
Aujourd’hui, nous entendons parler de l’intelligence artificielle (IA) partout, elle touche tous les secteurs… et la cybersécurité n’est pas en reste ! Selon un benchmark mondial publié par CapGemini à l’été 2019, 69% des organisations considèrent qu’elles ne seront bientôt plus capables de répondre à une cyberattaque sans IA. Le Gartner place l’IA appliquée à la cybersécurité dans les 10 tendances technologiques stratégiques majeures de 2020.
Nous allons au travers de deux articles explorer les capacités de l’IA, en particulier celles du Machine Learning, pour la cybersécurité. Dans ce premier article, nous allons parcourir pas à pas les étapes d’un projet de Machine Learning focalisé sur un cas d’usage cybersécurité : l’exfiltration de données depuis le SI, sur un cas très simplifié. Nous en avons choisi un, mais les concepts de cet article sont applicables à tous les projets de Machine Learning et peuvent être transposés à tout autre cas d’usage, notamment cyber.
Avant toute chose, de quoi parle-t-on ?
Le terme d’Intelligence Artificielle (IA) regroupe toutes les techniques permettant aux machines de simuler l’intelligence. Aujourd’hui toutefois, lorsqu’on parle d’IA on parle très souvent de Machine Learning, l’un de ses sous-domaines. Il s’agit des techniques permettant aux machines d’apprendre une tâche, sans avoir été explicitement programmées pour.
Pour nous professionnels de la cybersécurité, cela tombe bien : nous avons bien souvent du mal à décrire explicitement ce que nous voulons détecter ! Le Machine Learning nous offre alors de nouvelles perspectives, avec déjà de nombreux cas d’application, dont les principaux sont illustrés ci-dessous:

L’exemple d’un cas d’usage pour la cybersécurité ML-augmenté : le DLP
Pour illustrer l’apport du Machine Learning à la cybersécurité, nous avons choisi de nous intéresser à l’extraction frauduleuse de données depuis le système d’information d’une entreprise. Autrement dit, le cas du DLP (Data Leakage Prevention), problématique rencontrée par un grand nombre d’entreprises. Nous souhaitons détecter les communications suspectes vers l’extérieur afin de pouvoir les empêcher.
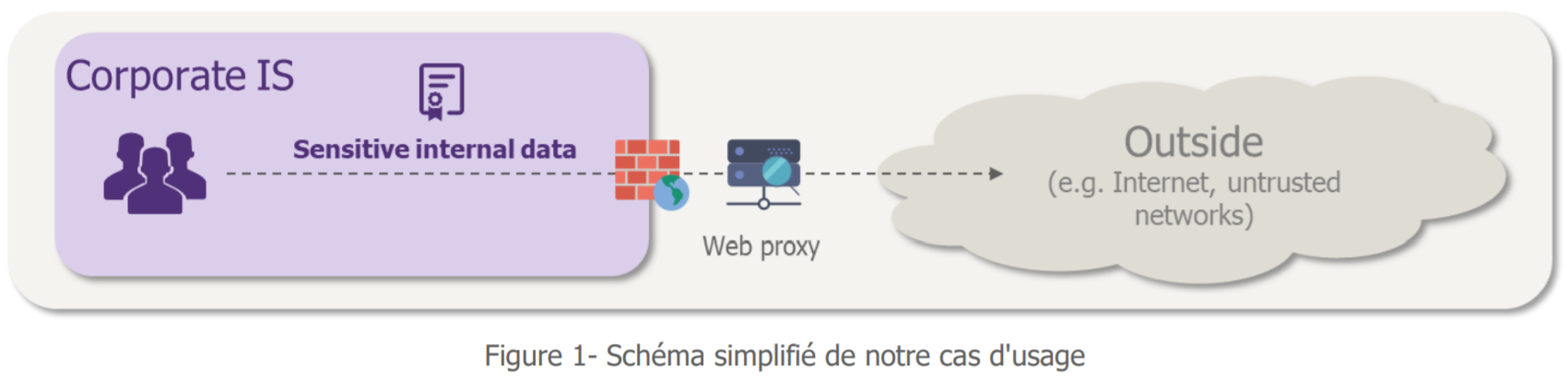
« Très bien mais… comment caractériser une communication suspecte ? »
Par des volumes échangés importants ? Par une destination étrange ? Par une heure de connexion inhabituelle ?
