
S’il y a 10 ans, construire son SOC revenait à se demander quels scénarios superviser, quelles sources de logs collecter et quel SIEM choisir, les évolutions récentes du SI proposent de nouveaux défis : comment mettre en place la supervision dans un environnement partiellement on-premise et/ou multicloud ? En effet, en 2021, avoir un SI hébergé chez plusieurs fournisseurs IaaS est plus proche de la règle que de l’exception ; et si AWS reste l’acteur le plus rencontré, les offres d’Azure et de GCP intéressent de plus en plus d’équipes IT.
Comment construire sa stratégie de détection ? Où positionner le ou les SIEM ? Comment centraliser les logs, les alertes ? D’ailleurs, faut-il des logs ou des alertes ? Et comment tirer parti des solutions managées proposées par les fournisseurs cloud ?
Dans cet article, nous discuterons de bonnes pratiques : utilisation d’une stratégie de détection bottom-up, optimisation via le choix des services natifs cloud les plus pertinents, simplification de l’architecture de collecte ; toujours basées sur des retours d’expérience de construction de stratégies de supervision multicloud.
(Re)penser sa stratégie de détection pour le multicloud
La première question que devrait se poser l’équipe en charge du SOC est celle de la stratégie de détection. Autrement dit, quels scénarios va-t-on superviser ?
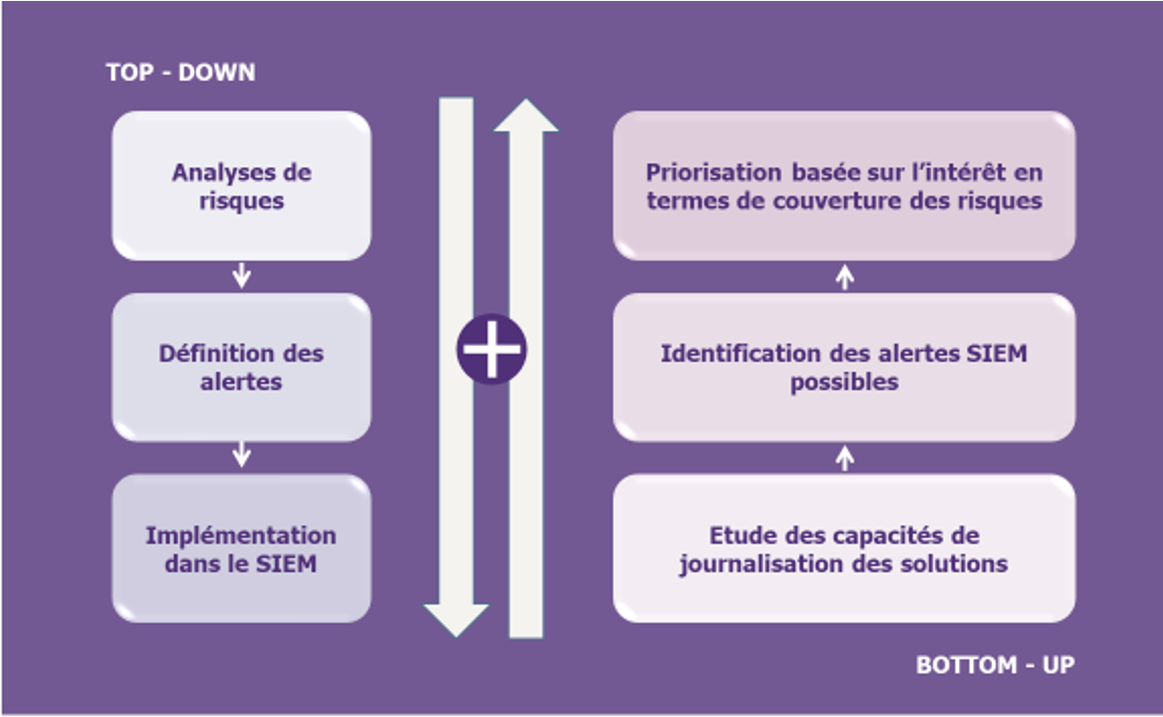
Un bon réflexe cyber consiste à utiliser une approche dite « top-down » : partir d’une analyse de risques pour identifier les alertes à prioriser, les formaliser puis les traduire techniquement dans le SIEM. En pratique, trois facteurs démontrent que cette approche est insuffisante :
- Peu d’équipes disposent d’analyses de risques qui soient suffisamment exhaustives, à jour et pragmatiques pour permettre une déclinaison des scénarios de menaces en scénarios supervisables, en particulier pour des périmètres complexes comme le cloud public,
- Rien ne garantit que les scénarios obtenus par cette méthode puissent concrètement être mis sous supervision, que les limites soient liées aux solutions déployées ou à la nécessité pour les équipes SOC de disposer de connaissances métier.
