
En novembre 2022, l’agent conversationnel ChatGPT développé par OpenAI était rendu accessible au grand public. Depuis, dire que ce nouvel outil a suscité l’intérêt serait un euphémisme. Deux mois après son lancement, l’outil était l’application qui a connu la plus forte croissance de l’histoire avec près de 100 millions d’utilisateurs actifs par mois (record depuis battu par Threads).
A l’heure où les utilisateurs ont adopté ce produit en masse, cela pose aujourd’hui plusieurs questions fondamentales de cybersécurité.
Les entreprises doivent-elles laisser leurs employés – spécifiquement les équipes de développement – continuer à utiliser cet outil sans aucune restriction ? Doivent-elles suspendre son usage le temps que les équipes de sécurité se saisissent de la question ? Ou alors faut-il simplement le bannir ?
Entre autres, certaines entreprises comme J.P. Morgan ou Verizon ont fait le choix d’en interdire l’usage. La société Apple avait initialement décidé d’autoriser l’outil pour ses employés avant de revenir sur sa décision et l’interdire. Amazon et Microsoft ont simplement demandé à leurs employés de faire attention aux informations partagées avec OpenAI.
L’approche la plus restrictive qui consiste à bloquer la plateforme permet d’éviter toutes questions de cybersécurité mais posent d’autres interrogations, notamment sur la performance et la productivité des équipes, et plus largement de la compétitivité des entreprises sur des marchés changeant rapidement.
Aujourd’hui, la question du blocage IT de l’intelligence artificielle reste d’actualité. Nous proposons de donner quelques éléments de réponses à cette question pour une catégorie de population particulièrement concernée par la question : les équipes de développement.
ChatGPT, collecte d’informations personnelles et RGPD
Le produit d’OpenAI est libre d’accès et d’utilisation sous condition de créer un compte utilisateur. C’est une tendance connue : si un outil en ligne est gratuit, c’est que la source de revenu n’est pas issue de l’accès à l’outil. Pour le cas particulier de ChatGPT, les informations provenant de l’historique des millions d’utilisateurs permettent d’améliorer la plateforme et la qualité du modèle de langage. ChatGPT est un service en preview : toute données entrée par l’utilisateur est susceptible d’être lue par un humain de façon à améliorer les services.
Actuellement ChatGPT ne semble pas conforme au RGPD et à la loi informatique et liberté mais aucune décision de justice n’a été rendue. Les conditions générales ne font actuellement pas mention du droit à la limitation du traitement, droit à la portabilité des données ou encore du droit d’opposition. La société OpenAI basée aux Etats-Unis ne fait pas mention du RGPD mais rappelle que ChatGPT est conforme aux « CALIFORNIA PRIVACY RIGHTS ». En revanche, cette régulation ne s’applique que pour les résidents Californiens et ne s’applique donc pas au-delà des Etats-Unis d’Amérique. OpenAI ne propose pas non plus de solution pour permettre aux individus de vérifier si l’éditeur stocke leurs données personnelles, ni d’en réclamer leur suppression.
Enfin, lorsque nous nous attardons sur les mentions légales de ChatGPT, nous pouvons comprendre que :
- OpenAI collecte les adresses IP de l’utilisateur, son type de navigateur Web, ainsi que les données et ses interactions avec le site web. Par exemple, cela inclut le type de contenu généré avec l’IA, les cas d’usages et les fonctions utilisées.
- OpenAI collecte aussi des informations sur l’activité de navigation des utilisateurs sur le web. Elle se réserve d’ailleurs le droit de partager ces informations personnelles avec des tiers, mais sans préciser lesquelles.
Tout ceci étant fait dans le but entre autres d’améliorer les services existants ou de développer de nouvelles fonctionnalités.
Pour revenir aux populations de développeurs, on observe aujourd’hui que la majorité du code s’écrit de manière collaborative en utilisant des outils Git. Ainsi, il n’est pas rare pour un développeur de devoir comprendre un morceau de code qu’il n’a pas écrit lui-même. Plutôt que de demander au rédacteur en question ce qui peut prendre plusieurs minutes (au mieux), un développeur peut être tenté de se tourner vers ChatGPT afin d’obtenir une réponse de manière instantanée. La réponse peut parfois même être plus détaillée que celle que l’auteur du code pourrait fournir.
|
En conséquence, il semble plus que nécessaire d’anonymiser les éléments que l’on partage avec le ChatBot. Sans quoi, certains individus pourraient avoir accès à des données confidentielles de manière illégitime. Ainsi, si un développeur souhaite comprendre les fonctionnalités d’un morceau de code qu’il ne connaît pas avec l’aide de ChatGPT, il convient de :
|
Les attaques classiques sur l’IA restent valables
Plus de la moitié des entreprises se disent aujourd’hui prêtes et décidées à investir et à s’équiper d’outils fonctionnant grâce à l’intelligence artificielle. Par conséquent, il va être de plus en plus intéressant pour les attaquants d’exploiter ce type de technologie. D’autant que la notion cybersécurité est trop souvent ignorée lorsqu’on parle d’intelligence artificielle.