En réalité, notre problème est complexe à expliciter et ce que nous devons évaluer a de fortes chances d’évoluer dans le temps. C’est pourquoi, en utilisant uniquement des règles de détection statiques, nos équipes sécurité ont du mal à être exhaustives. Elles peuvent jouer sur les seuils de ces règles pour affiner les éléments détectés, mais se retrouvent malheureusement encore avec un nombre important de faux positifs à traiter.
On comprend que le Machine Learning tel que nous l’avons défini précédemment peut nous être utile ici. Et si on essayait ?
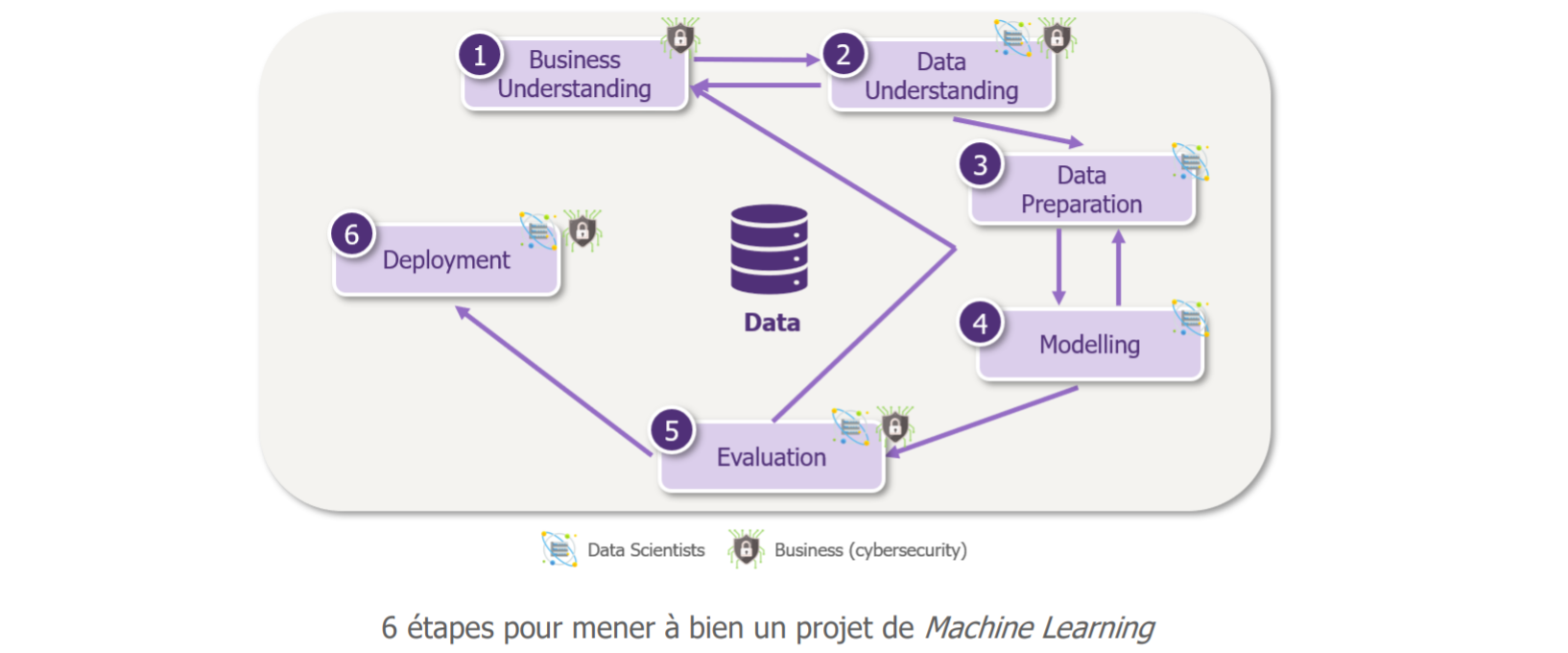
Etape 1 : Clarifier le besoin
C’est ce que nous venons de faire !
Etape 2 : Choisir les données
Quand on entend les mots Machine Learning, il faut généralement comprendre « données » pour alimenter les algorithmes. Beaucoup de données, et de qualité !
En demandant où aller chercher des données utiles pour notre cas d’exfiltration des données à notre métier demandeur (qui pour une fois est la cybersécurité !), le proxy web ressort comme grand gagnant : il voit passer quasiment tout le trafic sortant du SI. Nous récupérons donc ses logs, ils ressemblent à ça.