- Cette approche définit quelques chemins d’attaques selon la criticité des actifs, mais ne couvre pas tous les chemins d’attaques qu’un attaquant pourrait emprunter.
De ce fait, une stratégie de détection multicloud efficace sera obtenue en complétant l’approche par les risques par une approche « bottom-up » : en partant des capacités de journalisation des solutions dont on dispose pour identifier les alertes que le SIEM devra remonter, pour enfin prioriser en se basant sur leur intérêt en termes de couverture des risques. Partir de l’existant garantit le pragmatisme et l’efficacité de la démarche.
Chez Wavestone, nous sommes de plus en plus sollicités par des clients souhaitant être accompagnés sur cette nouvelle approche. Le périmètre concerne les principales solutions utilisées en multicloud : Microsoft 365 (SaaS) et les solutions managées des offres IaaS des 3 principaux acteurs du marché : Amazon Web Services, Microsoft Azure et Google Cloud Platform.
Mettre en place la supervision de l’infrastructure Microsoft 365
Sur le papier, l’équipe SOC a toutes les clés en main pour monitorer son infrastructure cloud :
- Des logs bruts pour les services d’Office 365 (Teams, SharePoint Online, Exchange Online, etc.)
- Des logs bruts, rapports de sécurité, alertes et Identity Secure Score pour Azure AD
- Des logs bruts, alertes, Microsoft Secure Score et recommandations Azure pour les outils de sécurité comme ATP, AAD Identity Protection, Intune, AIP, etc.
En pratique, naviguer entre les logs et tous les outils mis à disposition (et leurs consoles) peut vite devenir un casse-tête. Et si nous entendons régulièrement qu’il y a trop de logs ou d’interfaces d’administration à maîtriser, sur le terrain les difficultés sont accentuées :
- Par les faibles capacités de personnalisation des outils natifs proposés,
- Par le manque de scénarios disponibles avec la licence achetée,
- Par la durée de rétention de 90 jours des logs,
- Par le manque général de compétences Office 365 ou AzureAD dans les équipes SOC.
Pour éviter de se perdre, nous conseillons de simplifier le terrain de jeu autant que possible. Les bonnes pratiques consistent à penser alertes, et pas collecte de logs, puis à centraliser leur gestion dans le SIEM en utilisant des connecteurs comme ceux de Security Graph API. A titre d’exemple, il est possible d’arriver à un modèle comme celui donné ci-dessous :