L’IA d’OpenAI n’est pas immunisée contre les attaques par empoisonnement. Même si l’IA est entraînée sur une base de connaissance conséquente, il est peu probable que l’ensemble de cette connaissance ait fait l’objet d’une revue manuelle. Si nous revenons au sujet de la génération de code, il est probable que selon certains entrants spécifiques l’IA propose du code contenant une porte dérobée (backdoor). Même si ce cas de figure n’a pas été constaté, il n’est pas possible de prouver que celui-ci ne se produira pas selon un entrant particulier de l’utilisateur.
Nous pouvons également supposer que l’outil n’a été entrainé qu’à partir de sources web relativement sûres. Le LLM (Large Language Model) sur lequel repose ChatGPT : GPT3 pourrait être susceptible à « l’auto-empoisonnement ». En effet, à mesure que GPT3 est utilisée par des millions d’utilisateurs, il est très probable que du texte généré par GPT3 se retrouve au sein de contenus internet de confiance. L’entraînement de GPT4 pourrait donc théoriquement contenir du texte généré par GPT3. Ainsi, l’IA pourrait réaliser son apprentissage à partir de connaissances qui aurait été générées par des versions antérieures du même modèle LLM. Il sera intéressant de voir comment OpenAI contourne le problème d’empoisonnement à mesure que les évolutions sont apportées au modèle.
L’empoisonnement est une des techniques permettant d’ajouter des backdoors dans le code généré par l’IA, mais ceci n’est pas l’unique vecteur d’attaque. Il est également possible qu’une compromission des systèmes OpenAI permettant de modifier la configuration de ChatGPT afin de suggérer du code contenant des portes dérobées sous certaines conditions. Un attaquant sournois pourrait aller jusqu’à filtrer sur l’identité du compte utilisateur de ChatGPT (par exemple un compte finissant par @grandclientduCAC40.com) pour décider ou non de générer du code contenant des backdoors et autres vulnérabilités. Il est donc nécessaire de rester vigilant du niveau de sécurité d’OpenAI de façon à éviter toute compromission par rebond.
Chat GPT et la génération de code
La génération de code via ChatGPT est une des fonctionnalités qui peuvent faire gagner le plus de temps à un développeur au quotidien. Un développeur peut par exemple demander de rédiger un squelette de code pour une fonction puis compléter / corriger les erreurs de l’IA au besoin. Le risque principal induit par cette pratique est ici l’insertion de code malveillant au sein d’une application.
Cependant, le risque existait bien avant ChatGPT. Un développeur malveillant pourrait très bien obfusquer son code et insérer une backdoor au sein d’une application de manière volontaire. En revanche l’introduction de l’IA apporte une nouvelle dimension au risque dès lors qu’un utilisateur bien intentionné pourrait introduire une backdoor malgré lui. Ceci est à mettre en perspective de la maturité de l’entreprise vis-à-vis de sa chaine CI/CD. La réalisation de scans SAST, DAST et d’audits divers avant la mise en production permet entre-autres de réduire le risque.
Nous avons constaté que la génération de code via ChatGPT ne suit pas par défaut les meilleures pratiques de sécurité. L’outil peut générer du code utilisant des fonctions non sécurisées comme scanf en langage C. Nous avons proposé à l’outil la requête suivante : « Est-ce que tu peux écrire une fonction en langage C qui permet de créer une liste de nombres entiers grâce à des inputs d’un utilisateur ? ».
