
Nous ouvrons désormais les contributions à ce blog aux start-ups accélérées par notre dispositif Shake’Up. Hazy est un générateur de données synthétiques, combinant confidentialité différentielle, et intégrité référentielle, proposant un support de base de données multi-tableaux et avec un déploiement possible sur des systèmes critiques.

Qu’ont en commun les organisations tenant le choc de la crise sanitaire ? Des plans d’urgence particulièrement efficaces.
Pour ces quelques cas de réussite, cette planification a commencé par la prise en compte de l’aspect RH. PDG et directeur technique, en totale collaboration, se sont demandé : et si un de nos employés tombait malade, qui serait le suivant ? Que se passerait-il si plusieurs acteurs clés de l’entreprise étaient hospitalisés en même temps ? Ces entreprises ont créé une base comprenant l’ensemble des fournisseurs d’accès à Internet et les régions associées, ils l’ont communiquée à tous les ingénieurs d’astreinte et ont créé une chaîne de remplacement en cas de panne. Ces organisations ont veillé à ce que non seulement leurs systèmes internes et ceux destinés aux clients soient sauvegardés, mais aussi ceux de leur chaîne logistique.
Mais certains diraient que tout cela est une réaction, et non une planification, ou simplement de la chance. Après tout, chaque organisation et chaque industrie a ses propres obstacles à surmonter. Comment une entreprise pourrait-elle vraiment se préparer à l’inconnu ?
Comment une organisation pourrait-elle se préparer à une pandémie mondiale s’il n’y en a pas eu de cette ampleur depuis une centaine d’années ?
C’est là que les données synthétiques offrent une opportunité intéressante d’espérer le meilleur, mais de se préparer au pire. Les données synthétiques – qui sont des données très précises mais anonymes, et totalement artificielles – peuvent permettre à toute organisation de simuler des événements imprévus comme des pandémies et des catastrophes naturelles.
Les données synthétiques peuvent permettre de définir des plans d’urgence, même pour les plus grands imprévus.
Qu’est-ce que les données synthétiques et comment sont-elles utilisées ?
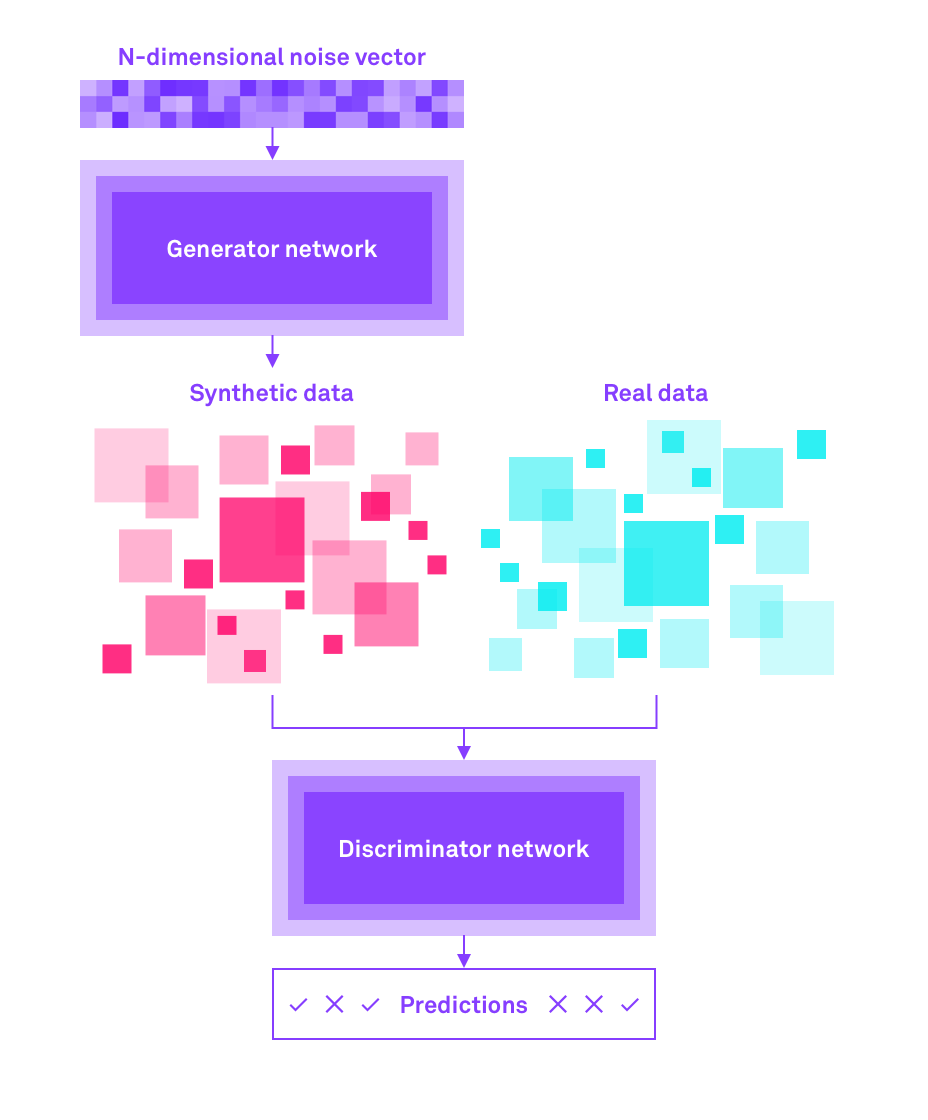
Comme leur nom l’indique, les données synthétiques sont totalement artificielles. Dans le cas de Hazy, les données synthétiques sont générées par des algorithmes de Machine Learning de pointe, qui offrent certaines garanties mathématiques d’utilité et de confidentialité. Cela est essentiel car aucune donnée sur les clients n’est réellement utilisée, alors que les courbes ou les modèles de leurs profils et comportements collectifs sont préservés.
