
Retour d’expérience sur AWS et Azure
Les erreurs de configuration dans les environnements Cloud sont encore source d’incidents majeurs et ce n’est pas près de s’arrêter. L’actualité regorge d’exemples : fuite de 1 milliard de donnés de citoyens lié à une fuite de clé, campagne de phishing utilisant une clés AWS de Kaspersky, mauvaise configuration d’une base de données NoSQL, 3TB de données sensibles des aéroports…
L’objectif de cet article est de voir comment anticiper un tel scénario en mettant en œuvre une Tour de contrôle (ou outil de supervision continue de la configuration des ressources Cloud).
Avant toute chose, un peu de théorie sur les logs
Les logs cloud peuvent être répartis en 3 catégories :
- System logs: Ils sont générés par les OS et les applications hébergées en mode IaaS/CaaS. Les enjeux ne sont pas différents d’un SI classique on premise, seule l’architecture de collecte de logs peut être à adapter.
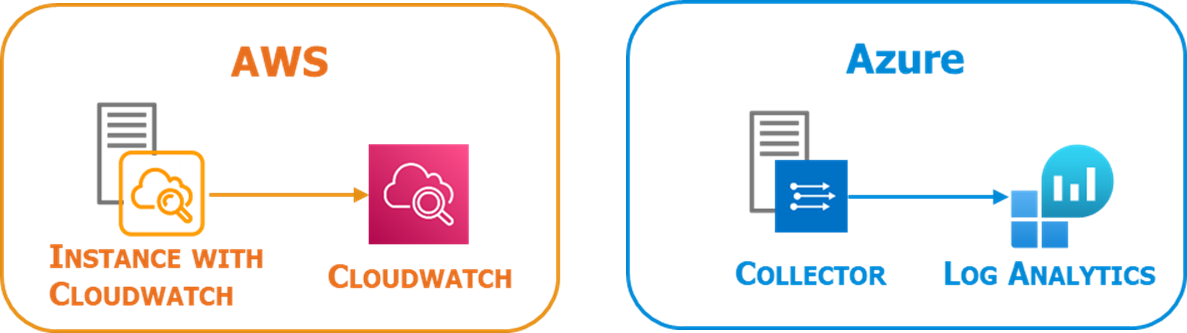
- Security infrastructure admin logs : Il s’agit des logs des appliances de sécurité mais également des services PaaS de sécurité utilisés par le client et des logs des flux réseaux. Pour les appliances, là encore rien de bien nouveau, il s’agit du même composant déjà utilisé et bien connu. En revanche pour les services PaaS de sécurité et les logs réseaux, il est nécessaire de mettre en œuvre une intégration spécifique et d’adapter les scénarios de détection.
- Cloud Infra API logs : Lors de chaque call API pour créer, modifier ou supprimer une ressource, le Cloud Service Provider va générer un log.

Ces logs sont accessibles dans des services managés dédiés tels que AWS CloudTrail, AWS config ou Azure activity log
Le délai de mise à disposition va dépendre du SLA du CSP, les logs sont généralement disponibles de quelques minutes à 15 minutes après réalisation de l’opération.
Exploiter ces logs va permettre de passer d’une conformité manuelle et statique à une conformité automatique et continue :

Quelles options techniques pour construire une Tour de contrôle ?
Trois grandes options s’offrent à un client qui souhaiterait mettre en œuvre une tour de contrôle :
- Natif intégré (built-in)
- Natif personnalisé (custom)
- Cloud Security Posture Management (CSPM)
Natif intégré (built-in)
Dans ce premier cas, les outils activés par défaut par le Cloud Service Provider, parfois gratuitement, utilisant des alertes prédéfinies pour évaluer la conformité de vos environnements et délivrer un score de sécurité sont utilisés.
Par exemple Trusted Advisor sur AWS ou Microsoft Defender for Cloud sur Azure.
