d’OpenAI en tête de liste avec une marge importante par rapport à la deuxième place. Ce classement est très pertinent puisqu’il est basé sur l’opinion de 1,3 million de votes d’utilisateurs.Cependant, ces votants proviennent principalement d’un milieu technologique, et le classement pourrait donc être biaisé en faveur des modèles ayant de meilleures compétences en codage.
Les classements sont établis sur la base du système ELO, un système à somme nulle où les modèles gagnent des points ELO en produisant des réponses meilleures que celles de leur modèle concurrent, tandis que ce dernier perd des points ELO.
Évaluation globale des benchmarks
Les benchmarks peuvent présenter des biais et des limites internes. Ils peuvent être utilisés conjointement pour mieux représenter les capacités du modèle. Les modèles plus récents bénéficient d’avantages en raison de leur architecture, de la taille de leurs données d’entraînement et de la divulgation des questions de benchmark.
Les trois benchmarks mentionnés plus un (Chatbot Arena) sont les plus populaires et les plus utilisés dans la recherche pour comparer les LLM. La combinaison de ces benchmarks (MMLU, HellaSwag, HumanEval et Chatbot Arena) évalue de nombreux aspects du LLM, de sa compréhension factuelle et de sa cohérence, à ses compétences en codage et à l’expérience utilisateur. C’est pourquoi, ces quatre benchmarks sont largement utilisés dans de nombreux classements en ligne, car ils reflètent véritablement la nature du LLM.
Cependant, il est important de considérer que les modèles LLM les plus récents bénéficient d’un avantage considérable pour deux raisons principales :
- Ils sont construits sur des architectures plus robustes, disposent de meilleures technologies sous-jacentes et ont accès à davantage de données pour l’entraînement en raison de dates limites plus récentes et d’une capacité matérielle plus grande.
- De nombreuses questions des benchmarks mentionnés précédemment ont été divulguées dans les données d’entraînement des modèles.
Néanmoins, il existe de nombreux autres benchmarks disponibles sur Internet qui évaluent différents aspects des LLM et sont souvent utilisés ensemble pour offrir une vue complète de la performance du modèle.
Facteurs, Benchmarks et comment choisir votre LLM
En utilisant les facteurs et benchmarks mentionnés, vous pouvez comparer efficacement les LLM de manière quantifiable et objective, ce qui vous aidera à prendre une décision éclairée et à choisir le modèle le plus optimal pour vos besoins professionnels et vos tâches.
De plus, chacun des benchmarks mentionnés possède des points forts et des faiblesses qui les rendent uniques et efficaces dans différents aspects. Chez Wavestone, nous reconnaissons cependant l’importance de la diversification pour minimiser les risques. C’est pourquoi nous avons développé une liste de vérification permettant aux utilisateurs de prendre des décisions plus éclairées lors du choix d’un ensemble de benchmarks à suivre et de leur utilisation pour comparer les derniers modèles. La liste de vérification couvre une grande variété de domaines, de benchmarks et de facteurs, offrant à l’utilisateur final un contrôle plus granulaire sur son choix de benchmarks.
Cet outil, qui est également un suivi des priorités, permet aux utilisateurs d’attribuer différents poids aux benchmarks afin de refléter avec précision leurs besoins professionnels et la nature des tâches. Par exemple, un consultant pourrait privilégier la multi-modalité pour l’analyse de diagrammes et de graphiques par rapport aux compétences mathématiques, et ainsi attribuer un poids plus élevé à la multi-modalité
Réflexions finales
Dans le paysage en évolution rapide des LLM, comprendre les nuances entre les différents modèles et leurs capacités est crucial. Avant de considérer un LLM, plusieurs facteurs doivent être pris en compte, tels que la date limite de connaissance, la confidentialité des données, la vitesse, la taille des paramètres, la fenêtre contextuelle et la multimodalité. Une fois ces facteurs examinés, les utilisateurs peuvent consulter différents benchmarks pour prendre une décision plus éclairée. Ceux abordés dans cet article, à savoir MMLU, HellaSwag, HumanEval et Chatbot Arena, offrent un système robuste pour évaluer quantitativement ces modèles dans divers domaines.
En conclusion, la course à l’IA ne consiste pas seulement à développer de meilleurs modèles, mais aussi à tirer parti de ces modèles de manière efficace. Le choix du LLM le plus optimal n’est pas un sprint mais un marathon, nécessitant un apprentissage continu, une adaptation et une prise de décision stratégique à travers le benchmarking et les tests. Alors que nous continuons à explorer le potentiel des LLM, rappelons-nous que la véritable mesure du succès ne réside pas dans la sophistication de la technologie, mais dans sa capacité à ajouter de la valeur à notre travail et à nos vies.
Remerciements
Nous remercions Awwab Kamel Hamam pour son travail dans la rédaction de cet article.
Lectures complémentaires et références
[1] D. Hendrycks et al., “Measuring Massive Multitask Language Understanding.” arXiv, 2020. doi: 10.48550/ARXIV.2009.03300. Disponible sur : https://arxiv.org/abs/2009.03300
[2] D. Hendrycks et al., “Aligning AI With Shared Human Values.” arXiv, 2020. doi: 10.48550/ARXIV.2008.02275. Disponible sur : https://arxiv.org/abs/2008.02275
[3] M. Chen et al., “Evaluating Large Language Models Trained on Code.” arXiv, 2021. doi: 10.48550/ARXIV.2107.03374. Disponible sur : https://arxiv.org/abs/2107.03374
[4] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi, “HellaSwag: Can a Machine Really Finish Your Sentence?” arXiv, 2019. doi: 10.48550/ARXIV.1905.07830. Disponible sur : https://arxiv.org/abs/1905.07830
[5] W.-L. Chiang et al., “Chatbot Arena: An Open Platform for Evaluating LLM by Human Preference.” arXiv, 2024. doi: 10.48550/ARXIV.2403.04132. Disponible sur : https://arxiv.org/abs/2403.04132