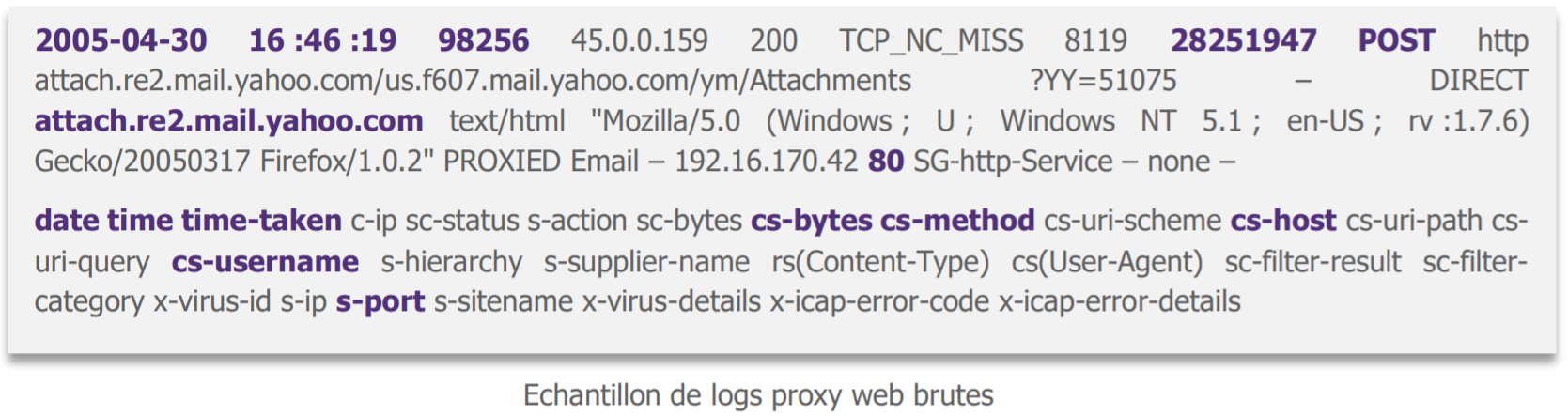
« Ca m’a l’air bien compliqué tout ça… »
Les data scientists ont en effet de quoi être perdus : d’une part l’ensemble est peu digeste, de l’autre, après consultation du métier-cybersécurité, tous les champs ne sont pas vraiment utiles pour notre cas d’usage. Nous en sélectionnons donc quelques-uns avec lui avant de poursuivre.

Le résultat est plus exploitable par les data scientists !
Etape 3 : préparer les données
Les data scientists peuvent maintenant « explorer les données » afin de garantir un apprentissage optimal de l’algorithme. Ici, ils nous remontent un élément surprenant dans la répartition de nos requêtes suivant leur volume d’upload. Puisqu’on souhaite détecter des exfiltrations de données, cette variable nous intéresse en effet particulièrement.
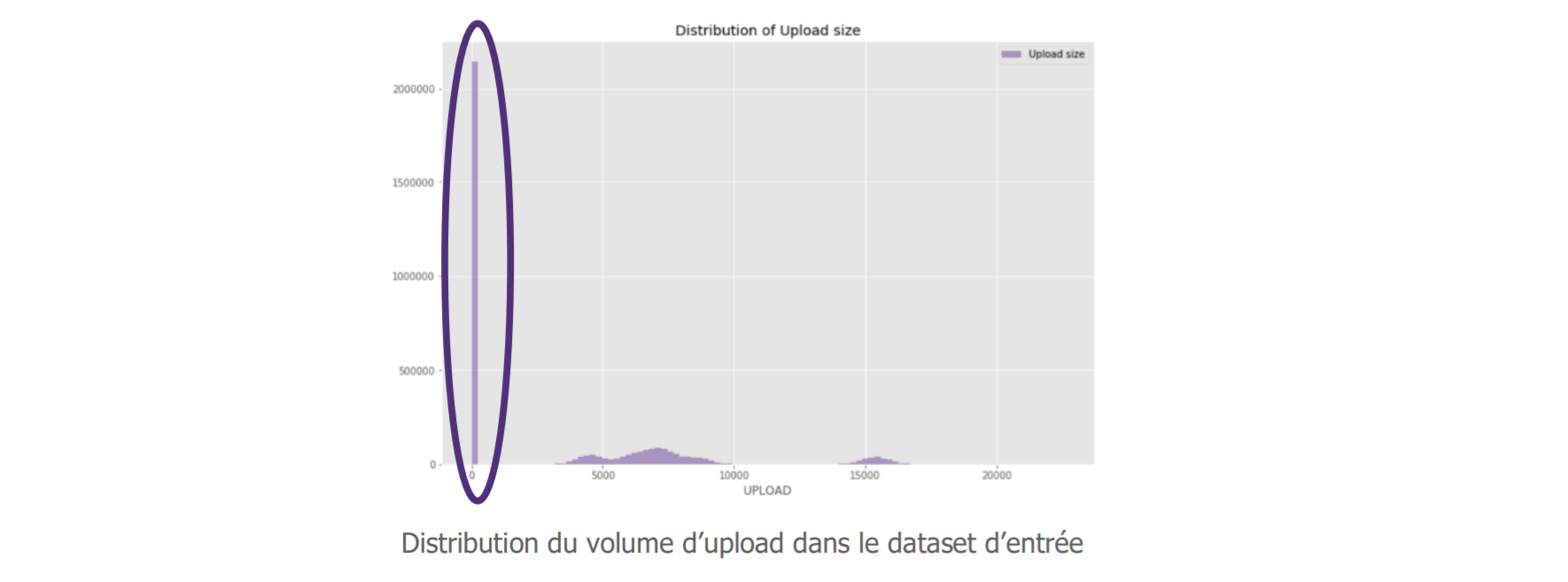
La valeur de notre variable n’est pas distribuée, nous avons même un très fort volume à 0.
« Mais, elles sont quand même nombreuses ces requêtes avec un volume d’upload nul, est-ce que c’est vraiment pertinent de les garder dans notre cas ? ».
Effectivement, après discussion avec le métier-cybersécurité, il ressort que ces données n’apportent pas grand-chose pour notre cas d’usage. Nous décidons donc de les retirer, notre jeu est alors distribué comme suit :
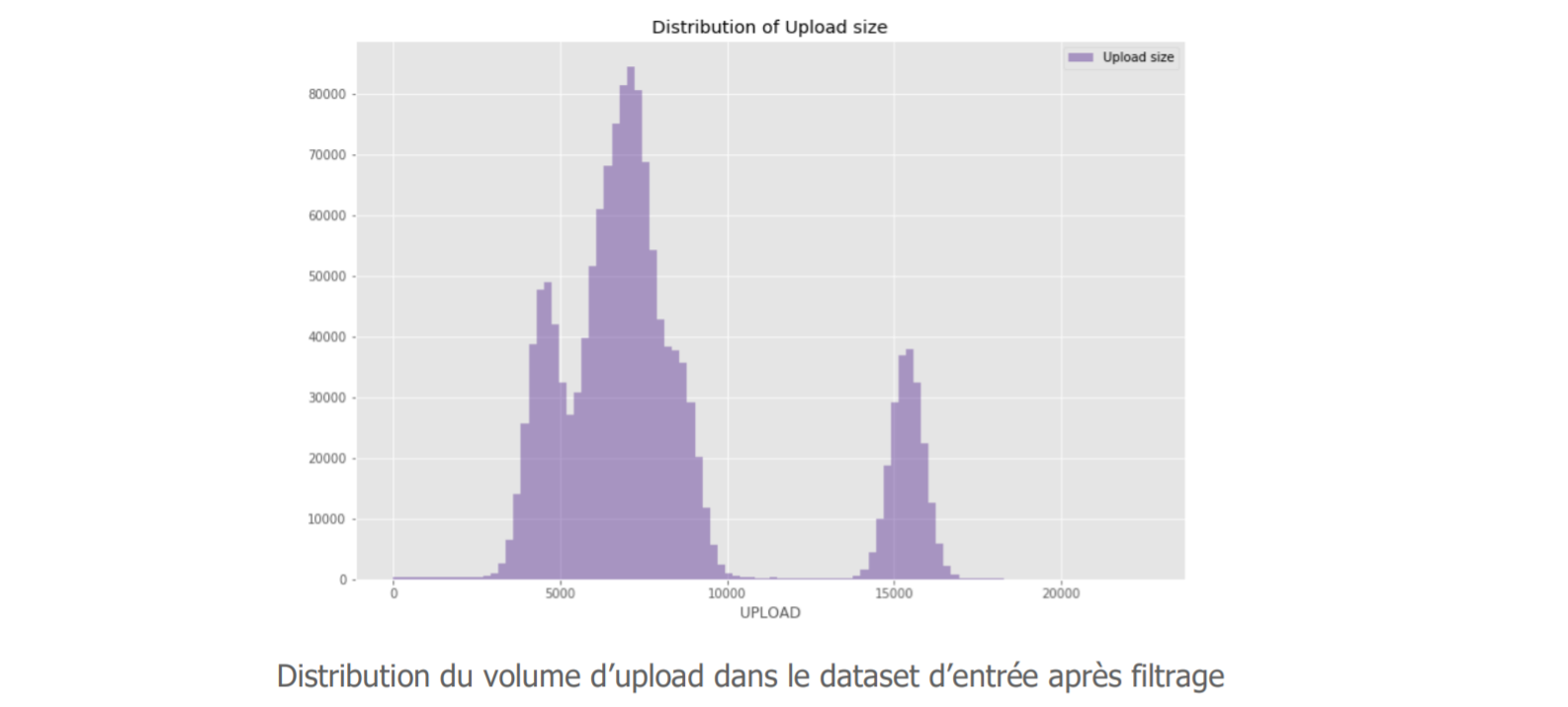