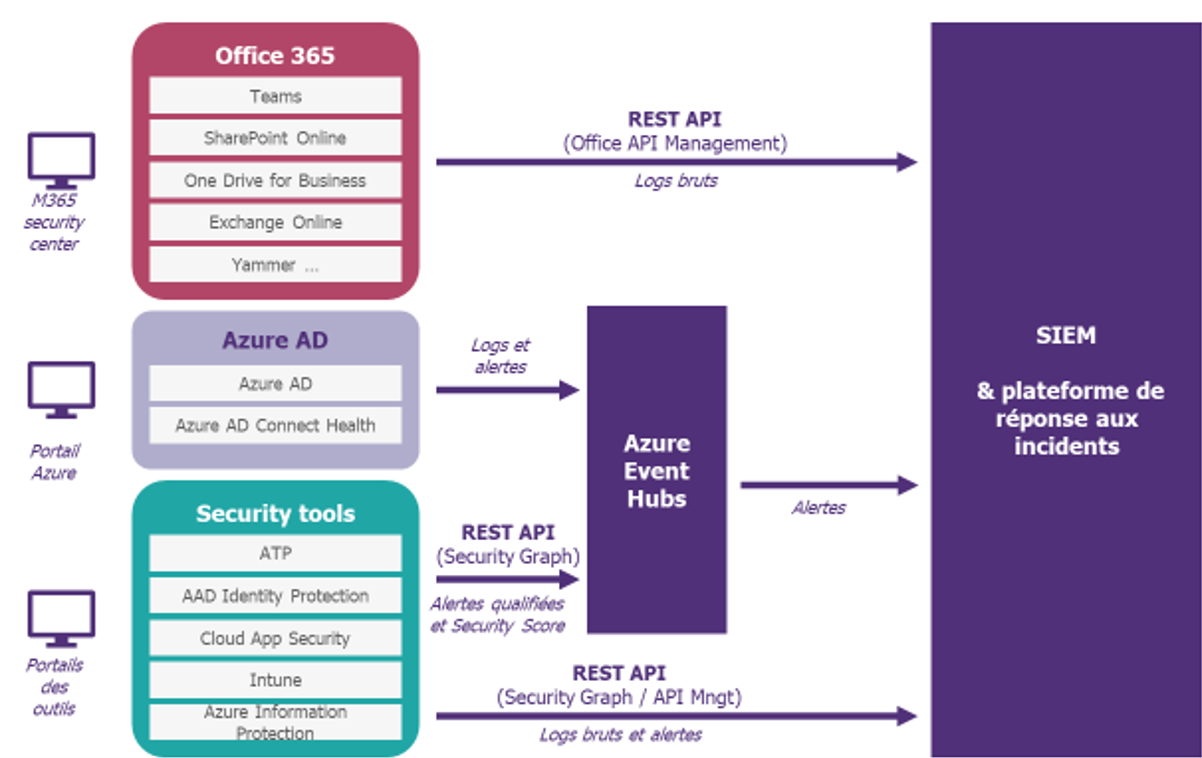
Une fois l’architecture identifiée, configurer une durée de rétention de logs adaptée aux besoins (au sein d’Azure ou à l’extérieur) et entreprendre l’adaptation des processus SOC aux spécificités de M365 selon les choix réalisés lors de l’étape précédente.
Mettre en place la supervision des autres cloud en IaaS
Afin de dessiner l’architecture de collecte sur ces clouds, il convient de distinguer les différents types de logs mis à disposition par les CSP.
Logs système
Le cas des logs système générés par les VM et les flux réseau peut être traité en premier ; il est possible de les collecter de la même manière qu’on-premise, avec des agents syslog, par exemple. Les infrastructures des CSP mettent à disposition des briques comme Log Analytics chez Azure pour faciliter la remontée.
Logs d’administration de l’infrastructure
On peut aussi envisager la supervision des opérations d’administration des composants « sensibles » de l’infrastructure (VPN, FW, scanner de vulnérabilités, etc.) comme on le ferait on-premise. En effet, la plupart de ces solutions disposent de leur pendant IaaS chez les fournisseurs cloud : elles s’obtiennent via la Marketplace et disposent de console d’administration web ou s’interfacent directement à la console de management du CSP (c’est par exemple le cas de l’appliance du scanner Qualys).
Logs des appels d’API
Enfin, les appels d’API réalisés par les processus/comptes sur l’infrastructure cloud et par les opérations d’administration génèrent des logs qui sont facilement récupérables via les services managés suivants :
- CloudTrail chez AWS
- Activity Log & Monitor chez Azure
- Audit Logging chez GCP
Pour éviter de se perdre, retenons la leçon suivante : « Utilisons et abusons des services natifs du cloud ». En effet, qui de mieux placé que le fournisseur pour proposer des services adaptés et intégrés au mieux à l’environnement ? En pratique, nous constatons qu’implémenter la gestion des logs et des alertes cloud dans un SIEM on-premise coûte cher (même en cherchant à limiter les coûts de stockage dans la solution de supervision) et est chronophage.
L’utilisation du cloud implique de passer à la philosophie du cloud : adoptons ses codes et domptons ses services et outils. L’occasion de renforcer les synergies entre les équipes cloud et le SOC !
