
Le Machine Learning est un sujet émergeant de ces dernières années et notamment dans le cadre de la surveillance cybersécurité. Cependant, comme évoqué dans l’article « Booster sa cybersécurité grâce à du Machine Learning » (Partie 1 & Partie 2), le développement de telles solutions nécessite de forts investissements humains et financiers.
En effet, toutes les entreprises n’ont pas les moyens nécessaires (ou la volonté) de développer en interne ce type de technologie et se tournent alors vers des solutions du marché en se confrontant à une problématique majeure : comment réussir à choisir et intégrer rapidement une solution efficace dans mon contexte ?
Pourquoi utiliser du Machine Learning en cybersécurité ?
Le caractère statique des solutions de détection actuelles (antivirus utilisant des bases de signatures, alertes seuils d’alerte dans un SIEM…) ne permet plus de faire face à des attaques de plus en plus nombreuses et variées. En outre, les équipes de sécurité sont surchargées par le volume de données à analyser.
Comme expliqué dans l’article « La saga de l’été sur les nouveaux outils du SOC » (Partie 2 & Partie 3), le Machine Learning permet de répondre à ces problématiques que rencontre le SOC en utilisant des méthodes d’analyse comportementale pour détecter des attaques avancées et prioriser les alertes à analyser.
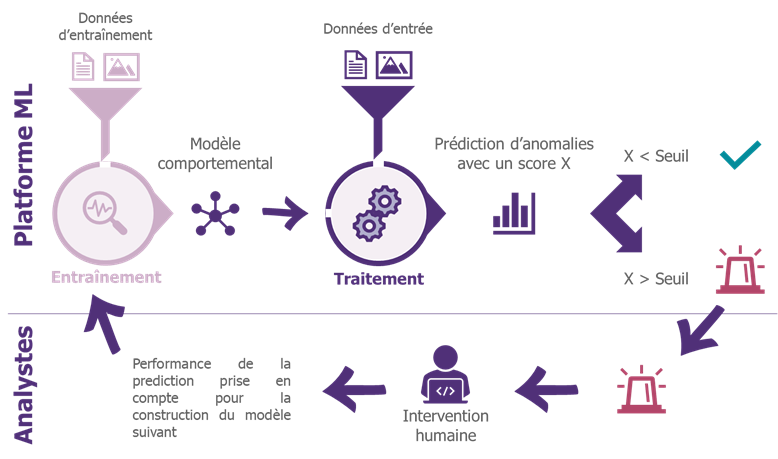
Principe de détection d’anomalies dans un SOC
Si ces types de solutions apportent une réelle plus-value, elles ne permettent pas de totalement s’affranchir des moyens de détection actuels et sont plutôt utilisées pour compléter les outils en place.
Par ailleurs, leur niveau de complexité (déploiement, traitement des alertes) requiert en prérequis d’avoir déjà atteint un niveau de maturité suffisant en termes de détection et réaction (organisation, outillage, ressources, centralisation de la donnée) avant qu’il soit pertinent de se lancer dans un projet basé sur du Machine Learning. La phase de cadrage n’en sera que facilitée et le déploiement accéléré.
En avance de phase : définir le cahier des charges
Quel est le cas d’usage que je souhaite adresser ?
Lors de nos différentes interventions chez nos clients, nous avons accompagné l’intégration de nombreuses solutions et nous pouvons faire ressortir quatre grands types de cas d’usages sur lesquels les entreprises investissent :
- La lutte contre la fraude: outils de détection de déviation(s) dans le(s) comportement(s) d’un utilisateur
- La surveillance des emails: outils de prévention contre le phishing ou la fuite d’informations (DLP)
- La détection de menaces sur le réseau: sondes « Next-Gen »
- L’identification des menaces sur les endpoints: anti-virus « Next-Gen »
Le choix d’une solution (et donc d’un cas d’usage) ne devra pas être défini de manière unilatérale par la filière SSI mais devra être réfléchi avec les différents acteurs concernés (SSI, DSI, métiers…). Cet échange permettra de préciser la cible ainsi que de valider les prérequis techniques et organisationnels (accessibilité des logs, ressources à mobiliser, taille des équipes…) pour préparer au mieux son intégration et son exploitation.
Quel type de solution choisir ?
Selon les outils déjà en place et en fonction du besoin, plusieurs solutions sont envisageables :
- Choisir d’implémenter une solution clé en main permettant de traiter des cas d’usages très précis et non spécifiques à des problématiques métiers (EDR, biométrie comportementale…). Ce choix convient généralement à un besoin immédiat plutôt qu’à une stratégie à long terme.
- Activer un module de Machine Learning sur un outil déjà en place (SIEM, puits de logs…) dans le but de pouvoir étendre son périmètre de détection. Ce choix permet notamment de pouvoir tester rapidement des cas d’usages et de s’affranchir des phases d’intégration d’un nouvel équipement au sein du son SI.