Après plusieurs allers-retours entre les data scientists challengeant les données avec un point de vue statistique et les équipes cybersécurité répondant avec leur œil métier, les données sont simplifiées au maximum. Elles sont ensuite :
- Enrichies en créant de nouvelles variables plus denses en information utile. Nous avons introduit un volume d’upload relatif vers chaque site, mesurant l’écart entre le volume d’upload d’une requête et sa valeur moyenne observée sur les 90 derniers jours. Nous pourrions également ajouter la durée de connexion par exemple.
- Normalisées en réduisant l’amplitude de chaque variable pour diminuer une sur ou sous-pondération de certaines variables.
- Numérisées, la plupart des algorithmes ne pouvant interpréter que des variables numériques.
Nous pouvons maintenant séparer notre jeu de données en deux : un jeu allant servir à l’entraînement de notre modèle, un jeu qui nous permettra de tester sa performance. Plusieurs méthodes de séparation existent, permettant de conserver certaines caractéristiques des données (e.g. la saisonnalité), mais l’objectif reste le même : garantir une mesure d’évaluation au plus proche des performances réelles du modèle, en présentant au modèle des données qu’il n’a pas eu a disposition durant l’entraînement.
Etape 4 : Choisir la méthode d’apprentissage et entrainer le modèle
Certains algorithmes sont plus performants que d’autres pour une problématique donnée, il convient donc de faire un choix raisonné.