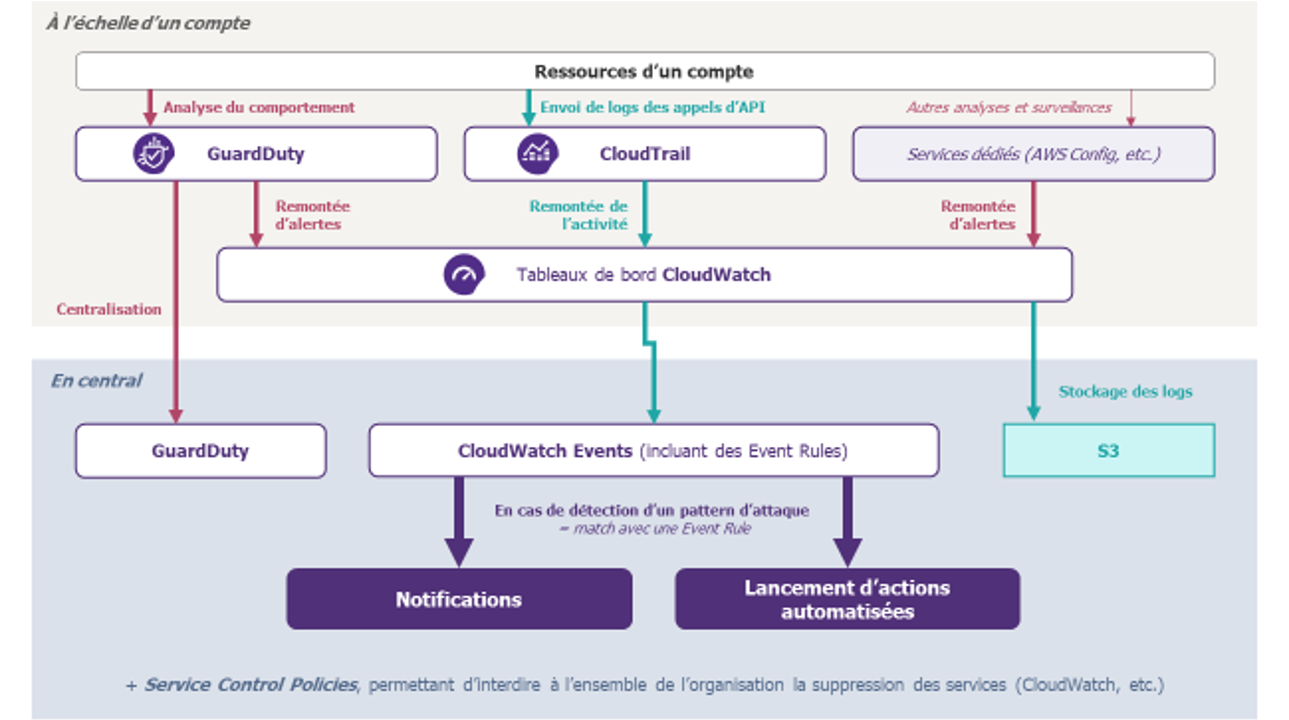
En synthèse, un exemple d’architecture de monitoring sur AWS est proposé ci-dessous. Il présente plusieurs façons de réaliser la supervision, en s’appuyant sur des services natifs pour les logs et pour les alertes (NB : tous les flux vers S3 et d’autres services n’ont pas été représentés pour des raisons de lisibilité).
Définir l’architecture de centralisation des alertes multicloud
C’est l’une des questions qui nous est la plus posée : quelle architecture SIEM faut-il envisager en multicloud ? Si chaque contexte est différent, parce que chaque infrastructure IT dispose de legacy et d’un historique qui lui est propre, la présence d’autant de ressources et d’outils doit amener une équipe SOC à considérer l’adoption d’un SIEM dans le cloud central (comme Azure Sentinel, Splunk SaaS, etc. ; AWS et Chronicle de Google ne proposant pas à date de solution équivalente).
Pour aider les équipes SOC à choisir le scénario adapté, nos recommandations sont les suivantes :
- Privilégier le scénario à un seul SIEM central
- Limiter autant que possible le nombre de consoles de supervision cloud
- Remonter au maximum des alertes déjà préanalysées par les services natifs mis à disposition étudiés précédemment
- Tirer profit des synergies éventuelles entre produits du même fournisseur : Azure Sentinel pour monitorer l’infrastructure Microsoft 365 par exemple
- Tirer profit des nombreux connecteurs mis à disposition par les fournisseurs de SIEM cloud
- Etudier les impacts de chaque scénario sur l’organisation du SOC (taille des équipes, compétences technologiques, etc.) et les coûts associés (développements nécessaires, volumétrie et coûts d’ingestion, etc.)