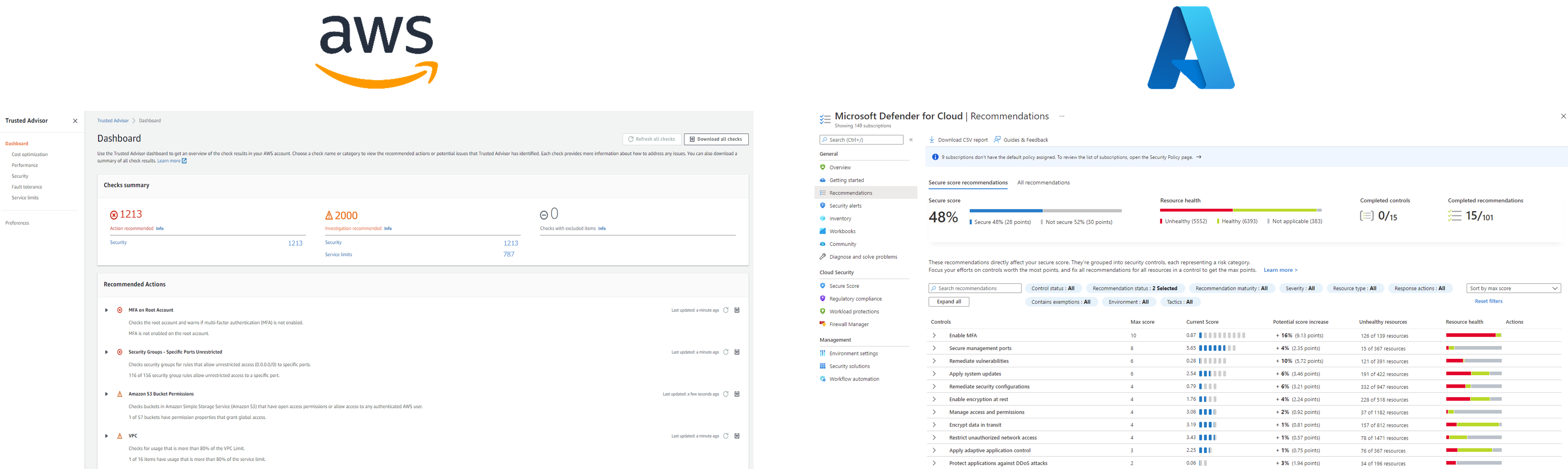
Ces solutions natives et non-personnalisées permettent d’initier une tour de contrôle, mais elles sont cependant rapidement limitées : il s’agit d’une réponse générique à des problématiques spécifiques.
Natif personnalisés (custom)
Les fournisseurs Cloud mettent à disposition de nombreux services permettant aux clients de construire un outil de vérification de la conformité de leur infrastructure : les outils du CSP disponibles sont personnalisés pour créer des alertes de conformité spécifiques et des tableaux de bord/KPIs personnalisés.
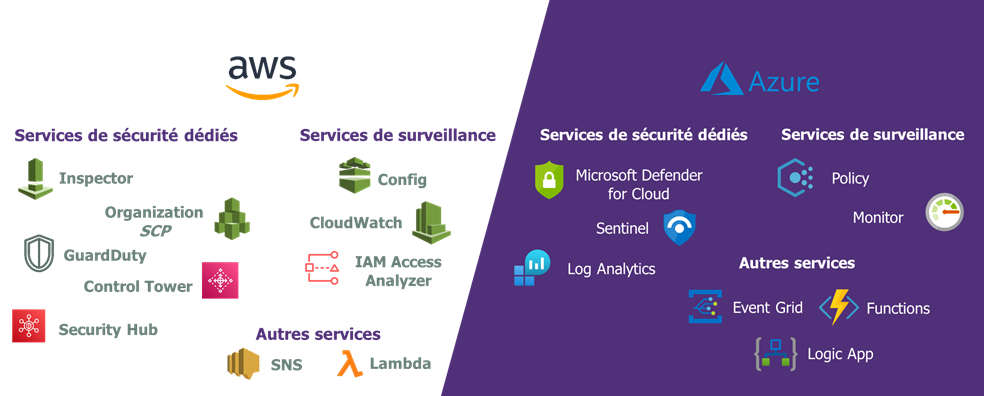
Dans cette option, il est nécessaire de prévoir un projet de 10 à 40 jours hommes pour mettre en œuvre l’infrastructure de supervision, définir les 1ères alertes et construire les tableaux de bords.
L’usage de plusieurs tenants, organisations ou Cloud nécessitera de définir une architecture spécifique car il n’existe pas de solution clé en main.
CSPM : Cloud Security Posture Management
Wavestone voit un marché en plein essor. Marketsandmarkets estime que le marché devrait plus que doubler entre 2022 et 2027 en passant de 4,2 milliards de $ à 8,6 milliards de $.
Les CSPM supportent nativement de nombreux Cloud providers et mettent à disposition de leurs clients de nombreux tableaux de bord basés sur les grands référentiels du marché. Le client pourra également définir facilement ses propres standards, politiques et alertes.
Le déploiement de ce type d’outil est très simple, nécessitant que quelques jours hommes.
Les coûts récurrents pourront cependant être significatifs : généralement 3 à 5% de la facture Cloud en plus des services du Cloud à activer (similaire à l’option des services natifs et personnalisés).
La vitesse de détection sera également un peu moins rapide car le SLA du CSPM s’additionne à celui de génération des logs de CSP, généralement un délai de détection de 20 minutes à 1 heure.
Que doit superviser ma Tour de Contrôle ?
Le problème majeur que rencontrent les clients lors de la mise en œuvre d’un CSPM avec l’activation d’alertes proposées est la génération de dizaines voire de centaines de milliers d’alertes de criticité haute à traiter. Les équipes ne savent pas par quoi commencer et c’est bien souvent le découragement qui l’emporte. Il faut faire attention à ne pas surcharger les équipes de sécurité !