C’est incroyablement utile pour faire tomber les barrières à l’innovation et aux essais. Cela permet d’obtenir toutes les informations nécessaires sur ses clients, leurs caractéristiques démographiques et leurs habitudes tout en réduisant considérablement le risque de réidentification. Il est ensuite possible de transférer facilement et en toute sécurité ces données synthétiques et ces informations entre différentes divisions, agences gouvernementales, entreprises et zones géographiques, avec la possibilité d’évaluer rapidement des partenaires tiers.
Comme les données synthétiques conservent à la fois leur valeur et leur conformité, leur potentiel est presque illimité. Elles peuvent être appliquées à la résolution de certains des plus grands problèmes du monde, de l’intensification de la recherche et du traçage des pandémies internationales à un accès plus équitable aux services bancaires, en passant par la détection de la fraude et du blanchiment d’argent à une échelle transfrontalière et inter-organisationnelle. Elle peut être utilisée pour faire tomber les frontières et optimiser la collaboration intergouvernementale, jusqu’à présent entravée par des bases de données divergentes coincées derrière des murs réglementaires.
Les données synthétiques permettent aux organisations et aux gouvernements de surmonter les barrières géographiques et les obstacles liés aux ressources.
Ces données synthétiques peuvent même être appliquées à des événements qui n’ont pas encore eu lieu.
Les principales organisations mondiales commencent à exploiter les données synthétiques pour élaborer des scénarios prédictifs afin de mieux répondre aux futures crises économiques, sanitaires, politiques et environnementales.
Il convient de noter que les données synthétiques ne sont pas aussi avancées et courantes que les autres outils d’entreprise. Comme chaque organisation possède des ensembles de données très complexes et variés, il faut les transformer, les pré-traiter et les configurer pour les rendre accessibles aux modèles de Machine Learning. Cela signifie que si n’importe qui dans une organisation peut bénéficier de données synthétiques, les data scientists doivent néanmoins être impliqués dans la préparation de ces données.
Des données synthétiques pour simuler des événements imprévus
Les données synthétiques sont créées par des modèles de Machine Learning qui, d’une certaine manière, peuvent être considérées comme des simulateurs du monde.
Les données synthétiques de Hazy sont déjà utilisées dans les grandes institutions financières pour permettre aux développeurs d’applications de simuler des modèles de comportement réalistes de clients avant même que l’application n’ait d’utilisateurs. Ce sont les ingénieurs en Machine Learning qui peuvent le mieux modéliser ce genre de scénarios de la demande future.
Nos clients les plus innovants commencent à étendre les cas d’utilisation de cette technologie d’avant-garde à des événements pour la plupart imprévisibles.
Cette possibilité n’a été rendue possible qu’assez récemment grâce à la génération de données synthétiques conditionnelles, qui permet d’explorer comment certaines relations dans un ensemble de données peuvent jouer avec d’autres relations lorsque leurs effets sont amplifiés ou diminués.