Il existe deux principales catégories d’algorithmes de Machine Learning :
- Supervisés, lorsque l’on a des données labelisées comme référence à donner en exemple à notre algorithme. Ces algorithmes sont par exemple utilisés en cybersécurité par les solutions anti-spam : ils peuvent apprendre via la classification des emails comme spam par les utilisateurs par exemple.
- Non supervisés, lorsque l’on ne sait pas précisément ce qu’on souhaite détecter ou que l’on manque d’exemples à fournir à l’algorithme pour son apprentissage (i.e. nous manquons données labélisées).
Comme expliqué plus haut, le contexte de notre cas d’usage nous oriente plutôt vers la deuxième option. C’est d’ailleurs pour les mêmes raisons que nous avions initialement pensé au Machine Learning. Nous choisissons ensuite notre algorithme d’apprentissage non supervisé (Isolation Forest ici, mais nous aurions pu en choisir un autre) et entrainons notre modèle.
Etape 5 : Analyser les résultats
Nous utilisons notre jeu de données de test pour évaluer l’efficacité de notre modèle pour détecter les cas d’exfiltration.
Le modèle conçu permet de détecter des patterns dans les données (requêtes), pour ensuite comparer les nouvelles données (requêtes) avec ces patterns et mettre en lumière celles qui s’éloignent de ce qu’il considère comme la norme de par son apprentissage (score d’anomalie).