Pour la mise en œuvre d’une tour de contrôle sur un SI Cloud de production, nous recommandons de déployer les contrôles de sécurité par vague de 10 à 15 à la fois. Pour cela, il faut prioriser les sujets les plus importants. Ci-dessous un exemple de priorisation :

Malheureusement, à toute règle ses exceptions ! Elles sont principalement liées à l’existant Cloud, à des architectures spécifiques ou des contraintes techniques. Il est donc primordial dès la conception de prévoir ce cas de figure et la gouvernance associée :
- Validation : par le RSSI local et/ou le RSSI global
- Expiration
- Revue : décentralisée (localement ou lors d’audits globaux annuels) ou centralisée (par un suivi continu global)
L’utilisation de tag pour les ressources Cloud est la solution la plus simple à ce jour pour le faire – attention toutefois, certaines ressources peuvent ne pas être compatibles comme les services IAM.
Quel que soit le modèle choisi, les sujets à traiter restent principalement les mêmes :
- Garantir l’utilisation et l’application légitime des exceptions
- Définir des indicateurs spécifiques sur des exceptions pour les sujets à risques du Top Management
- Mettre en place des campagnes régulières de suivi des exceptions
- Alerter et traiter lorsqu’une exception expire
Comment mettre en œuvre un processus de remédiation efficace ?
La mise en œuvre d’une tour de contrôle va générer de nombreuses alertes, qu’il va falloir corriger. Trois options sont possibles : bloquer, remédier automatique ou manuellement

Refus (Mode deny)
Pourquoi remédier alors qu’il suffit de bloquer préventivement les ressources non-conformes ?
Avec des Azure Policy ou des AWS SCP, il est possible nativement de bloquer certaines configurations et ainsi éviter la génération de nouvelles alertes.
Pour les cas d’usage non couverts, il est possible de mettre en place des vérifications des templates de déploiement dans les chaines CI/CD (cela nécessite néanmoins une forte maturité).
Déployer un mécanisme de refus – ou deny – sur des environnements existants est rarement implémenté car le risque de générer des mécontentements des équipes de développement est trop fort :
- Les ressources existantes non conformes ne peuvent plus être modifiées
- Cela va générer une charge supplémentaire aux équipes de développement car les habitudes doivent être changées
- …
Remédiation automatique
Ici, il s’agit de corriger directement et automatiquement les configurations déviantes : attention aux effets de bord !
Pour se faire, il est possible d’utiliser les services natifs des cloud provider (Azure policy ou AWS SSM Manager) ou pour des cas non supportés de développer des fonctions (AWS Lambda, Azure Function ou Azure LogicApps).
Manuel
Il s’agit malheureusement de la solution la plus rencontrée mais aussi la plus coûteuse en ressources humaines. Les configurations déviantes sont remédiées à la main par les équipes.
Pour garantir le succès d’une remédiation manuelle, il est nécessaire d’avoir un appui fort du top management pour assurer l’adhésion et la motivation des équipes.
 La mise en œuvre d’un tableau de bord de type Cloud OWSAP mettant en lumière les priorités du moment est une bonne solution, permettant de responsabiliser chacun sur son périmètre. Chaque sujet mentionné ci-contre pouvant avoir un ou plusieurs indicateurs.
La mise en œuvre d’un tableau de bord de type Cloud OWSAP mettant en lumière les priorités du moment est une bonne solution, permettant de responsabiliser chacun sur son périmètre. Chaque sujet mentionné ci-contre pouvant avoir un ou plusieurs indicateurs.
Avoir l’appui du management n’est cependant pas suffisant, il est nécessaire de connaitre le responsable de la ressource pour lui demander de faire les modifications. Dans un grand groupe international ce n’est pas chose aisée. Notre recommandation est de nommer à minima un security officer par compte/souscription qui devra avoir la connaissance fine des applications et des responsables des ressources.
En parallèle, il est nécessaire de mettre en œuvre un programme de formation et de sensibilisation efficace. Si l’on veut minimiser le nombre d’alertes et éviter de remplir plus vite la baignoire qu’elle se vide, les équipes de développement doivent connaitre et maitriser parfaitement les exigences sécurité à respecter dans le Cloud.
Pour commencer le processus de remédiation, notre conseil est de démarrer de manière centralisée avec une équipe compétente et bien dimensionnée en charge de la mise en œuvre de la tour de contrôle, mais également en charge de mobiliser et former des relais locaux, permettant à terme aux équipes locales de suivre et gérer de façon autonome la conformité sur leur périmètre.
Alerte de conformité ou alerte de sécurité ?
La majorité des entreprises considère la supervision de la conformité de leurs ressources Cloud comme n’étant pas une responsabilité des équipes SOC. Mais la frontière n’est pas si simple à définir, d’autant plus au vu du nombre d’incidents de sécurité dans le Cloud provenant d’erreurs de configuration : exposition publique d’une ressource de stockage contenant des données critiques, MFA non-configuré sur un compte admin ou encore RDP ou SSH exposés sur internet.
La génération d’une alerte de sécurité au SOC permet de tirer parti des processus et outillages déjà en place, pour un traitement 24h sur 24, 7 jours sur 7 même si les ressources SOC ne sont pas expertes Cloud.
Et finalement, cela sera une bonne occasion de rapprocher les sécurités Cloud et les équipes SOC pour améliorer les supervisions sécurité en l’adaptant à la réalité du cloud. Ce sujet pourra faire l’objet d’un article dédié.