En ce moment, cela est d’une importance majeure, notamment lorsqu’on évoque le sujet des deepfakes. Quelqu’un pourrait demander à un générateur conditionnel de trouver des visages qui ont des cheveux roses, des lunettes et un piercing au nez. Maintenant, le générateur n’a peut-être jamais vu quelqu’un avec toutes ces caractéristiques combinées, mais il sait approximativement comment chacune de ces entités se combine logiquement à un niveau supérieur. Le modèle de Machine Learning a appris comment les entités de niveau inférieur se combinent pour construire des méta-entités – par exemple, il sait qu’un nez a une relation assez prévisible avec les yeux et la bouche. Cela permet au générateur de prendre ce qu’il sait et de combler avec précision les lacunes et de prédire à quoi ressembleraient ces punks rockers.
Cela fonctionne un peu différemment avec les données clients comme les données financières séquentielles, car ces tableaux comprennent souvent des milliers de colonnes et ont beaucoup de valeurs catégorielles – chaque colonne peut être considérée comme une dimension. Il est souvent plus difficile de déterminer comment les valeurs catégorielles d’un tableau s’imbriquent dans un ensemble de données que de travailler avec un ensemble de données composé des dimensions en pixels d’un ensemble de données de visages humains.
Le point positif est que les banques ont incontestablement beaucoup de données avec lesquelles travailler. Elles ont également souvent accès à des ensembles de données supplémentaires, comme les mesures des actions, les taux d’intérêt et les taux de change. Les interrelations entre les différents ensembles de données peuvent potentiellement être combinées pour mieux modéliser les relations et explorer des scénarios et des compromis. Grâce à ces modèles de Machine Learning, il est possible d’étudier le comportement d’un produit financier lorsque vous avez une combinaison de taux d’intérêt élevés et de faible chômage.
Bien que certains événements n’ont peut-être jamais eu lieu dans la vie réelle, les générateurs peuvent être utilisés pour extrapoler et remplir les blancs, puisqu’ils savent généralement comment certains événements évoluent ensemble.
Les compagnies d’assurance vivent dans le monde du « si cela, alors ceci », mais une grande partie de leurs prévisions actuarielles sont basées sur des données passées. Que pouvez-vous faire si vous n’avez pas de données parce que ces événements ne se sont pas encore produits ? Les données synthétiques sont un bon moyen de construire des scénarios prédictifs qui peuvent aider les organisations à évaluer correctement le risque d’événements imprévus.
Et cette boule de cristal ne doit pas seulement être appliquée aux événements qui changent le monde. Vous pouvez utiliser des générateurs de données synthétiques pour comprendre comment un nouveau marché réagirait à votre lancement d’un nouveau produit.
Supposons que vous ayez un million de clients au Royaume-Uni et seulement 50 000 en France. Et vous connaissez la variabilité des revenus, les zones géographiques dans lesquelles ils vivent, ainsi que l’âge, le revenu et le niveau d’éducation de chaque client. Vous créez d’abord des données synthétiques qui protègent toutes les informations personnelles identifiables dans deux régions géographiques distinctes. Le modèle apprend ensuite à la fois la manière prévisible dont le produit s’est vendu au Royaume-Uni et il connaît les différences de comportement entre les deux pays. Ce modèle peut même apprendre à extrapoler intelligemment le comportement des consommateurs britanniques au comportement des consommateurs français afin de prédire la meilleure façon dont une expansion sur le marché français pourrait se dérouler. Ces aperçus disparates se transforment en un solide prédicteur pour atteindre des objectifs d’expansion internationale.
Ces résultats peuvent à nouveau être combinés avec d’autres probabilités, comme la façon dont les clients ou les marchés locaux réagiront en fonction du nombre de points de chute de la bourse ou de l’impact des températures estivales sur les ventes. Toutefois, si l’on souhaite prédire des événements très rares ou une combinaison d’événements rares avec des données limitées, faire des prédictions reste très difficile sans disposer de suffisamment de données pour extrapoler de manière significative les tendances et les relations dans les données.
Le potentiel illimité des données synthétiques sécurisées
Les données synthétiques sont le meilleur moyen de débloquer en toute sécurité le potentiel de l’économie des données. Parce que les données synthétiques – en étant complètement artificielles – peuvent résoudre le problème essentiel de la vie privée, elles peuvent réduire considérablement les fuites de données et protéger les informations personnelles de vos clients, tout en conservant leur utilité.
Les données synthétiques deviennent le meilleur moyen pour les organisations multinationales de rester aussi compétitives, réactives et innovantes que les start-ups, car elles permettent de planifier l’avenir et ses capacités, en se basant sur l’inconnu.
Parce que les grandes institutions financières disposent d’une telle richesse de données, elles sont parfaitement positionnées pour tirer parti du potentiel unique des données et donc des données synthétiques. Les organisations peuvent désormais limiter la prise de risques en prévoyant des réponses pour un avenir imprévisible.
Le monde change rapidement. Votre entreprise doit être prête à y faire face.