Enfin, il est essentiel de se rappeler qu’il n’existe pas de solution miracle et que chaque type de solution répond à des besoins précis.
Devant l’éditeur : challenger les points essentiels
Tester la solution et réfléchir à son évolutivité
Une fois que tous ces prérequis sont définis, il est d’usage de réaliser avec l’éditeur un Proof of Concept (PoC). Cependant, dans le cas spécifique d’une solution de Machine Learning, le PoC permettra de répondre à plusieurs interrogations spécifiques :
- Mes données actuellement collectées permettent-elles d’avoir des résultats rapidement satisfaisants ? Les solutions de Machine Learning requièrent l’analyse d’un très grand nombre de données potentiellement enrichies par des référentiels permettant de croiser plusieurs sources. Il est donc nécessaire de s’assurer en avance de phase avec l’éditeur que les données actuellement collectées permettent déjà d’obtenir des premiers résultats.
- Combien de temps la phase d’apprentissage durera-t-elle dans mon contexte ? Certaines solutions de Machine Learning produisent des résultats qu’à partir de plusieurs mois voire années car les phases d’apprentissages peuvent-être extrêmement longues du fait du contexte particulier à chaque entreprise. La possibilité d’utiliser un historique de logs pour les tests permettrait de s’affranchir d’une période d’apprentissage conséquente.
Des questions spécifiques seront également à traiter afin d’anticiper le plus long terme :
- Sera-t-il possible d’enrichir les analyses avec d’autres types de données ? Les solutions de Machine Learning permettent de pouvoir effectuer des analyses sur de nombreux types de données pouvant avoir des formats hétérogènes, il est donc nécessaire de pouvoir s’assurer que les analyses pourront être enrichies avec de nouveaux types de données collectées.
- Sera-t-il possible de mettre en place de nouveaux algorithmes de détection ? La possibilité de pouvoir personnaliser ces solutions en y ajoutant de nouveaux types d’algorithmes (et potentiellement de manière indépendante) est non négligeable.
- Comment suis-je assuré que mon éditeur soit toujours à la pointe de la technologie ? Au vu de l’évolution exponentielle des techniques sur ce sujet, il est important de s’assurer que l’éditeur poursuive sa course à l’avancée technologique afin de proposer de nouveaux moyens de défense contre des attaques qui ne cessent de se complexifier.
Se préparer à protéger le cycle de vie de la donnée
Les méthodes de détection basées sur de l’analyse comportementale nécessitent la collecte et le traitement de données sensibles/personnelles. Ainsi, particulièrement dans le cas où la solution est hébergée chez l’éditeur, les problématiques liées à l’usage des données devront être adressées au plus tôt. D’une part les exigences contractuelles de sécurité devront bien sûr être renforcées, et d’autre part il pourra être utile de faire appel en amont à des solutions permettant un traitement plus sécurisé du cycle de vie de la donnée.
Par exemple, des startups comme SARUS travaillent sur le masquage des données personnelles, permettant aux data scientists d’effectuer du Machine Learning sans accéder aux données sources. Des startups comme HAZY travaillent elles sur la génération de données synthétiques gardant la valeur statistique des données utiles, mais perdant leur caractère sensible. Ce type de solution permet également d’agrandir artificiellement l’échantillon fourni, et d’obtenir une quantité quasiment illimitée de données, ce qui peut être très utile dans le cadre d’un PoC où les données actuellement disponibles sont en quantité limitées.
Une fois que la pertinence de la solution est validée, la partie ne fait que commencer !
Au travers de nos différentes expériences, nous avons pu nous forger une conviction : le marché est assez mature pour fournir des résultats intéressants, notamment sur les quatre cas d’usages mentionnés ci-dessus. La mise en place de tels outils saura être efficace si les solutions sont connectées à un écosystème riche et qu’elles répondent à un besoin spécifique. En effet, la mise en place d’une même solution peut être une franche réussite ou un échec dans deux contextes différents. Le résultat dépendra notamment de la clarté du besoin, du périmètre visé, de l’expertise présente (Cybersécurité et Data Science), et encore de la disponibilité de la donnée (qualité et quantité).
Si le choix d’une solution de Machine Learning n’est pas simple, le meilleur moyen de se faire rapidement une idée est de réaliser un PoC pouvant être rapide et peu engageant : nous avons pu constater chez certains de nos clients que des solutions remontaient déjà des résultats intéressants après uniquement deux semaines de PoC.
Tout en gardant en tête que le PoC n’est que le début de l’aventure. Il résultera sur le lancement d’un projet de plusieurs mois passionnant (analyse de nouveaux types d’alertes, découvertes de nouvelles techniques…), apportant une réelle plus-value sécurité (détection de nouveaux évènements…), impulsant un nouveau souffle au sein des équipes opérationnelles de sécurité (priorisation des efforts, possibilité d’optimisation des tâches rébarbatives…).