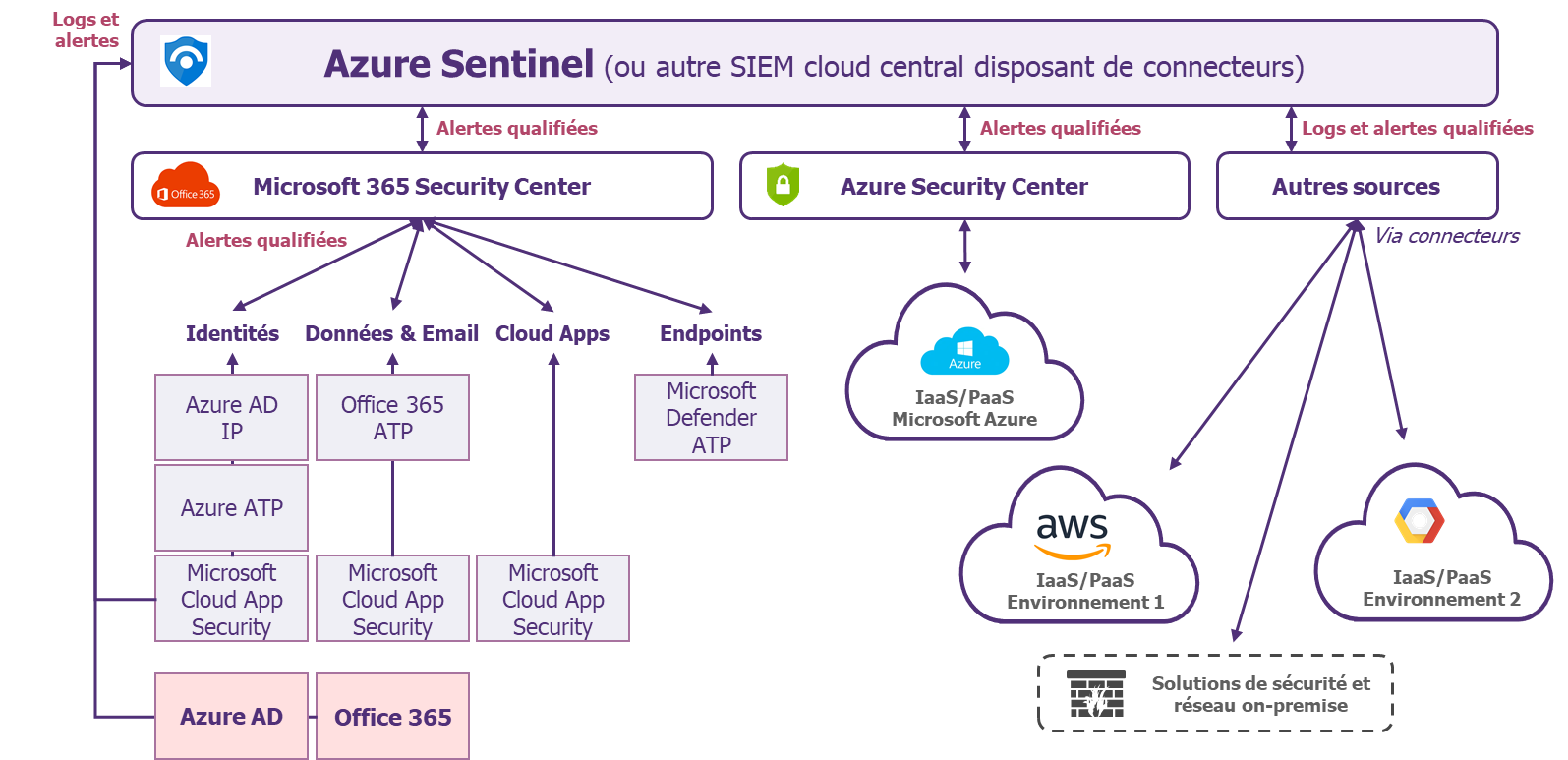
Un exemple d’architecture reprenant l’ensemble des recommandations de cet article est proposé ci-dessous, il utilise Azure Sentinel comme SIEM cloud central.
Synthèse : les principes clés à adopter pour garder la tête au-dessus des nuages
En résumé, l’équipe SOC souhaitant adapter sa stratégie de détection au multicloud devrait :
- Compléter son approche classique top-down par l’approche bottom-up, particulièrement adaptée au contexte complexe du multicloud,
- Utiliser dès que c’est possible les services natifs mis à disposition par les fournisseurs afin de tirer pleinement parti des avantages du cloud,
- Simplifier l’architecture de collecte et centraliser au maximum des alertes préanalysées par les services natifs cloud,
Une fois la tête sortie du nuage, la stratégie formalisée et l’architecture de collecte déployée, le SOC retrouve bien sa place de tour de contrôle du SI : la prolifération des services dans le cloud ne lui fait plus peur !
Les prochaines étapes peuvent consister à étudier les possibilités d’automatisation, avec la mise en place d’un SOAR, par exemple. Nous ne manquerons pas de discuter du sujet dans un prochain article.