Voici nos résultats :
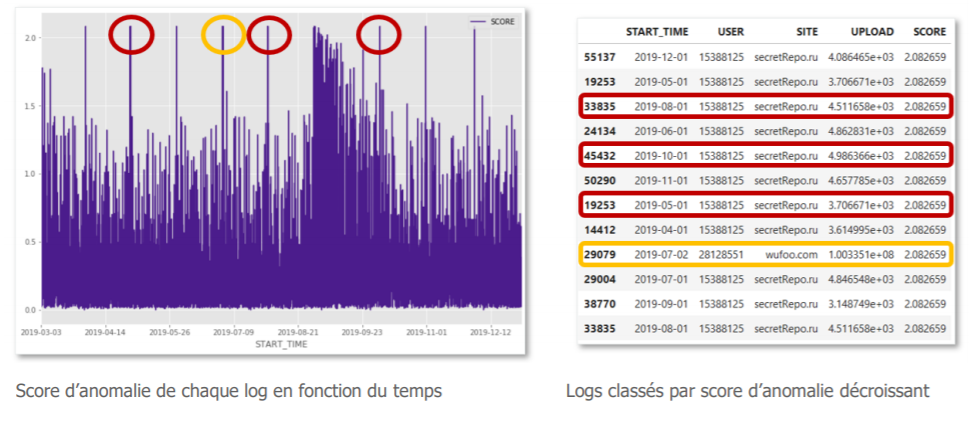
« Ok, mais comment j’interprète tout ça ? »
Le graphique à gauche représente les scores d’anomalie associés à chaque requête du jeu de test, triés par ordre chronologique. A droite se trouvent les logs présentant les scores d’anomalie les plus importants.
Après investigation avec le métier-cybersécurité :
- Le pic en jaune, correspond à un upload de volume beaucoup plus important que les autres, d’un utilisateur qui extrait un large volume de données. Cette anomalie est légitime. Toutefois, une alerte sur la base d’une règle statique sur le volume par requête aurait également permis de détecter cette communication suspecte.
- Plus intéressant maintenant, les pics en rouge, correspondent à des requêtes de faibles volumes d’upload régulières vers des sites inconnus depuis le même utilisateur. Ces anomalies sont plus difficiles à détecter avec des moyens classiques, pourtant notre algorithme leur a attribué le même score d’anomalie que pour un large volume. Elles deviennent donc tout aussi prioritaires à qualifier pour nos équipes de gestion des alertes de cybersécurité.
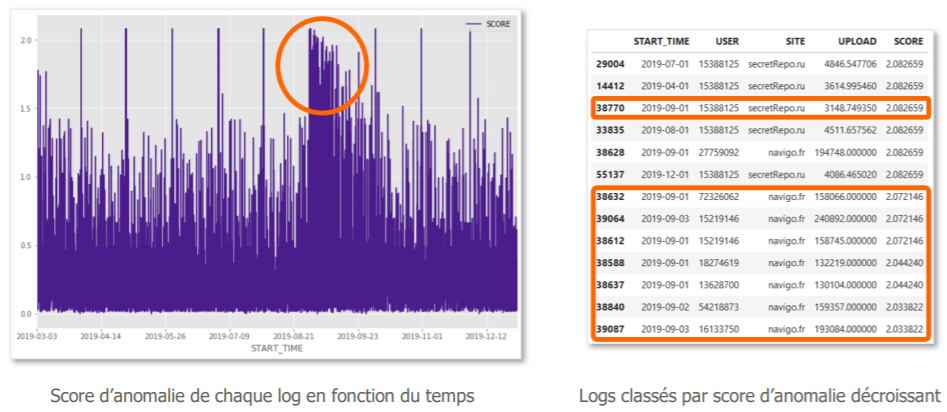
Maintenant, focalisons-nous sur le large paquet au centre du graphique (en orange). Le premier jour, on observe un score d’anomalie important, il s’agit d’un envoi soudain de données par de nombreux utilisateurs vers le site web de transport en commun de la ville. Après investigation on se rend compte qu’il ne s’agit pas d’un vrai incident de sécurité, mais de l’envoi annuel de justificatifs pour poursuite des abonnements de transport (nous sommes début septembre…). On observe par la suite que l’algorithme « comprend » que ces flux reviennent chez plusieurs utilisateurs et les intègre progressivement comme une habitude. Le score de risques décroit donc jour après jour.
Le modèle détecte donc ce qui sort de la norme, quelle que soit la norme et s’autocorrige avec l’expérience. C’est en cela que le Machine Learning tient une vraie valeur ajoutée par rapport aux méthodes classiques de détection.
Si la performance du modèle sur ce premier cas d’usage simplifié permet d’attester de la valeur potentielle du Machine Learning, il peut être temps de passer à l’étape 6 – le déploiement à l’échelle !
Dans un second article nous reviendrons sur ces étapes pour mettre en lumière les facteurs de réussite et pièges à éviter lorsqu’on souhaite étudier les possibilités du Machine Learning en cybersécurité.