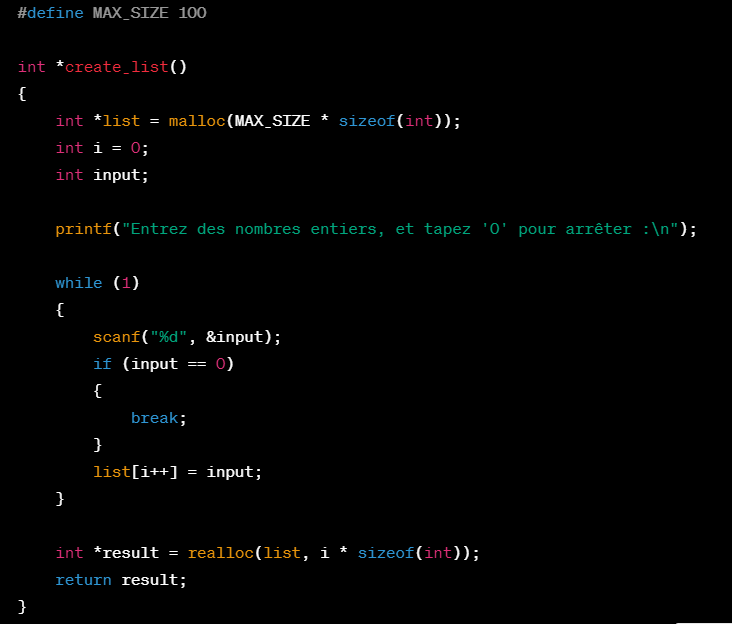
Code généré par ChatGPT suite à l’entrée utilisateur décrite ci-dessus
En analysant le code généré par ChatGPT on remarque – entre autres – trois vulnérabilités importantes :
(1) Pour débuter, l’utilisation de la fonction scanf permet à l’utilisateur de rentrer n’importe quelle longueur d’input (int overflow…). Il n’y a pas de validation de l’input de l’utilisateur, ce qui reste aujourd’hui un type de vulnérabilité phare remonté par l’OWASP TOP10.
(2) Additionnellement, la fonction est sensible au buffer overflow : au-delà du 100ème input, la liste list ne contient plus de place pour stocker des données additionnelles ce qui peut soit terminer l’exécution par une erreur ou alors permettre à un utilisateur malveillant d’écrire des données dans une zone de la mémoire qui ne serait pas autorisée afin de prendre le contrôle de l’exécution du programme.
(3) Pour finir, ChatGPT alloue de la mémoire à la liste via la fonction malloc mais oublie de libérer la mémoire une fois que la liste n’est plus utilisée ce qui pourrait entrainer des soucis de fuite de mémoire (memory leak).
Chat GPT ne génère donc pas de code de manière sécurisée par défaut contrairement à un développeur expérimenté. L’outil propose du code contenant des vulnérabilités critiques. Si l’utilisateur se révèle assez sensibilisé à la cybersécurité, il est possible de demander à ChatGPT d’identifier les vulnérabilités contenues dans son propre code :

ChatGPT est capable de détecter les vulnérabilités sur le code ayant été généré par ses soins.
Pour résumer, la génération de code via ChatGPT n’introduit pas de nouveaux risques mais accentue la probabilité qu’une vulnérabilité se retrouve en production. Les recommandations peuvent varier en fonction de la maturité et de la confiance qu’a l’entreprise dans la sécurisation du code livré en production. Une chaine CI/CD et des processus robustes avec des scans de sécurité automatiques (SAST, DAST, FOSS…) a de grande chance de détecter les vulnérabilités les plus critiques.
Ainsi, ChatGPT n’est pas la seule ressource accessible en ligne par les utilisateurs pouvant permettre l’exfiltration de données (Google Drive, WeTransfer…). Le risque de fuite de données plane déjà sur toute organisation n’ayant pas implémenté une allow-list sur le proxy internet de ses utilisateurs. Le facteur différenciant dans le cas de ChatGPT est que l’utilisateur ne se rend pas nécessairement compte du caractère public des données postées sur la plateforme. Les bénéfices et le gain de temps apportés par l’outil sont bien souvent trop tentant pour l’utilisateur lui faisant oublier les bonnes pratiques. En ce sens ChatGPT n’apporte pas de nouveaux risques mais accentue les probabilités de fuite de données.
Une organisation dispose donc de deux options afin d’empêcher la fuite de donnée via ChatGPT : (1) former et sensibiliser ses utilisateurs puis leur faire confiance, ou (2) bloquer l’outil.
Pour les population de développeurs, ici encore la génération de code via ChatGPT n’introduit pas de nouveaux risques mais accentue la probabilité qu’une vulnérabilité se retrouve en production. Il revient à l’entreprise d’évaluer les capacités de sa chaine CI/CD et ses processus de mise en production afin d’évaluer les risques résiduels notamment concernant les faux-négatifs des outils de sécurité intégrés (SAST, DAST…).
Afin de prendre une décision éclairée, une analyse de risques reste un bon outil pour prendre une décision quant au blocage éventuel de l’accès à ChatGPT. Les aspects suivants doivent être considérés : niveau de sensibilisation des utilisateurs, sensibilité de la donnée manipulée, paradigme de filtrage internet, maturité de la chaine CI/CD… Ces analyses sont bien sûr à mettre en perspective avec les potentiels gains en productivité des équipes.

